趣旨
今回は、とかく誤解されたままになりがちなこのテーマについて自分の中での整理も兼ねて書いていきます
内容は特定の言語に限定されるものではありませんが、コード例はJavaで書いています。他の言語をお使いの方は適宜読み替えながら読んでいただければ幸いです
入門書は間違ったことを教えている?
皆さんはどのような本でオブジェクト指向プログラミング言語を勉強しましたか?多くの方は例えば「やさしい~」や「たのしい~」のような入門書から入ったのではないでしょうか(中にはいきなり分厚い言語仕様から入る剛の者も居るようですが)
その中で必ずと言っていいほど書かれているワードがあります
フィールドはprivateにし、その値の書き換えや読み取りにはgetterやsetterを用意しましょう。これによってカプセル化が維持されます
さて一方でコミュニティなどでは次のように言われることがあります
getterやsetterを使うのをやめよう
一方では使おうと言っている人たちが居り、もう一方では使うべきでないとする人たちが居るのです。これは困りましたね、どちらが正しいのでしょうか?
どちらも正しい。ただし・・・
結論から言えば、入門書が嘘を教えているわけではありません。ただ、初心者に教えるという前提がある手前、オブジェクト指向のごく浅い部分にしか触れられないため誤解を生んでいるだけです
確かにフィールドを外部から隠蔽し、getterやsetterで皮をかぶせることである程度内部の実装に幅を持たせることができます
だからと言ってオブジェクトをただのデータの入れ物としてgetterとsetterをこねくり回すコードを書いていると、あちらこちらでそのオブジェクトに対して似たような操作を行うコードが書かれがちです
これはメンテナンス性を著しく下げる行為であり、好ましいことではありません
getter, setterを使うなの本当の意味
Q. ではどうするべきなのか
A. オブジェクトをデータの入れ物として扱うのではなく、そのデータの加工を任せる
例えばオンライン書店システムにおいて、本のIDと購入冊数から合計額を求めるプログラムについて考えましょう
ぱっと浮かびやすいのは次のようなコードかと思います
java
Book book = dao.findBook(bookId);
int totalPrice = book.getPrice() * quantity;
特に違和感は感じないかもしれません。特に手続型言語などではこういった中央集権的なコードが当たり前だったこともあり、入門書などでも普通にこういったコードが書かれています
これをオブジェクト指向ライクに書き換えると次のようになります
Book book = dao.findBook(bookId);
int totalPrice = book.calculateTotal(quantity);
こうすることで何が変わるのか?
・Bookの内部情報がより隠される=>前者では少なくとも「本の単価」についてが外部に引き出されていました。しかし後者ではより本来の目的に近い「合計額」のみが引き出されています
・処理の重複が起きにくくなる=>このように情報の本来の持ち主がデータの加工を担当すると、あちらこちらで同じような加工処理が行われることがなくなります。つまり全体としてのコード量や複雑さが減り、メンテナンス性が向上します
・変更に強くなる=>1つ目や2つ目と強く関係しますが、合計額算出の具体的な処理の内容はBookの中に隠蔽されています。従って、算出方法が変わったとしてもBook#calcurateTotalが変更されるだけで済みます
「getter, setterを使うな」というのはより正しく言うならば、**「そのgetter, setter呼び出しは呼び出される側への責務の割り当てに置換できないか検討しろ」**ということになります
1行まとめ
今回の内容を1行ずつにまとめると
・データの加工は、そのデータの持ち主がやるのがベスト。その結果、カプセル化が進み、コードの重複を排除できる
・カプセル化の目的は、変更による影響範囲を極力狭くすること
おまけ:関連事項
・GRASPパターン:Expert(情報エキスパート)パターン
・DRY(Don't Repeat Yourself)原則
More better
Twitterにてその設計例はよろしくないという指摘をいただき、自分でも確かになあと思ってしまったのでもう少しマシな例を挙げておきます
前述の例の問題点
その前に前述の例ではどこに問題があったのかを明確にしておきます
・quantityは本質的にBookの扱うべき情報ではないため、calculateTotalをBookの責務だと言うのは苦しい
やはりこの点が気になったのではないかと思います
私の責務配分ルール
このように処理に必要なデータの持ち主が複数に分かれる場合、私は以下のルールで責務の配分を行います
・加工対象のデータの持ち主同士で一方が他方を集約する場合、集約する側がデータの加工を担当する
・集約(包含)関係が無い場合、第3者的なオブジェクトがデータの加工を担当する
改案
まず1つのショッピングカートには複数の購入情報(本と購入個数を表す情報)が含まれています
手続型的な中央集権型の設計だとこうなるかと思います
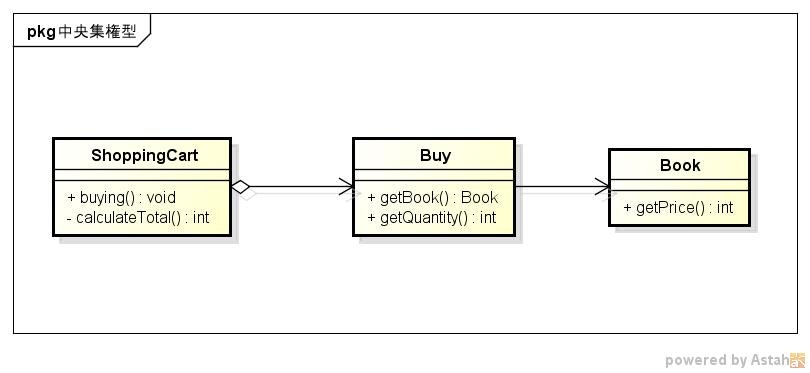
int total = 0;
for(Buy buy:buys) {
total += buy.getBook().getPrice() * buy.getQuantity();
}
return total;
次にオブジェクト指向的な分散型の設計だとこうなります

int total = 0;
for(Buy buy:buys) {
total += buy.calculateTotal();
}
return result;
return book.getPrice() * quantity;
前者がBuy及びBookをただのデータの入れ物として扱っているのに対して、後者はBuyにBuyの持っているデータの加工を任せています
後者の方が全体的にすっきりして見やすいコードになったのではないでしょうか
まだこの例でも完璧には程遠いでしょうが幾分マシになったのではないかと思います
どういう形であれ指摘や意見はありがたいのでまた何かあればよろしくお願いします