前回 TensorFlowによる将棋ソフトの開発日誌(ゆっけさんの場合) #5
目次 TensorFlow将棋ソフト開発日誌 目次
今回
-
tf.RandomShuffleQueueを利用してデータ読み込みの非同期化をした - さらに読み込みを並列化した
- Tensorflowのドキュメントが間違っていてハマった
- 学習中のミニバッチに対する勝敗予測を可視化した
なぜデータ読み込み非同期化をするのか
今まで学習サンプルはだいたい以下の疑似コードのような同期的な読み込みをしていました。
# 学習ループ
for i in range(10000):
# あらかじめ読んでおいた文字列をCPUでパースする
data = parse_line(lines[i])
# GPUで学習
summary, _ = sess.run((summary_op, train_op), feed_dict={sample=data,...})
# ログを出力する
summary_writer.add_summary(summary, i)
これだとイテレーションのたびにCPUでのパース処理でブロックされ折角のGPU(GTX 1080!!!)が活かしきれません。実際いままでの実験中はnvidia-smiコマンドで表示されるGPU利用率は0%から100%を行ったり来たりしていました。感覚的には50%いってれば良い方でしょうか。
ではあらかじめデータをすべてパースしておけば良いか。それでは実験を開始するたびに全データのパースを待たなければならず作業効率が落ちます。ではもっと読み込みに時間がかからない形式であらかじめ保存しておくべきか。可能ならそうすべきですがデータ形式自体まだ固まっていないためちょっとやる気が出ない。
答えはGPUが作業をしている間に裏でCPUを使ってデータを読み込む非同期処理です。
鍵は tf.RandomShuffleQueue / concurrent.futures.ProcessQueueRunner
かなりややこしいので実際のコードを示します。ginkgo/shogi_loader.py
import numpy_shogi
import shogi_records as sr
import tensorflow as tf
import numpy as np
from threading import Thread
from queue import Queue
import math
from concurrent.futures import ProcessPoolExecutor as Executor
# 文字列のタプルからデータを作成する関数です。
# ファイル各行をスプリットしたデータを受け取ったら行列のタプルを返すと把握してください。
def record_to_vec(r):
sfen, side, turn, total, move, winner = r
board_vec = numpy_shogi.sfen_to_vector(sfen, usi=move)
match_vec = np.array([
1.0 if side == winner else 0.0,
1.0 if side != winner else 0.0])
weight_vec = np.array([math.sqrt(float(turn)/float(total))])
return (np.squeeze(board_vec, axis=0), match_vec, weight_vec)
# 別プロセスで実行される関数です。スレッドプールのmap()経由で実行されます。
# record_to_vec()で作った行列を条件ではじいたりバッチ形式にしたりします。
def map_func(r):
sfen, side, turn, total, move, winner = r = sr.to_data(r)
if side != 'b': return None
if int(turn) < 30: return None
board_vec, label_vec, weight_vec = record_to_vec(r)
return (
np.expand_dims(board_vec,0),
np.expand_dims(label_vec,0),
np.expand_dims(weight_vec,0))
# データの非同期読み込みのスレッド関数です。
# 外部から止められるまでループを実行し続けます。
def load_loop(coord, sess, enqueue_op, path_q, pool,
input_vector_ph, label_ph, turn_weight_ph):
# coord = tf.Coordinator
# スレッドの調停をします。詳しくは公式のHowToを参照してください。
while not coord.should_stop():
try:
# path_q = queue.Queue()
# Python標準のキューです
# 複数のスレッドでファイルのリストを共有して既読を管理する必要があるため導入します
path = path_q.get()
# ファイルを全行読みます
records = sr.load_file(path)
# pool = ProcessPoolExecutor()
# いわゆるスレッドプールです
# なぜスレッドではなくプロセスなのかはEffectivePythonを読むと良いです
# pool.map() で与えられたリスト(シーケンス)に対して並列に関数を適用できます
# ここでは読み込んだ文字列リストを行列データに変換しています
data_list = list(pool.map(map_func, records))
# 変換エラーはNoneで返しているのでそれを取り除きます
data_list = list(filter(lambda x: x is not None, data_list))
# ここまででtuple(サンプル、ラベル、ウェイト)のlistが得られますが
# tfに投入するためlist(サンプル)、list(ラベル)、list(ウェイト)に変形します
vecs = [list(t) for t in zip(*data_list)]
vecs = list(map(np.concatenate, vecs))
# なんか時々わからないデータが得られるのでワークアラウンド
if len(vecs) != 3:
print('some error occured in reading file. skip this file: {}'.format(path))
continue
# tfのキューに投入するためにエンキューオペレーションをrunします
sess.run(enqueue_op, feed_dict={
input_vector_ph: vecs[0],
label_ph: vecs[1],
turn_weight_ph: vecs[2]})
# とりあえず無限に読み込むためファイルパスキューにファイルパスを戻します
path_q.put(path)
# これをぐるぐる繰り返すスレッドです
except tf.errors.AbortedError as e:
print(e)
break
except tf.errors.CancelledError as e:
print(e)
break
# ファイルのリストからデータを読み込むスレッドを生成する関数です
# この関数から上記スレッドを生成します
def load_sfenx_threads_and_queue(
coord, sess, path_list, batch_size, threads_num=1):
# おなじみのプレースホルダです
# このプレースホルダは学習モデルとは直接の関係はなく
# tf.RandomShuffleQueueにデータを投入するというオペレーションのためのものです
input_vector_ph = tf.placeholder(tf.float32, [None,9,9,148])
label_ph = tf.placeholder(tf.float32, [None,2])
turn_weight_ph = tf.placeholder(tf.float32, [None,1])
# tf.RandomShuffleQueue はtfに幾つかあるキューの一つです
# エンキューされたデータを指定の必要量(min_after_dequeue、ここでは8000)までバッファします
# その後もデキューされなければ最大量(ここでは50000)までエンキューできます
# デキューする際はキューにあるデータをランダムに選び出します
# 入力する際は順序性、規則性、冗長性が発生してしまうけどバッチ学習のためにシャッフルしたい時に便利です
# 入力段階で十分にランダムであるならばtf.FIFOQueueを使えば良いです
q = tf.RandomShuffleQueue(50000, 8000,
[tf.float32, tf.float32, tf.float32], [[9,9,148], [2], [1]])
# RandomShuffleQueueにエンキューするというtfのオペレーションを作ります
# オペレーションなので sess.run(...) する必要があります
enqueue_op = q.enqueue_many(
[input_vector_ph, label_ph, turn_weight_ph])
# 各スレッドでファイルパスリストを共有するためのキューです
# こちらはPython標準
path_q = Queue()
for p in path_list:
path_q.put(p)
# 並列実行するためにスレッドプールを作ります
# スレッドプールと言いつつ実装はサブプロセスです
# 別スレッドで共有していますが仕様上共有して良いのかは知らない
pool = Executor(max_workers=threads_num+2)
# 読み込みスレッドを作ります
# tfのドキュメントだとこれだけで並列実行できるかのように書いてありますが
# Pythonのthreading.Threadはマルチコアをうまく利用できません
# マルチコアで並列実行するには上記スレッドプールが必要です
# 詳しくはEffectivePythonを読んでください
threads = [Thread(target=load_loop,
args=(coord, sess, enqueue_op, path_q, pool,
input_vector_ph, label_ph, turn_weight_ph))
for i in range(threads_num)]
# サンプル、ラベル、ウェイトのそれぞれのバッチを作ります
# これらのノードはデキューオペレーションに紐付いています
# これらを使って学習するモデルの入力にすればモデルについて sess.run() するときに
# 自動的にデキューオペレーションが評価されます
input_batch, label_batch, turn_weight_batch = q.dequeue_many(batch_size)
# ついでにキューに積まれているデータの量をログ取りしておきます
# tf標準のQueueRunnerで画像読み込みをする時に出るログと似た感じです
tf.scalar_summary('shogi_loader/size', q.size())
return threads, input_batch, label_batch, turn_weight_batch
以上。めんどい。かいつまんで言うと以下になります。
-
tf.RandomShuffleQueueのエンキューオペレーションをsess.run()するスレッドを作る - そこでプレースホルダ経由で任意のデータをエンキューする
- デキューオペレーションからの出力のノード(上で言うサンプルとか)を確保しておく
- 確保したノードをモデルで使う
- モデルを評価すると依存が辿られてデキューオペレーションが自動で実行されモデルにデータが投入される
学習中のキューのサイズの増加のグラフが以下です。学習中に非同期で読み込みデータを増やしながら最大値で読み込みを一旦止めます。以後最大値を維持するのに必要なだけの読み込み処理を継続します。
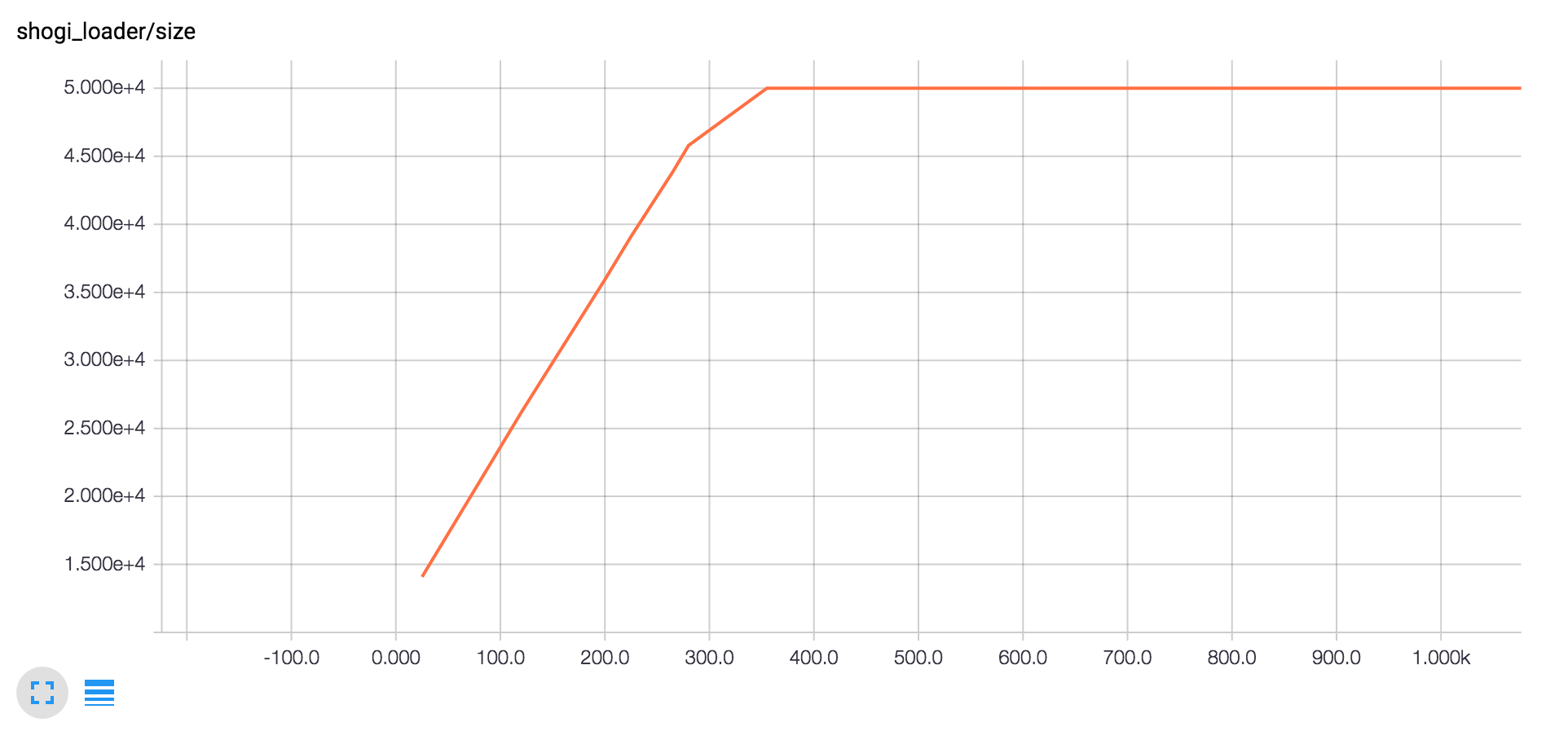
ここで読み込みが学習に追いついていない場合はグラフが底辺に張り付き続けます。学習の sess.run((train), ...) はデータがエンキューされるのを待つため(使用しているなら)GPUの利用率が極端に落ちてしまいます。この場合はスレッドを増やすとか、読み込み処理を改善するとか、読み込みやすデータ形式にするとか、ストレージを見直すとか読み込みが学習に追いつくように対策してください。これはチュートリアルにある tf.train.shuffle_batch() を使用した時にも言えることです。
これで将棋データとかいうわけのわからない独自データをtfの枠組みで非同期並列で読み込めるようになりました。
なったおこうなったお(ここまでの学習の成果)
ここまでまったく書いてませんでしたがtensorboardに学習時のミニバッチごとの正答率を表示するようにしました。
デバッグ中のロスと正答率です。
条件
- データは2chkifuの全データからTORYOで終了しているものを抽出
- 30手以降の先手の盤面を使用
- その盤面で先手が勝つか後手が勝つかを判定させる
- モデルは前回提示したモデル
- ミニバッチサイズは100
- 正答率は学習で投入したミニバッチに対する都度の判定で正解だった割合
- 学習の途中の約30000イテレーションでのグラフを出した
ロス

正答率

(・ε・)あるえー?
途中までロスが単調に下がり正答率がロスに応じて上がってきて「やったか!?」と思ったのだけれどこれを書いているうちに変な推移が起きていました。書き込み負荷を気にして勾配のヒストグラムを出していないので勾配消失が起きているかどうかはわかりません。
予測される原因
- サンプルデータが一巡してしまった(現在無限ループする実装)
- サンプル読み込みが途中でぶっ壊れた
- 勾配消失?消失すると学習が止まるだけじゃないの?
ちょっとわかりませんね。
でも途中まではうまくいっているので希望が出てきました。勾配消失していたモデルではイテレーションが進んだ後に正答率0.65とかは出てこなかったので突き詰めがいがあります。
今後の予定
次は以下のような感じでしょうか。
- サンプル読み込みスレッドのデバッグ(現在プログラム終了時にエラーが出る)
- サンプルデータパースのテスト(持ち駒まで正確にパースできているか自信がない)
- 投入データの整理と複数エポック学習の実装(モデルデータのレストア)
- 後手の学習、左右反転学習の実装
「モデルは不十分だが学習にバグはなく、モデルの改善だけを行えば良い」という状態になったら指し手のモデルに入っていきたいと思います。そして自律学習と実際の対局!