この記事はリクルートライフスタイル Advent Calendar 2016の6日目の記事です。
データエンジニアリンググループ・素人イケメン機械学習エンジニアの@_stakayaです。
主にデータ分析や機械学習を活用し、まだここにない出会いを求めて日々🍻充しながらドラムを叩いています。
はじめに
弊グループでは、Capture EveryThingの略称である「CET」というプロジェクトを行っており(以下、CETと呼称)、サービス改善によるユーザ体験の向上や高付加価値の提供、およびそれによるCVR向上を目的とし、各種ログやトランザクションデータの収集、また収集したデータを徹底活用したデータ分析・機械学習の実施、およびそれら収集したデータを基にしたアプリケーション開発を行っています。
CET内では大まかに
- 何のデータを新規に収集・集約し、どうビジネスに活かすかを考えるデータプランナー
- ビッグデータの収集を行うための基盤を構築・運用するインフラエンジニア(2日目担当のmia_0032氏など)
- 収集されたデータを分析する機械学習エンジニア/データサイエンティスト(25日目担当のawesome-tomomoto氏など)
- 分析されたモデルや収集されたデータに関わる実装を行うアプリケーションエンジニア(10日目担当のtecheten氏など)
という職種の方々が活躍しており、私は主に3, 4の役割を担当しています。
CET自体は”エンジニア・ファースト”を掲げたエンジニア色が非常に強いプロジェクトであり、データサイエンティストと呼称されるような職種であっても、プロダクション運用されるコードをガンガン書きますし、簡単なバッチ処理くらいであれば、インフラ・アプリケーションエンジニアの同僚が作ってくれたCI環境・バッチ管理基盤をフルに活用し、自分たちで構築・運用してしまいます。
そこでこの記事では、CETにおいて、データ分析・機械学習系のバッチが機械学習エンジニア/データサイエンティストの手によってどのように開発・運用されているかについて紹介します。
GCP(Google Cloud Platform)を活用した機械学習バッチ運用環境
一昔前1だと、不具合が出た際や、コードを最新のものにする際には、バッチ処理マシン自体にSSHでログインして手動で設定するなどなど手の温もり溢れる運用だったのですが、いい加減面倒になったため、大規模なリファクタリングをしようと考えていました。
現在の弊チームでの機械学習バッチ運用の姿を図で表したものが下図になります。
CETとしての方針もあり、大部分の機能をGCP(Google Cloud Platform)に寄せており、AWSは、データソースとしてのRedShift、外部協働者へのデータ提供手段としてのS3、イベントトリガー or 定期実行での処理結果監視担当のLambdaくらいの活用に留まっています。
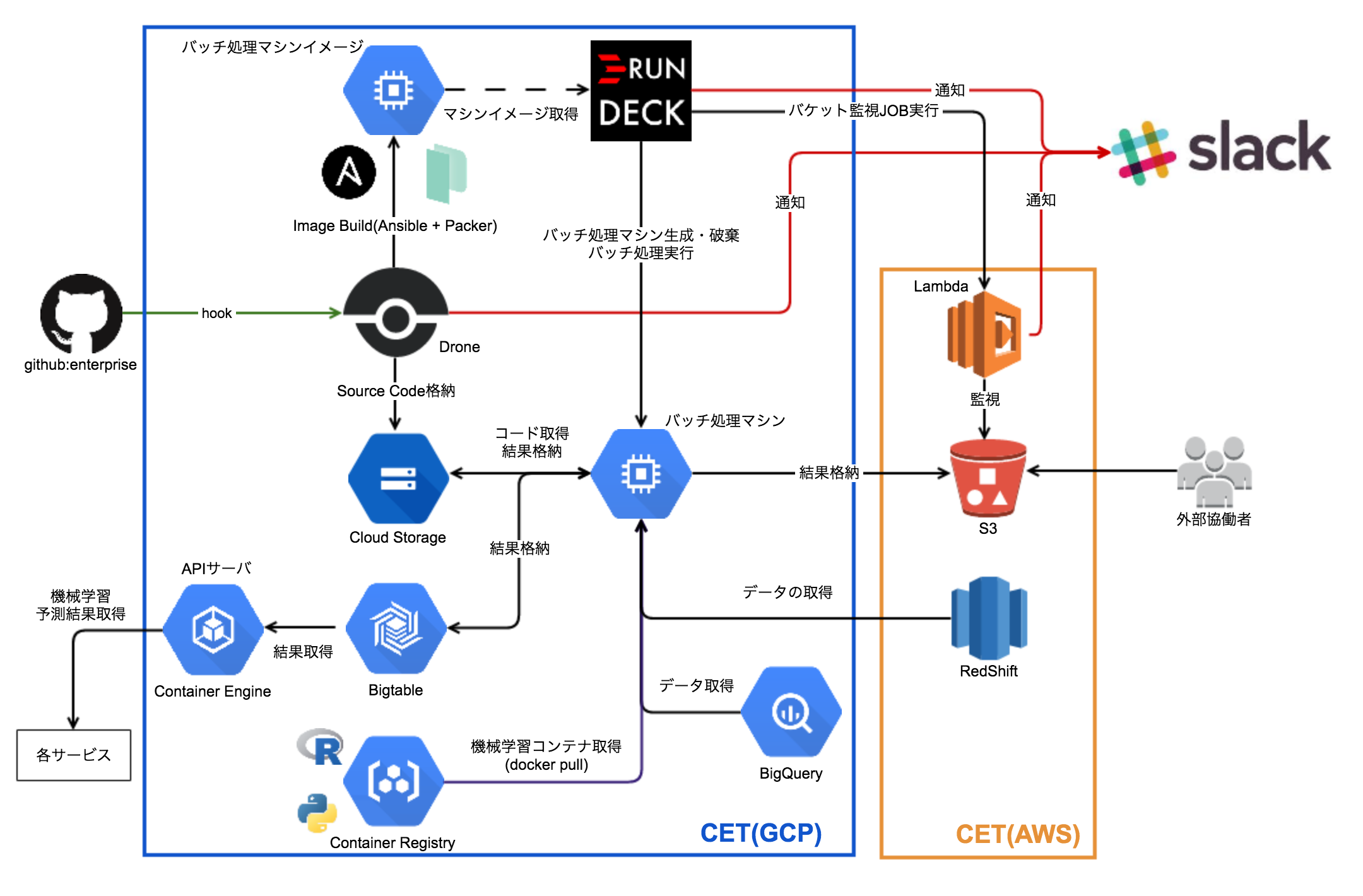
以下、この図となるべく対応するように、CETではどのように機械学習バッチを運用しているのかを説明していきます2。
バッチ処理マシンイメージの作成
データ分析・機械学習用のバッチ処理マシンイメージを作っており、実際のバッチ処理の際にはそのイメージに基づいたバッチ処理マシンを動的に生成し、バッチ処理を実行しています。バッチ処理マシンイメージは
- Ansibleを用いて、バッチ処理マシンイメージのコードを書く
- コードを社内のGithubにPushしたタイミングでCI環境(Drone, OSS版)が自動でビルド&テスト実行
- テストにパスした段階でコードをMasterにマージし、ステージング環境で再チェック
- 問題なさそうであれば、タグを打つ
- タグがPushされた段階で、以下の処理がDroneにより自動実行される
0. PackerとAnsibleを用い、マシンイメージを生成
0. 生成されたマシンイメージをCompute Engineに保存
という手順で生成されます。また、Droneが担当した作業については基本的にSlackに通知を飛ばすようにしています。
バッチ処理マシンイメージではBigqueryやRedShift、S3などのデータリソースへのアクセスのみが担保されているように設計されており、RやPythonでの実際の機械学習計算の際には別途作成しておいた機械学習用のDockerコンテナを用いて計算させるような設計にしています。このDockerコンテナはContainer Registryに格納しており、必要に応じてバッチ処理マシンにdocker pullされます。これはよくありがちな”俺の手元での計算結果とバッチ処理サーバでの計算結果が違う!”問題を避けるためです3。
バッチ処理コードの管理
データ分析・機械学習用のバッチ処理コードも基本的にはGithub上で管理していますが、Github Enterpriseで運用している都合上、定期的にメンテナンスがはいるため、本番で実行されるコードは全てCloud Storageにも保存するようにしています。ここでもDroneが活躍しています。
具体的には以下のような手順になります。
- コードを書いてGithubにPushする
- Droneで動作するテストにパスし、問題がないならMasterにマージ
- リリースしたいタイミングでタグを打つ
- タグがPushされたタイミングで、Droneにより、該当するタグのコードがCloud Storage上にアップロードされる
ここでタグを打たれてGoogle Storageに保存されたコードが実際のバッチ運用で使用されるコードになります。
バッチの作成・管理
さてこれで、バッチ処理マシンイメージとそのコードの準備ができましたので、実際にバッチ処理としてまとめ上げていきます。バッチ処理自体の作成・管理にはRundeckを用いており、下記の内容についても全てRundeck上のJOBとして記載しています。Rundeck自体は機械学習バッチ専用に設けているわけではなく、他の用途にも使用されています。
Rundeck上で動いている処理なのか、バッチ処理マシン上で動いている処理なのかわかりにくいため、その辺も明示して手順を記載すると
- Rundeckから、作成しておいた機械学習バッチ処理マシンイメージを用いて、適切な大きさのインスタンスを生成する
- バッチ処理マシン上に、Container RegistryからR・PythonなどのDockerコンテナを必要に応じて取得する
- バッチ処理マシン上に、処理に必要なコードをGoogle Storageから取得する
- バッチ処理マシン上で、バッチ処理を実行し、計算結果をGoogle StorageやS3、Bigtableなどに格納する
- Rundeckから、バッチ処理マシンを破棄する
という手順になります。これで、バッチ処理をする度にマシンの生成・破棄を行うことで余計なバッチ処理マシンが常に動いていることなく、限りなく面倒を見る必要のあるサーバのない機械学習バッチ運用が可能となりました。
また、各所に格納された計算結果は、APIサーバを通して各サービスに展開されたり、またS3に出力されて外部の協働者の方々に使用して頂くということも多々あります。また、結果の中には"学習済みの機械学習モデル"も含まれ、この学習済みモデルはまた他のデータ分析・機械学習バッチ処理の際に活用されるというケースもあります。
まとめと今後
本記事ではCETプロジェクトにおいて、どのように機械学習系のバッチ処理が運用されているのかについて説明しました。
このままでも結構快適なのですが、意外とRundeckでのJOBの記述や管理が冗長になってきているため、そこをいかに改良していこうかと、(私ではなく主に)インフラエンジニアの同僚がDigdagやAirFlow、また、先週話題になったAWS Batchなども含めて、今後のバッチ管理システムをどのように改善していくべきか検討を開始してくれています4。
来年のアドベントカレンダーやリクルートライフスタイルのテックブログなどで、この辺の話をする際には、またガラっと変化があるような予感がしております。
この記事が皆さんの何かお役に経てば幸いです。
-
といっても一年も経っていないですが…
そのタイミングで丁度、グループでのリファクタリング祭り(開発合宿)が開催されたため、これはいい機会だとバッチ運用環境を大幅に改善しはじめ、インフラ・アプリケーションエンジニアの同僚が作ってくれたCI環境・バッチ管理基盤を活用し、現在では大分その姿を変えることができました。 ↩ -
ここで言及するバッチ処理はリアルタイム/ストリーミングな処理ではなく、所謂、一日に数回程度しか動かさないバッチ処理を想定しています ↩
-
・・・という理由に加えて、流行りモノであるDockerやコンテナに手を出したかったという想いもあります ↩
-
この領域も日進月歩なので、あっという間にまた変わりそう&システム構成図を書き直す手間が増えるといえば増えるのですが私は日々の生活をより楽にする方に賭けたい… ↩