本記事ではRG (Reber Grammar), ERG (Embeded -), CERG(Continuous -) により生成する言語を予測する学習モデルを紹介する.
LSTMのTensorFlow実装のチュートリアルとしてPTB (Penn Treebank) という言語データセットを用いた学習があるが,入門としては理解が難しい.よって,入門として8つの文字からなる言語をオートマトン的に生成するアルゴリズム(RG, ERG, CERG) から生成される言語を予測するモデルの学習を行う.
RG, ERGについて

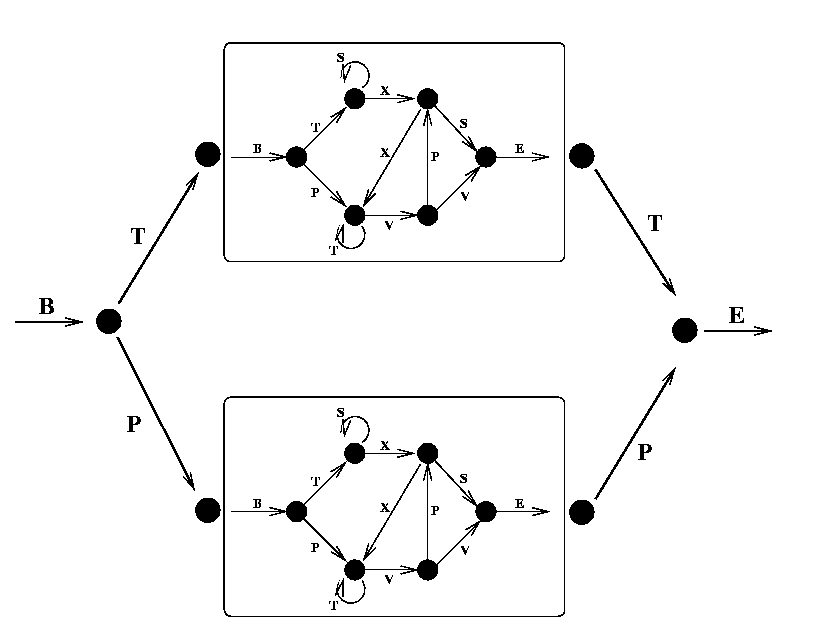
https://www.willamette.edu/~gorr/classes/cs449/reber.html
の参考サイトがわかりやすい.
例えば"BTSSXSE.BPVVR."はRGの一つで,"BPBTSXXVVEPE."はERGの一つになる.CERGはERGから終端文字"."を取り除いた言語となる.本記事は8文字からなるこれらの言語を予測することにする.
ソースコード
githubのソースコードを下に載せる.Python3,TensorFlow API r1.1での動作を確認した.TensorFlowはバージョンごとの変更が大きいので,バージョンが違う場合はそのまま動くと思わないほうがいいかも.
# ! /usr/local/bin/python
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import random
from create_RG import ERG_generator
num_of_sample_length = 10000
class RG_predict_model:
def __init__(self, data_model):
self.num_of_hidden_nodes = 60
self.chunk_size = 20
self.model_file_name = "./tmp/model.ckpt"
self.batch_size = 100
self.forget_bias = 0.8
self.learning_rate = 0.001
self.num_of_epochs = 50000
try:
#train data set
self.rggen = data_model()
self.rggen.generate(num_of_sample_length)
self.num_of_output_nodes = self.rggen.CHAR_VEC
self.num_of_input_nodes = self.rggen.CHAR_VEC
#test data set
self.test_rggen = data_model()
self.test_rggen.generate(num_of_sample_length)
except:
print("could not specify generator model")
raise
def inference(self, input_ph, istate_ph):
with tf.name_scope("inference") as scope:
weight1_var = tf.Variable(tf.truncated_normal(
[self.num_of_input_nodes, self.num_of_hidden_nodes], stddev=0.1), name="weight1")
weight2_var = tf.Variable(tf.truncated_normal(
[self.num_of_hidden_nodes, self.num_of_output_nodes], stddev=0.1), name="weight2")
bias1_var = tf.Variable(tf.truncated_normal(
[self.num_of_hidden_nodes], stddev=0.1), name="bias1")
bias2_var = tf.Variable(tf.truncated_normal(
[self.num_of_output_nodes], stddev=0.1), name="bias2")
in1 = tf.transpose(input_ph, [1, 0, 2]) #(chunk_size, batch_size, CHAR_VEC_DIM)
in2 = tf.reshape(in1, [-1, self.num_of_input_nodes]) #(chunk_size * batch_size, CHAR_VEC_DIM)
in3 = tf.matmul(in2, weight1_var) + bias1_var #(chunk_size * batch_size, num_of_hidden_nodes)
in4 = tf.split(in3, self.chunk_size, axis=0) #chunk_size * (batch_size, num_of_hidden_nodes)
cell = tf.contrib.rnn.BasicLSTMCell(
self.num_of_hidden_nodes, forget_bias=self.forget_bias, state_is_tuple=False)
outputs, states = tf.contrib.rnn.static_rnn(cell, in4, initial_state=istate_ph)
output = tf.matmul(outputs[-1], weight2_var) + bias2_var
return output
def evaluate(self, output, label):
with tf.name_scope("evaluate") as scope:
prediction = tf.nn.softmax(output)
correct_prediction = tf.equal(tf.argmax(output,1),tf.argmax(label,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar("accuracy", accuracy)
return prediction, accuracy
def loss(self, output, label):
with tf.name_scope("loss") as scope:
loss = tf.reduce_mean(tf.losses.softmax_cross_entropy(label, output))
tf.summary.scalar("loss", loss)
return loss
def training(self, loss):
with tf.name_scope("training") as scope:
optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(loss)
return optimizer
def train(self):
input_ph = tf.placeholder(tf.float32, [None, self.chunk_size, self.num_of_input_nodes], name="input")
label_ph = tf.placeholder(tf.float32, [None, self.num_of_input_nodes], name="label")
istate_ph = tf.placeholder(tf.float32, [None, self.num_of_hidden_nodes * 2], name="istate")
prediction = self.inference(input_ph, istate_ph)
loss = self.loss(prediction, label_ph)
optimizer = self.training(loss)
evaluater = self.evaluate(prediction, label_ph)
summary = tf.summary.merge_all()
with tf.Session() as sess:
summary_writer = tf.summary.FileWriter("./tmp/RG_log", graph=sess.graph)
sess.run(tf.global_variables_initializer())
####### train ########
for epoch in range(self.num_of_epochs):
inputs, labels = self.rggen.get_batch(self.batch_size, self.chunk_size)
train_dict = {
input_ph: inputs,
label_ph: labels,
istate_ph: np.zeros((self.batch_size, self.num_of_hidden_nodes * 2)),
}
sess.run([optimizer], feed_dict=train_dict)
if (epoch) % 100 ==0:
summary_str, train_loss, (prediction, acc) = sess.run([summary, loss, evaluater], feed_dict=train_dict)
print("train#%d, loss: %e, accuracy: %e" % (epoch, train_loss, acc))
summary_writer.add_summary(summary_str, epoch)
####### test #########
inputs, labels = self.test_rggen.get_batch(self.batch_size, self.chunk_size)
test_dict = {
input_ph: inputs,
label_ph: labels,
istate_ph: np.zeros((self.batch_size, self.num_of_hidden_nodes * 2)),
}
prediction, acc = sess.run(evaluater, feed_dict=test_dict)
for pred, label in zip(prediction, labels):
print(np.argmax(pred) == np.argmax(label))
print(['{:.2f}'.format(n) for n in pred])
print(['{:.2f}'.format(n) for n in label])
####### save ########
print("Training has done successfully")
saver = tf.train.Saver()
saver.save(sess, self.model_file_name)
if __name__ == '__main__':
random.seed(0)
np.random.seed(0)
tf.set_random_seed(0)
rg_model = RG_predict_model(ERG_generator)
rg_model.train()
次に順に詳細を解説する.
def __init__(self, data_model):
self.num_of_hidden_nodes = 60
self.chunk_size = 20
self.model_file_name = "./tmp/model.ckpt"
self.batch_size = 100
self.forget_bias = 0.8
self.learning_rate = 0.001
self.num_of_epochs = 50000
try:
#train data set
self.rggen = data_model()
self.rggen.generate(num_of_sample_length)
self.num_of_output_nodes = self.rggen.CHAR_VEC
self.num_of_input_nodes = self.rggen.CHAR_VEC
#test data set
self.test_rggen = data_model()
self.test_rggen.generate(num_of_sample_length)
except:
print("could not specify generator model")
raise
入力ベクトルはone hotなベクトルで表現するため,8次元ベクトルであらわされる(e.g. B=(1,0,0,0,0,0,0,0))が,LSTMセルに入力する手前でfully connectedな層をはさみ,num_of_hidden_nodes=60次元ベクトルに特徴量増加させる.LSTMはいくつ前の入力までを出力に影響させるかを決めるパラメータが必要で,これをchunk_sizeで指定する.今回は一回の予測に連続した20文字を入力とする.引数のdata_modelにはEG_model,ERG_model,CERG_modelのいずれかが入る.
def inference(self, input_ph, istate_ph):
with tf.name_scope("inference") as scope:
weight1_var = tf.Variable(tf.truncated_normal(
[self.num_of_input_nodes, self.num_of_hidden_nodes], stddev=0.1), name="weight1")
weight2_var = tf.Variable(tf.truncated_normal(
[self.num_of_hidden_nodes, self.num_of_output_nodes], stddev=0.1), name="weight2")
bias1_var = tf.Variable(tf.truncated_normal(
[self.num_of_hidden_nodes], stddev=0.1), name="bias1")
bias2_var = tf.Variable(tf.truncated_normal(
[self.num_of_output_nodes], stddev=0.1), name="bias2")
in1 = tf.transpose(input_ph, [1, 0, 2]) #(chunk_size, batch_size, CHAR_VEC_DIM)
in2 = tf.reshape(in1, [-1, self.num_of_input_nodes]) #(chunk_size * batch_size, CHAR_VEC_DIM)
in3 = tf.matmul(in2, weight1_var) + bias1_var #(chunk_size * batch_size, num_of_hidden_nodes)
in4 = tf.split(in3, self.chunk_size, axis=0) #chunk_size * (batch_size, num_of_hidden_nodes)
cell = tf.contrib.rnn.BasicLSTMCell(
self.num_of_hidden_nodes, forget_bias=self.forget_bias, state_is_tuple=False)
outputs, states = tf.contrib.rnn.static_rnn(cell, in4, initial_state=istate_ph)
output = tf.matmul(outputs[-1], weight2_var) + bias2_var
return output
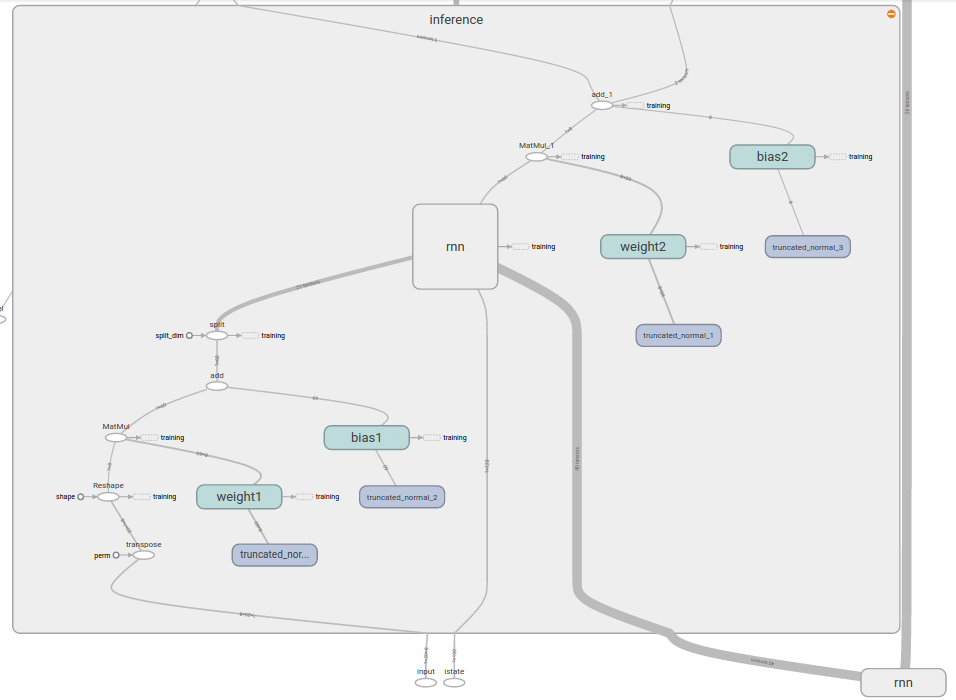
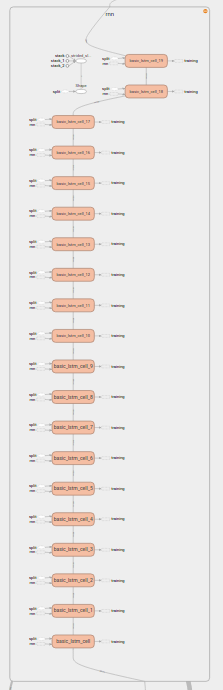
input(8D) -> 全結合層-> (60D) -> LSTM-> (60D) -> 全結合層 -> output(8D)という流れで層を組んでいく.in1~in4はWx+b計算を容易に行うために変換しているだけである.tf.contrib.rnn.static_rnnは第二引数の配列サイズを勝手に取得して,cell(第一引数)を作り結合してくれる.各セルは[内部の特徴量=60]x[バッチサイズ=100]の入力を受け取る.
inference全体:
rnnの内部(chuk_size分のcellを生成してくれている):
evaluate,loss,trainingは省略.
def train(self):
input_ph = tf.placeholder(tf.float32, [None, self.chunk_size, self.num_of_input_nodes], name="input")
label_ph = tf.placeholder(tf.float32, [None, self.num_of_input_nodes], name="label")
istate_ph = tf.placeholder(tf.float32, [None, self.num_of_hidden_nodes * 2], name="istate")
prediction = self.inference(input_ph, istate_ph)
loss = self.loss(prediction, label_ph)
optimizer = self.training(loss)
evaluater = self.evaluate(prediction, label_ph)
summary = tf.summary.merge_all()
inputと正解ラベル用のインスタンス,LSTMの先頭に入力する状態情報のインスタンス,各出力のインスタンスを定義.summaryはtensorboardなどでデバッグするのを容易にするための結果のログの出力.
####### train ########
for epoch in range(self.num_of_epochs):
inputs, labels = self.rggen.get_batch(self.batch_size, self.chunk_size)
train_dict = {
input_ph: inputs,
label_ph: labels,
istate_ph: np.zeros((self.batch_size, self.num_of_hidden_nodes * 2)),
}
sess.run([optimizer], feed_dict=train_dict)
if (epoch) % 100 ==0:
summary_str, train_loss, (prediction, acc) = sess.run([summary, loss, evaluater], feed_dict=train_dict)
print("train#%d, loss: %e, accuracy: %e" % (epoch, train_loss, acc))
summary_writer.add_summary(summary_str, epoch)
dictionaryに入力をまとめ,学習を開始.結果をsummaryに追加する.rggen.get_batchは指定した入力データを持ってくる.詳しくはgithubのcreate_RG.pyを見よう.
####### test #########
inputs, labels = self.test_rggen.get_batch(self.batch_size, self.chunk_size)
test_dict = {
input_ph: inputs,
label_ph: labels,
istate_ph: np.zeros((self.batch_size, self.num_of_hidden_nodes * 2)),
}
prediction, acc = sess.run(evaluater, feed_dict=test_dict)
for pred, label in zip(prediction, labels):
print(np.argmax(pred) == np.argmax(label))
print(['{:.2f}'.format(n) for n in pred])
print(['{:.2f}'.format(n) for n in label])
同様にtest用の入力辞書を作り,出力を表示する.{:.2f}は小数点第二位まで出力するための記法.#正解ラベルと出力ラベルの表示が縦に揃うように出力してるだけ.
参考サイト: