はじめに
DocumentConversionからのドキュメント生成や、トレーニングデータの簡易生成、Retrieve&Rank(RR)の日本語対応などを経て、ようやくRRの本題に入れるようになった。
興味のある人は先に上記記事も合わせて読んでもらいたい。
Retrieve&Rankの概要
Retrieve&Rankは簡単に言ってしまうと**「Apache Solr+Rank機能」**と言えるだろう。Solrを使ってドキュメントから質問と関連しそうな回答を抜き出し、Rank機能(Ranker、ランカー)によって回答の優先度を変化させて、質問に対して適切である回答を上位に持ってくる、という仕組みである。
RRの動き方の概要図を描いてみた。
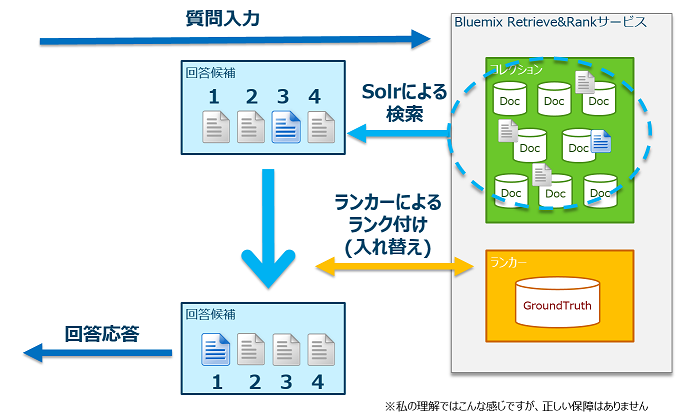
ユーザーからの質問を受けると、予め登録してあるドキュメント(Doc)に対してSolrを使用して文書検索を行う。検索した結果は必ずしも質問の回答として適切な順序に並んでいるとは限らない。ここでランカーが登場してくる。ランカーは予め学習して獲得した基礎知識(質問と回答のパターン)を参考にして、回答候補の順序を適切な順番に入れ替えて、ユーザーに応答を返す。
システムとしてはこんな感じに整理できる。
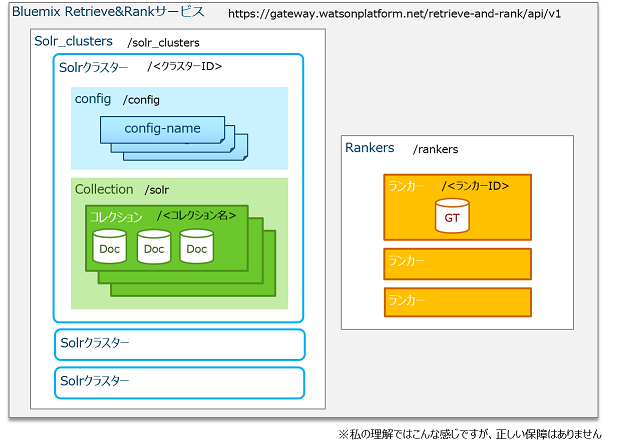
BluemixのRRサービスの中に、Solrクラスターとランカーが独立して存在している(紐付けはできる)。そのため、Solrクラスターの削除とランカーの削除は別々に行うことができ、Solrクラスターは残してランカーだけ作り直すことも可能である。
Solrクラスターは複数作成できる、はずだが、現在のRRでは1つだけしか作成できない。1個のSolrクラスターの中には、設定(config)とコレクション(collection)が置ける。設定もコレクションも、それぞれ複数作成することができる。コレクションを作成するときに複数あるうちどの設定を使うか指定する。また、コレクションにアップロードしたドキュメント(Doc)がSolrの検索対象となる。
ランカーもまた複数作成できる。ランカーを作成する際に、どの回答例(GroundTruth、GT)を使ってトレーニングし、どのコレクションに紐づけるかを指定する。
Retrieve&Rankの構成手順
さて、では早速RRを構成してみよう。手順は次のとおりである。
(事前準備)Solrクラスター、ランカーのごみそうじ
以前に使用しているSolrクラスター、ランカーがある場合は削除しておこう。
現在有効なクラスターを確認するには
curl -k -G -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters"
上記コマンドで返されるSolrクラスターIDを確認し、
curl -k -X DELETE -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters/<solrクラスターID>"
で削除する。
RRユーザーIDやRRパスワードは、Bluemixのサービス資格情報から確認できる。
solrクラスターの作成
curl -k -X POST -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters" -d ""
SolrクラスターIDが返ってくるのでメモっておこう。
{ "solr_cluster_id":"<solrクラスターID>",
"cluster_name":"","cluster_size":"",
"solr_cluster_status":"NOT_AVAILABLE"}
Solrクラスターに設定ファイルをロードする
これから作るコレクションのための設定ファイルをSolrクラスターにロードする。日本語を使いたい場合はこちらを参考に日本語用Solr設定ファイルを作ってみてほしい。
curl -k -X POST -H "Content-Type: application/zip" -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters/<solrクラスターID>/config/<設定名>" --data-binary @<設定ファイル名>
何も応答せずにプロンプトが返ってくればOK。
コレクションの作成
コレクションは問い合わせたい質問の分野(ドメイン)ごとに作成するのがいいだろう。作成するにはコレクション名、使用する設定ファイル名を指定する。
url -k -X POST -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters/<solrクラスター名>/solr/admin/collections" -d "action=CREATE&name=<コレクション名>&collection.configName=<設定名>"
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">2251</int>
</lst>
<lst name="success">
<lst>
<lst name="responseHeader">
<int name="status">0</int>
<int name="QTime">1924</int>
</lst>
<str name="core"><コレクション名></str>
</lst>
</lst>
</response>
ドキュメントの投入
回答候補となるドキュメントを投入する。ここで作ったデータや、こちらで生成したデータをってもよい。
curl -k -X POST -H "Content-Type: application/json" -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters/<クラスターID>/solr/<コレクション名>/update" --data-binary @<ドキュメント名(json)>
結果は単純。
{"responseHeader":{"status":0,"QTime":408}}
ランカーのトレーニング
GroundTruthを用いてランカーをトレーニングする。ここだけPythonを使うので注意。Windowsの場合、python 3.x系だとエラーがになる可能性もある。もしエラーが出た場合は、python 2.x系(2.7.xとか)を使うとうまくいくかもしれない。
python ./train.py -u "<RRユーザーID>:<RRパスワード>" -i <GTファイル名> -c <SolrクラスターID> -x <コレクション名> -n "<ランカー名>"
結果の中にRanker IDがあるので忘れずに取得しておく。
Input file is ./<GTファイル名>
Solr cluster is <SolrクラスターID>
Solr collection is <コレクション名>
Ranker name is <ランカー名>
Rows per query 10
Generating training data...
Generating training data complete.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 86115 0 315 100 85800 66 17977 0:00:04 0:00:04 --:--:-- 20845
{ "ranker_id":"<ランカーID>",
"name":"<ランカー名>",
"created":"2015-11-30T11:20:10.624Z",
"url":"https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/rankers/<ランカーID>",
"status":"Training",
"status_description":"The ranker instance is in its training phase, not yet ready to accept rank requests"}
ランカーのトレーニングステータスの確認
ランカーのトレーニングには数分かかる。トレーニングが終わったかどうかは、ランカーに対してGETすることで確認できる。
curl -k -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/rankers/<ランカーID>"
結果の"status"が"Available"になればOK。"Training"だとまだトレーニング中。エラーになると"Failed"になり、"status_description"でエラーメッセージが返されるので、それを見て問題判別をする。
{ "ranker_id":"<ランカーID>",
"name":"<ランカー名>",
"created":"2015-11-30T11:20:10.624Z",
"url":"https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/rankers/<ランカーID>",
"status":"Available",
"status_description":"The ranker instance is now available and is ready to take ranker requests." }
ランカーのテスト
ランカーに対してGETを投げることで質問できる。最後のflオプションで返すデータを選択できる。ここで指定するフィールドは、solr設定ファイルのschema.xmlではsotored="true"で定義されている必要があるので注意。
curl -k -G -u "<RRユーザーID>:<RRパスワード>" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters/<solrクラスターID>/solr/<コレクション名>/fcselect?ranker=<ランカーID>&q=<質問>&wt=json&fl=id,title,body"
応答は以下のようになる。
{ "responseHeader":
{ "status":0,
"QTime":2 },
"response":{
"numFound":1,
"start":0,
"maxScore":0.6786956,
"docs":[
{ "id":"17",
"body":[
" ~回答~" ]}]}}
numFoundが見つかった回答数、maxScoreが回答のスコア(なのだが、どういう意味なのかがよくわからない・・・)、docsの中は回答候補がリストされる(この例では元のドキュメントに"title"が無いために表示されていないが、"title"が見つかれば返される)。
質問を入れると回答を返してくれるツール
いちいちcurlで実行するのは面倒なので、質問を入れると結果を返してくれるツールをnode.jsで作成した。node ranker <クラスターID> <コレクション名> <ランカーID> <質問> として実行するとランカーが最も適切と判断した回答を返してくれる。最初の法にある、は自分の環境に合わせて修正して欲しい。
// Watson Developer Cloud
var watson = require('watson-developer-cloud');
var retrieve_and_rank = watson.retrieve_and_rank({
username: '<RRユーザーID>',
password: '<RRパスワード>',
version: 'v1'
});
// 引数チェック
if (process.argv.length != 6){
console.log("USAGE: node ranker <Cluster_ID> <Collection_name> <Ranker_ID> <question>");
return 1;
}
var cid = process.argv[2];
var colname = process.argv[3];
var rid = process.argv[4];
var que = process.argv[5];
// 引数確認
console.log(">>> クラスターID : " + cid);
console.log(">>> コレクション名 : " + colname);
console.log(">>> ランカーID : " + rid);
console.log(">>> 質問 : " + que);
// パラメーター設定
var params = {
cluster_id: cid,
collection_name: colname
};
// Use a querystring parser to encode output.
var qs = require('qs');
// Get a Solr client for indexing and searching documents.
// See https://github.com/watson-developer-cloud/nodejs-wrapper/tree/master/services/retrieve_and_rank.
solrClient = retrieve_and_rank.createSolrClient(params);
var ranker_id = rid;
var question = 'q=' + que;
var query = qs.stringify({q: question, ranker_id: ranker_id, fl: 'id,title,body'});
solrClient.get('fcselect', query, function(err, searchResponse) {
if(err) {
console.log('Error searching for documents: ' + err);
} else {
// 回答の有無を確認
if(searchResponse.response.numFound == 0) {
console.log("回答が見つかりませんでした");
return 1;
} else {
// 1つ目の回答を返す
console.log(">>> 回答 = " + searchResponse.response.docs[0].body);
}
}
});
Android用に構成したRRに問い合わせてみた。実行例はこんな感じ。
$ node ranker <クラスターID> android-collection <ランカーID> "Androidのバージョンを調べたい"
>>> クラスターID : <クラスターID>
>>> コレクション名 : android-collection
>>> ランカーID : <ランカーID>
>>> 質問 : Androidのバージョンを調べたい
>>> 回答 = 1.アプリケーションシートから設定を選択、2.「端末情報」を選択、3.「Androidバージョン」項目で確認できます
ツール使用上の注意
このツールはwatson-developer-cloudモジュールを使用している。Bluemix上で稼働させる場合はいいのだが、ローカルで稼働させる場合はwatson-developer-cloudモジュールをインストールしないとエラーになるので注意。
npmが使える環境であればnpm install watson-developer-cloudで導入できる。
RRの応用
他のドメイン(分類)について質問したい場合は、コレクションを分けてあげる必要がある。設定は同じでもいいが、コレクションを分け、ランカーも分けて質問のケースによってどちらのコレクションに問い合わせるかを振り分けるのがよいだろう。これもそのうち試して書きたい(次の次あたり?)。
おわりに
今回ようやくRRを使ったシステムが動かせた。精度を出すためにはGTの作り方が重要になってくるだろう。現在のところGUIなどでGTを作れるツールは無いので、そういうのが出てくると非常にやりやすくなるのだが、果たして出てくるだろうか。
次は視点を変えてNatural Language Classifier(NLC)を試した結果をお届けしたい。