前回 勝敗予測モデルの学習をEC2 p2.8xlarge Multi GPUでやろうとした : TensorFlow将棋ソフト開発日誌 #10
目次 TensorFlow将棋ソフト開発日誌 目次
ソースはgithubにあります(俺が読めればいいというレベル)
マルチGPUは難しい
目次
- 新しい学習マシンを調達した
- TensorFlowでマルチGPU
- 新しいモデルとseparable_conv2d
- 学習と学習の結果
- その他いろいろやった細かい作業
- 今後の予定
新しい学習マシンを調達した
学習用にマシンを調達しました。ビデオカードは1枚流用、1枚新調。デュアルGPUでやります。
CPU: Intel Core i7 6850K (6cores, 12threads)
Memory: DDR4-2133 16GB * 4, total 64GB
Graphic: GeForce GTX 1080 * 2
Power Unit: 1200W
メモリ不良で認識しなかったり1月のCESで発表されると噂だったGTX 1080 tiが結局発表されなかったり、いろいろ紆余曲折がありました。
TensorFlowでマルチGPU
基本は以前AWS EC2で実験していたコードであり、TensorFlowのガイドに載っているアーキテクチャです。つまり各GPUで勾配を計算しCPUで平均してウェイトに反映、それをまたGPUで使用するという流れです。ただどうもCPUの使用率が上がってしまう(相対的にGPUの稼働率が下がってしまう)傾向があります。
TensorFlowのチュートリアルで紹介されているのは小さなモデル(Conv2, Linear2)を大きなバッチサイズ(128)で学習しています。この場合はGPUの処理時間はバッチサイズが大きいことにより比率が大きく、CPUで平均をとる処理はモデルの小ささに起因して比率が小さいです。
どうもモデルが大きくなってくると勾配をCPUで平均する処理がボトルネックになりせっかくのGPUの稼働率が上がりません。近いうちに勾配の平均もGPUで計算するようにして簡単な時間計測をします。
新しいモデルとseparable_conv2d
将棋の盤面一つを見てこれを自分が勝つか相手が勝つかに分類する勝敗予測モデルを作っています。当面は勝敗予測モデルが自分の勝利を予測する手を指すというAIにしていくつもりです。またマルチGPU導入と前後してバグが入ったりバグを発見したりしました。いろいろと気分を変えるため実験モデルを新しくしました。
そしてseparable_conv2dというのものを導入しました。
separable_conv2d
将棋の入力テンソルにおいて各チャンネルの意味が大きく異なるのでtf.nn.separable_conv2dを導入しました。tf.nn.separable_conv2dについてはtf.nn.conv2d, tf.nn.depthwise_conv2d, tf.nn.separable_conv2dのチャネル数と意味にまとめてみました。
新しいモデル
まだ「動く将棋ソフトを作るためのとりあえずの小さなモデル」という段階です。バッチノーマライズなどの記述は省略します。バッチサイズは64です。最後の線形層で「自分の勝ち、相手の勝ち」の2次元ベクトルに落とします。
以前のモデルはTensorFlowによる将棋ソフトの開発日誌(ゆっけさんの場合) #5にあります。
入力データ [64,9,9,360]
separable_conv2d [64,9,9,1080] kernel_size=9
separable_conv2d [64,9,9,1080] kernel_size=9
separable_conv2d [64,9,9,1080] kernel_size=7
separable_conv2d [64,9,9,1080] kernel_size=7
separable_conv2d [64,9,9,1080] kernel_size=5
conv2d [64,9,9,1080] kernel_size=9
conv2d [64,9,9,1080] kernel_size=5
linear [64,1200]
linear [64,300]
linear [64,2]
まだレジデュアル(ネットワークを途中で分岐させたり合流させたりする)は導入していません。いずれやりたいしやらなきゃいけないかなという感じ。
学習と学習の結果
学習の条件
いままでのデータセットに修正を加えました。
- 2chkifu 約62000戦のうち約50000戦の各盤面を学習サンプルとする
- 30番手以降、435,000盤面から盤面の形が同じものを除外したものが学習対象(今回、左右反転を廃止、重複を除去)
- 上記学習対象を5つのセットに分割(学習の途中中断に対応するため)
- 試験サンプルは残りの約12000戦、約1017600盤面(今回、左右反転を廃止、重複を除去)
- 学習サンプルと試験サンプルには一部盤面に重複がありそう(ちゃんと確認してない)、ただし違う対戦のデータではある。
今回は4エポック学習しました(3日と13時間かかりました)。
学習の結果
以前の結果は勝敗予測モデル2エポック目の成績報告とDNNの種々考察(ポエム回) : TensorFlow将棋ソフト開発日誌 #9にあります。
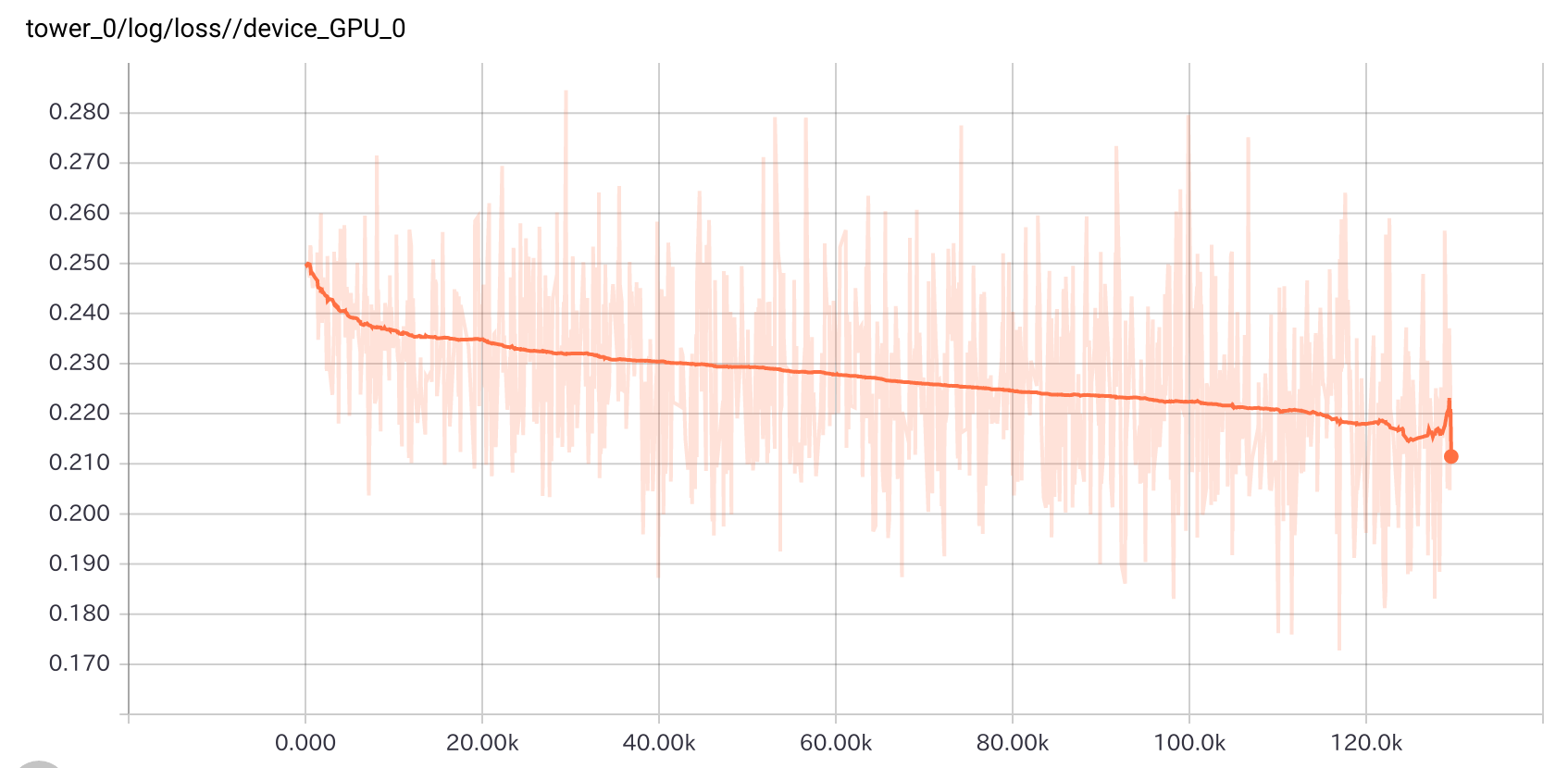
GPU0でのロスの推移です。
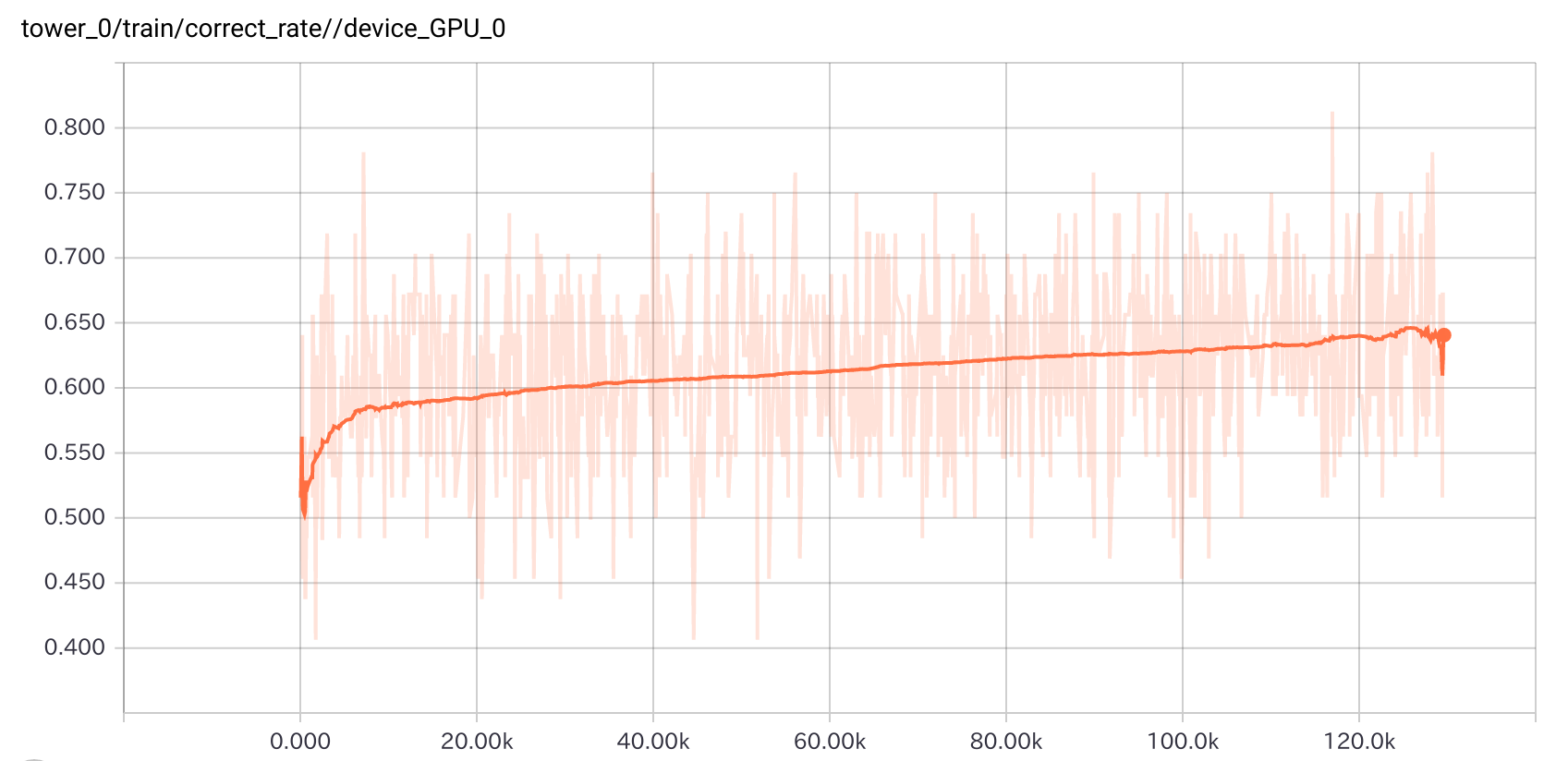
GPU0での学習正答率の推移です。
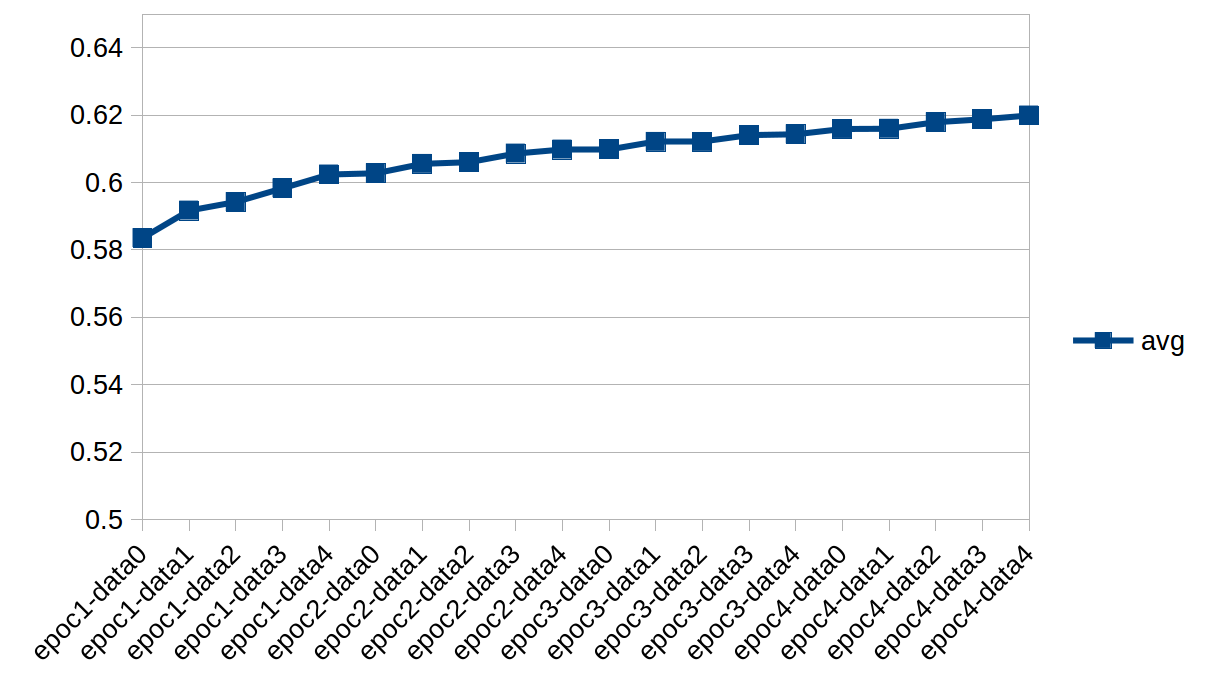
試験データでの正答率の推移です。各エポックの各データセットを終えた時点での各モデルについて試験データセットで判定をさせています。avgは試験データセット全体について正答率の平気んです。minは1つのバッチ(サイズ64)について最低だった正答率、maxは同様に最高だった正答率です。
エポック1 データセット0-4
correct rate(15900): avg 0.583496462264151, min 0.375, max 0.859375
correct rate(15900): avg 0.591655856918239, min 0.34375, max 0.8125
correct rate(15900): avg 0.5942099056603773, min 0.34375, max 0.828125
correct rate(15900): avg 0.5982615959119497, min 0.359375, max 0.828125
correct rate(15900): avg 0.6023584905660377, min 0.375, max 0.8125
エポック2 データセット0-4
correct rate(15900): avg 0.6027299528301887, min 0.34375, max 0.84375
correct rate(15900): avg 0.6055257468553459, min 0.375, max 0.828125
correct rate(15900): avg 0.6060200471698113, min 0.359375, max 0.828125
correct rate(15900): avg 0.6085829402515723, min 0.390625, max 0.859375
correct rate(15900): avg 0.6097749606918239, min 0.328125, max 0.828125
エポック3 データセット0-4
correct rate(15900): avg 0.6099105738993711, min 0.328125, max 0.828125
correct rate(15900): avg 0.6120558176100629, min 0.375, max 0.828125
correct rate(15900): avg 0.6120341981132076, min 0.375, max 0.828125
correct rate(15900): avg 0.6140467767295598, min 0.359375, max 0.828125
correct rate(15900): avg 0.6143052279874214, min 0.34375, max 0.828125
エポック4 データセット0-4
correct rate(15900): avg 0.615880503144654, min 0.375, max 0.859375
correct rate(15900): avg 0.6159276729559748, min 0.375, max 0.828125
correct rate(15900): avg 0.6178979952830189, min 0.40625, max 0.828125
correct rate(15900): avg 0.6187421383647799, min 0.375, max 0.828125
correct rate(15900): avg 0.6198810927672956, min 0.390625, max 0.828125
試験データセット全体についての平均正答率を学習のステップに沿ってグラフにしたものが以下です。
考察
結果は良くなっていますがseparable_conv2dが有効であったのか学習・試験データセットのコンフィギュレーションを変更したのが影響しているのかはわかりません。モデル自体は割と適当なため「学習はできていること」「複数エポック学習してもまだ過学習には至らないこと」が確認できただけでよしとします。
下に書いたとおり(あるいは書いていないこともあるけれど)いろいろバグ修正とか学習バッチの整備をしてマルチGPUでの学習にも慣れてきてモデルもこの路線で学習できそうで、順当に自己対戦からの学習などに進んでいきます。
実際のところこのモデルにする前にもう少し大きなモデルで学習が進まないトラブルに見舞われて、結果として今回のモデルにしました。が、それでも学習が進まなくて初期値の悪さに思い至り何度も調整を重ねてようやく学習するようになりました。

xavier initializerなど適切に初期値を決める方法なども探っていきたいと思います。
その他いろいろやった細かい作業
入力ベクトル作成のバグ修正
入力ベクトルの作成にバグがあったので修正しました。盤面を表すsfen形式のテキストからnumpyのテンソルに変換する際に持ち駒の情報等が一部抜けてしまうバグがありました。つまり12月までの実験はバグのある入力で行っていたことになります。それでそれっぽく学習してしまうのだから恐ろしい。
ロスのバグの修正・変更
出力の2次元ベクトル([自分の勝敗, 相手の勝敗])についてクロスエントロピーの総和を1サンプルのロスにしてましたが、総和はとらずにベクトルの要素ごとにロスを設定するべきでした。またさらに性質的に二乗誤差で問題ないのでわかりやすい二乗誤差でいくことにしました。
学習処理のyaml化
複数エポック学習を繰り返す際にいちいちコマンドを叩いたり場当たり的なシェルスクリプトを書くのがめんどくさくミスも増えがちなためyamlで作業を記述して途中で止めても途中から復帰できるスクリプトを書きました。以下のようなyamlでどのデータセットでどういうパラメータで学習するか記述しています。復帰処理や学習パラメータの保存など便利になったけれどもまだイケてない部分も多いので自分が使いやすいように育てていきます。
settings:
output_directory: outs
aliases:
- &mkdir
command: mkdir
args: ['models']
- &cpmodel
command: cp
args: ['../../prophet_model.yaml','..']
- &train_args
- -u
- ../ginkgo.git/train_prophet_with_records.py
- --logdir=../logs
- train
- --modeldir=models
- --output-model=prophet_model.ckpt
- --prophet-yaml=../prophet_model.yaml
- --num-gpus=2
- --minibatch-size=64
- --learning-rate=1e-6
- --log-gradients=true
batches:
- name: prepare
commands:
- command: git
args: [
'clone', 'git@github.com:YusukeSuzuki/ginkgo.git', '../ginkgo.git', '--branch', 'working_0.0.4']
- *cpmodel
- command: mkdir
args: ['../logs']
- name: phase1
commands:
- *mkdir
- command: python3
args: *train_args
args1:
- --samples=/mnt/data/ginkgo/data/make_unique/unique_data_0
- name: phase2
commands:
- *mkdir
- command: python3
args: *train_args
args1:
- --samples=/mnt/data/ginkgo/data/make_unique/unique_data_1
- --input-model=../phase1/models/prophet_model.ckpt
- name: phase3
commands:
- *mkdir
- command: python3
args: *train_args
args1:
- --samples=/mnt/data/ginkgo/data/make_unique/unique_data_2
- --input-model=../phase2/models/prophet_model.ckpt
# いかズラズラと続く
TensorFlow 1.0対応
公式で既存のコードを1.0対応にさせるスクリプトが配布されていたため簡単にできました。自分のコードはtf.concat()でaxes引数に対応させるだけで済みました。
今後の予定
- 自己対戦、書きます
- 自己対戦結果からの学習、書きます
- モデルを書くyamlをもう少し拡充します(イニシャライザを書けるようにしたい)