極小Lispインタプリタを作ろう!
この記事では、非常に機能を絞ったLispインタプリタの作成を通じて、パーサーコンビネータや、それにまつわるテクニック、考え方などを紹介していきます。
今回作成するLispに登場するのは、四則演算関数と、数値型だけの非常にミニマムなものです。
例えば以下のようなソースになります。
(* (+ 3 18) 2)
これをインタプリタなどに食わせると、(3 + 18) * 2 という計算を行い、42が返ってきます。
四則演算しかできないとても極小のものですが、作成の過程では様々なテクニックを交えつつ紹介してみたいと思います。
また、この記事では、"無限リストの作り方"で作成したListを多用しますので、随時参照して頂けると読みやすいかと思います。
そもそもLispってなんだよ?
LispはList Processingに由来するプログラミング言語です。とても古い言語ですが、コンピュータの歴史的に大きな影響を与えた言語です。
また、「計算機プログラムの構造と解釈」というMITの計算機科学の教科書にも使われた言語でもあります。
Lispに触れることで、広く一般に現在使われている言語を使っているとなかなか得られない面白い体験をすることができますので、それらも随時紹介してみようと思います。
Lispのキホン
さて、もっと踏み込んだLispの背景はさらっとこれくらいにして、
今回実装するLispの基幹部分について書こうと思います。
踏み込みすぎるとややこしくなってしまうので、必要最低限を目指します。
さて、突然ですが、以下のLispソースはなんでしょうか?
(+ 4 2)
既に気付いている方もいらっしゃるかもしれませんが、
プラス記号は関数です。そして、それに続くものが引数です。
例えばさらに以下のようにも書けます。
(+ 4 2 4)
これは計算すると10ですね。
さて、これだけの情報で、もう最初のプログラムを理解できるようになりました。
(* (+ 4 2) 10)
内側の部分が優先されますから、
(* (+ 4 2) 10)
(* 6 10)
60
というわけですね
括弧ばかりで一体なんだ?という気持ちが少しはやわらいだかと思います。
で、リストってどこに出てくるの?
LispはLisp Processing、すべての基盤はリスト(片方向リンクリスト)です。
(+ 4 2)
これはただのソースコードですが、Lispの処理系はこれを、
+, 4, 2
3つの要素のリストだとまず理解します。
あれ?リストは一般にデータ構造です。
これでは計算できないじゃないか、という気がしてきますね。
評価する(1)
Lispには、評価する、という概念があります。Lisp処理系はとても評価したがり屋さんで、与えるものは何でも評価してしまいます。
ではLispにリストを与えたら、何が起こるのでしょうか?
単刀直入にいうと、Lispはリストを評価する時、それは関数呼び出しだと理解します。その時の挙動を追いかけてみましょう。
(+ 4 2)
というリストが与えられた時、まず第一要素を見て、それがちゃんとした関数なら、第二要素以下のリストを引数としてその関数を呼び出すのです。(定義された関数が無いならエラーです)
つまり、先のプログラムは、4, 2というリストを引数に+関数を呼び出す、というのがLispにとって評価する、ということなのです。
また、リストが入れ子になっている場合は、関数を呼び出す時に、先に引数を評価してから関数を処理するので、リストの入れ子構造にも対応できます。
評価する(2)
さて、リストの評価についてはわかりました。でも4とか2とかを評価すると何になるの?というのを一応考えておきましょう。
先に結論からいうと、4を評価すると4に、2を評価すると2になります。
つまり、数値を評価すると数値が出てくるんですね。
あまりひねりもないシンプルな約束ごとですが、実装するにあたってはこういう細かいことも確認すべきです。
データ型
そろそろLispで扱うデータ型について整理しておきましょう。
図の方がわかりやすいので図にします。
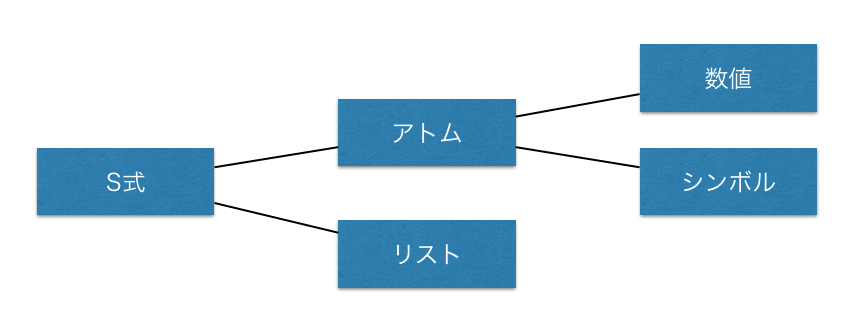
おっと、唐突に出してしまった用語が結構あります。
まずはS式ですが、これはjavaなどで、すべてはObjectである、というのに似ています。Lispの登場人物はすべてはS式である、と言っているにすぎません。
また、さらっと大事なことを書きますが、S式を評価すると、その結果はS式になります。
次はアトムです。これは数値やシンボルのような、単体のデータを指します。
最後にシンボルです。これは、
(+ 4 2)
の中の + のことをシンボルと呼びます。
今回作るLispでは、シンボルは必ず関数を指します。
これでかなり整理されてきました。
一応注意点ですが、
普通のLispにはシンボルは関数だけでなく、変数を指したりもします。
また、図のアトムも文字列については言及しませんでした。
あくまでも今回実装する極小Lispにフォーカスした図であることをご了承ください。
Swiftで実装しよう
さて、SwiftでLispを表現するのに必要なものは揃いました。
実際にコードレベルに落とし込んで行きましょう。
まずはアトムから行きましょうか
enum Atom {
case Symbol(String)
case Number(Double)
}
こんな感じで良いでしょう。
次にS式です。
enum SExpr {
case SAtom(Atom)
case SList(() -> List<SExpr>)
}
単純です。
SExpr.SListのデータ型が関数になっていますが、これは再帰的なEnumがコンパイルエラーになるための便宜的なものなので、あまり気にしないでください。
実際にこれをそのまま使うと不便なので、いくつかextensionを書きましょう。
extension Atom {
var symbol: String? {
switch self {
case let .Symbol(symbol):
return symbol
default:
return nil
}
}
var number: Double? {
switch self {
case let .Number(number):
return number
default:
return nil
}
}
init(_ symbol: String) {
self = .Symbol(symbol)
}
init(_ number: Double) {
self = .Number(number)
}
}
extension Atom : Printable {
var description: String {
if let symbol = self.symbol {
return symbol
} else if let number = self.number {
return "\(number)"
}
return ""
}
}
extension SExpr {
var atom: Atom? {
switch self {
case let .SAtom(atom):
return atom
default:
return nil
}
}
var list: List<SExpr>? {
switch self {
case let .SList(f):
return f()
default:
return nil
}
}
init(_ atom: Atom) {
self = .SAtom(atom)
}
init(_ list: List<SExpr>) {
self = .SList({ list })
}
}
extension SExpr : Printable {
var description: String {
if let atom = self.atom {
return atom.description
} else if let list = self.list {
let strings = list.map { x in x.description }
if let car = strings.car {
return "(" + strings.cdr.reduce(car) { r, x in r + " " + x } + ")"
}
return ""
}
return ""
}
}
func SExprNil() -> SExpr{
return SExpr(none())
}
最後のSExprNil()は、エラーの時に使います。
Lispにもnilが存在していて、それは要素ゼロのリストのことです。
evalとapply
さて、ここまでデータ型を定義するあまり面白くないものでしたが、
ついに「評価する」部分を作成しましょう。eval関数です。
func eval(expr: SExpr) -> SExpr {
if
let list = expr.list,
let car = list.car,
let symbol = eval(car).atom?.symbol
{
let arguments = list.cdr
return apply(symbol, arguments)
}
if let atom = expr.atom {
return expr
}
return SExprNil()
}
eval関数では、まずS式を受け取り、
それがリストならば、最初の要素を評価し、さらにそれがシンボルならば、残りのリストを引数に、その関数を呼び出します。
関数呼び出しは、apply関数として綺麗に分離できます。
また、evalの引数がアトムならば、それはそのままアトムを返します。先ほど確認した約束事ですね。
では次はapply関数です。
func apply(symbol: String, arguments: List<SExpr>) -> SExpr {
let number_arguments: List<Double> = arguments.flatMap { x in
if let number = eval(x).atom?.number {
return one(number)
}
return none()
}
let functions: [String : (Double, Double) -> Double] = [
"+" : (+),
"-" : (-),
"*" : (*),
"/" : (/)
]
if let op = functions[symbol], car = number_arguments.car {
return SExpr(Atom(number_arguments.cdr.reduce(car, combine: op)))
}
return SExprNil()
}
まずapply関数は、引数リストを先に評価します。
今回は四則演算の関数だけなので数値だけを集めて、reduceする結構乱暴な実装になっています。
さて、これって結構面白い構造になっていることに気づかれたでしょうか。
evalはapplyを呼び、applyはまたevalを欲しています。
以下のような図はどこかで見たことはないでしょうか?
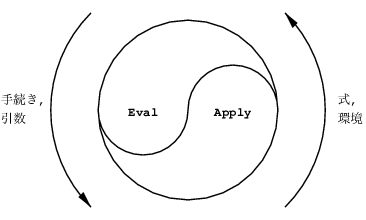
これは計算機プログラムの構造と解釈の第4章で提示されている図で、
実はこの本の表紙にもなっている重要な図なんですね。
ともあれ、これで極小Lisp処理系のコア部分の準備が完了です。
試しに以下のように、S式をSwift上で組み立てたものを評価してみましょう。
let s = SExpr([SExpr(Atom("*")), SExpr([SExpr(Atom("+")), SExpr(Atom(3.0)), SExpr(Atom(1.0)), SExpr(Atom(2.0))].toList), SExpr(Atom(2.0))].toList)
println(s)
println(eval(s))
<出力>
(* (+ 3.0 1.0 2.0) 2.0)
12.0
おめでとうございます!
これで極小Lispは完・・・おっと、まだパーサーができていませんね。
ちょっと疲れた方はいったん休憩しましょう。そして準備ができたら次はパーサーを組み立て行きます。
あ、マサカリを握り締めているかたは、そちらに置いておいてくださいね・・・。
パーサーコンビネータ?
パーサーコンビネータとは、パーサージェネレートできるライブラリのことを指します。
疑似コードでいうと、
let parser = パーサーコンビネータ-作成(定義)
let result = parser(文字列)
のように使うことができます。
パーサーが関数なら、パーサーコンビネータは高階関数(関数を返す関数)になります。
また、パーサーコンビネータの大きな特徴として、
「小さなパーサーを組み合わせて大きなパーサーを作ることができる」
というとても重要な性質があります。
この部分についても随時見ていきます。
※この部分を書くにあたって、以下を非常に参考させていただきました。
bindで毎回詰まる人の為のパーサーコンビネータの仕組み
functional programming in swift
パーサーコンビネータの準備(データ型)
まずはパーサーコンビネータの基本となる、パーサーの関数型を紹介します。
今回もやや天下り的ですが、以下の定義を使います。
struct Combinator<Token, Result> {
typealias Parser = List<Token> -> List<(Result, List<Token>)>
}
structに包んでいるのは言語仕様上、
// これはできない
typealias Parser<Result, Token> = List<Token> -> List<(Result, List<Token>)>
というようにtypealiasにジェネリクスを適用できないためです。
なので大きな意味はありません。
さて、まず引数から見てみましょう。
List<Token>
を引数に取っています。
これは「なんらかのリスト」を表しますね(当たり前ですが)。
これは例えば、文字列からパースする場合は、文字のリスト、つまり、
List<Character>
になるわけです。
ところでなぜジェネリクスで型が抽象化されているんでしょうか?
パーサーなんだからCharacterでいいじゃないか、と一瞬考えてしまいたくなりますが、
必ずしもそうではないからです。
例えば、
(* (+ 42 2) 10)
のようなものをパースする時、一気にこれを解釈するよりも、まず最初の段階で、
(
*
(
42
2
)
10
)
のような意味のある最小単位(トークン)として解釈し、その後に構造的な解釈をする、というようにフェーズを分離する場合がよくあります。こうすると一度にやらなければならない処理が減り、とても作るのが楽になります。
※このような処理を字句解析と呼びますね
他にも、Characterに限定しないことで、文字列以外の何か連続するデータならなんでも扱えるという意味でもジェネリクスにしておいて損はないでしょう。
では、次に戻り値を見てみましょう。
List<(Result, List<Token>)>
結構いろいろ詰まっています。
一旦外側のリストは忘れて、内側のタプルを考えるとして、
タプルの左側はパース結果ですね、数字が入っているかもしれないですし、文字列かもしれません。
タプルの右側はどうでしょう?
これは何かと言うと、パーサーが1回で解釈仕切れなかった余りの部分なのです。
残りの入力がある理由は、残りは別なパーサーに食わせる可能性があるからですね。
例えば、aを1文字読み取るパーサーに、abcdeという文字列を与えたとします。
すると、bcdeというのは余ってしまいます。このbcdeの部分がタプルの右側になるのです。
さて、内側のタプルは良いでしょう。
しかしなぜ外側はリストなんでしょうか?
これは、こうすることによって、
「パーサーは、可能な組み合わせを一旦全部吐き出して、その中から一番良さそうなやつを適当に使える」
という性質を持たせるためなのです。
これは今すぐここでピンと来なくても、実際に作り上げる過程で、「ああ、確かにこの構造便利だ」となるはずなので、あまり深く考えなくても良いかと思います。
ちなみに、最終的には複数の答えがあっては困るので、通常は「リストの最初に出てきた結果をパーサーの結果とする」という約束事を使います。
これでまずはなんとなく方針が分かってきました。
ここまでのまとめとして、パーサーコンビネータによって作られたパーサーは、
入力として与えられたリストを読んで、可能なら必要に応じて入力を消費して、結果と、残りの入力を吐き出す。
というところで型についてはここまでにしましょう。
パーサーコンビネータの準備(基本パーサー)
次に3つの基本構成要素を用意します。
これは、第三回: パーサーcreateと3つの基本構成要素で紹介されている考え方です。
これのswift版を考えます。
まずは、「入力を消費せず、特定の値を結果として出力するパーサー」です。
これはResultCreateと名前が付けられていますが、ここでは短くpureと呼ぶことにします。
func pure<Token, Result>(result: Result) -> Combinator<Token, Result>.Parser {
return { input in one((result, input)) }
}
次に、「入力を消費せず、必ず失敗するパーサー」です。
パースに失敗する、というのはどういうことかというと、パーサーの戻り値が空リストである時、失敗したとみなします。
func zero<Token, Result>() -> Combinator<Token, Result>.Parser {
return { input in none() }
}
最後に、「1つ入力を消費して、それを結果として返すパーサー」です。
もちろん入力が空なら失敗します。
func consumer<Token>() -> Combinator<Token, Token>.Parser {
return { input in
if let car = input.car {
return one((car, input.cdr))
}
return none()
}
}
どれもとても小さな機能で心配になるかもしれませんが、心配は無用です。
これらは組み合わせることで、真の力を発揮できるのです。結束の力です。
パーサーコンビネータの結合
結合はパーサーコンビネータの心臓部と言っても良いでしょう。
結合処理はbindと名付けます。
まずはいきなり実装を見てみましょう。
func bind<Token, T, U>(parser: Combinator<Token, T>.Parser, factory: T -> Combinator<Token, U>.Parser) -> Combinator<Token, U>.Parser {
return { input in
let lhsResult = parser(input)
return lhsResult.flatMap { (result, remainder) in
let rhsParser = factory(result)
return rhsParser(remainder)
}
}
}
・・・とても複雑な形をしています。
ジェネリクスパラメータも3つあって複雑です。
でも一つ一つ紐解いて行きましょう。
まずは第一引数は、パーサーですね。このパーサーのデータ型にToken, Tが使われています。これでまずジェネリクスパラメータの2つが明らかです。
第二引数はどうでしょうか?
parserの結果の型Tの値を引数にして、パーサーを生成する関数のようです。このパーサーの結果のデータ型がUとなっています。
次にbindの返すパーサーの処理を追いかけてみます。
すると最初に第一引数のパーサーに入力を食わせています。ここまでは良いですね。
その後、lhsResultをflatMapしてます。
flatMapの中では、factoryを使ってパーサーを1つ作っています。そして残りの入力をそのパーサーに食わせています。
flatMapに慣れていない人もいるかもしれませんが、"無限リストの作り方"でも紹介していますので、参考になるかもしれません。
パーサーが吐き出す結果が一つではなく、複数出力される可能性があるため、flatMapの必要があります。具体的に例をあげるとわかりやすいのですが、第一引数のパーサーをA、第二引数で作るパーサーをBとすると、
Aの出力結果1 - Bの出力結果1
Aの出力結果1 - Bの出力結果2
Aの出力結果2 - Bの出力結果1
Aの出力結果2 - Bの出力結果2
Aの出力結果2 - Bの出力結果3
のように単一のAの出力結果から、Bはさらに複数の出力結果を生む可能性があり、それらをマージしたのが最終出力になる、ということです。
なぜ第二引数は関数なのか?という疑問が残りますが、これは、
「Aの出力結果によって柔軟に次の1手を準備できる」
というのが大きな理由です。
こちらも実際に進めていくと、「ああ、確かにこの構造便利だ」となるので、
となるはずなので、あまり深く考えなくても良いかと思います。
※ちなみにlhs, rhsは、それぞれleft-hand side, right-hand sideの略です。この略記法、結構便利で個人的に結構好きです。
これで我々は強力な結合関数、bindを手に入れることが出来ました。
次はこれを使って、実際に様々なパーサーを組み上げてみましょう。
パーサーコンビネータの組み上げ方
手始めにある文字列から、"a"という文字を読み取るパーサーを組み立ててみましょう。
もちろんbindを使います。
func parserA() -> Combinator<Character, Character>.Parser {
return bind(consumer()) { r in
if r == "a" {
return pure("a")
}
return zero()
}
}
for (r, s) in parserA()(Array("abcde").toList) {
println("Success, found \(r), remainder: \(Array(s))")
}
何をやってるか理解するために、parserA()を使った時の挙動を追いかけてみましょう。
1、絶対に成功するconsumer()パーサーに入力を食わせる
2、成功したので r には最初の文字が入っている
3、r が "a"ならば、"a"という結果を返す、入力を消費しないパーサーを用意して投げ返す。もしも"a"じゃなければ、絶対に失敗するパーサーが返るので、bindで作成したパーサーは失敗する。
4、投げ返したパーサーが、bindの中で使われるので、"a"という結果が返る
結構短いコードではありますが、ちゃんとaをパースできています。
consumer, pure, zero、3つすべてが見事に協調動作していることが見てとれます。
原理が分かったところで、もうちょっと抽象化して使いやすくしてみましょう。
上の例で、r が "a" かどうか、というのは関数に押し出すことができます。
func satisfy<Token>(condition: Token -> Bool) -> Combinator<Token, Token>.Parser {
return bind(consumer()) { result in
if condition(result) {
return pure(result)
}
return zero()
}
}
このようにすると汎用的ですね
そして、"a"と等しいものだったら成功する、というのは以下のように、ちょっとだけ上記の関数を具体化したものとして表現できます。
func token<Token: Equatable>(t: Token) -> Combinator<Token, Token>.Parser {
return satisfy { $0 == t }
}
これを使って"a"をパースする関数は以下のように再現できます。
func parserA() -> Combinator<Character, Character>.Parser {
return token("a")
}
いい感じにスッキリしました。
もうちょっとだけ練習してみましょう。
今度は、"a" の次に "b" がくるパーサーを作ってみましょう。そして結果として返すのは、文字を2つくっつけた文字列とします。
func parserAB() -> Combinator<Character, String>.Parser {
return bind(token("a")) { a in
bind(token("b")) { b in
pure(String([a, b]))
}
}
}
for (r, s) in parserAB()(Array("abcde").toList) {
println("Success, found \(r), remainder: \(Array(s))")
}
<出力>
Success, found ab, remainder: [c, d, e]
このようにガンガンbindで結合することによって、元は本当に小さな部品だったパーサーを、複雑なパーサーに育てることができるのです。
可能性の分岐
今までのパーサーは固定のパターンしかパースすることができませんでした。
ですが、実際には複数のパターンをサポートしなければならないことのほうが多いです。そこで、パーサーAとパーサーBから、これのどちらも使ってパースを試みるパーサーを用意しましょう。
それは例えば以下のように演算子を使って以下のように書けます。
infix operator <|> { associativity left precedence 130 }
func <|> <Token, Result>(lhs: Combinator<Token, Result>.Parser, rhs: Combinator<Token, Result>.Parser) -> Combinator<Token, Result>.Parser {
return { input in lhs(input) + rhs(input) }
}
これはとてもシンプルですね。
両方の出力を結合しています。
これは、「パーサーが失敗すると、空のリストを出力する」という性質があるため、このような形をとることができます。
※ちなみに、両方成功するケースもありますが、その場合は左側が優先されます。繰り返しになりますが、これはパーサーを使う時、リストの最初に出てきた結果が最終結果である、という約束事にするからです。
これを使って、"a" もしくは "b" を読めるパーサーを作成できます。
func parserAorB() -> Combinator<Character, Character>.Parser {
return token("a") <|> token("b")
}
for (r, s) in parserAorB()(Array("abcde").toList) {
println("Success, found \(r), remainder: \(Array(s))")
}
for (r, s) in parserAorB()(Array("bcde").toList) {
println("Success, found \(r), remainder: \(Array(s))")
}
for (r, s) in parserAorB()(Array("cde").toList) {
println("Success, found \(r), remainder: \(Array(s))")
}
<出力>
Success, found a, remainder: [b, c, d, e]
Success, found b, remainder: [c, d, e]
"cde"では失敗しているので出力は無しです。
ちょっとしたユーティリティ
"a" もしくは "b"というのができるようになりましたが、
NSCharacterSetからパーサーが組み立てられると便利です。なので以下のように準備しておくと、ちょっとした文字を読むときに便利なので、軽く紹介しておきます。
extension NSCharacterSet {
var parser: Combinator<Character, Character>.Parser {
return satisfy { token in
let unichar = (String(token) as NSString).characterAtIndex(0)
return self.characterIsMember(unichar)
}
}
}
無限に続く可能性
さて、ずいぶん色々読み取れるようになってきましたが、
ここまでは固定の長さのパーサーしか作れませんでした。
さらに拡張して、"a" が何個も続く場合もうまくパースできるようにしましょう。
"a" が、というと汎用性がありませんが、あるパーサーが、と抽象化すると、これはとても強力な拡張になることが容易に想像できます。
あ、これ正規表現の * とか + なんじゃない? と思う方もいらっしゃると思いますが、まさにそれです。
それではまず、あるパーサー1回か、それ以上繰り返すのにも対応できるパーサーを作るコア関数を見てみましょう。
func oneOrMore<Token, Result>(parser: Combinator<Token, Result>.Parser, buffer: List<Result>) -> Combinator<Token, List<Result>>.Parser {
return bind(parser) { result in
let combine = buffer + one(result)
return oneOrMore(parser, combine) <|> pure(combine)
}
}
意外にシンプルです。
先にパーサーの結果型を確認すると、Listになっています。これは繰り返しに対応するためですね。
次に着目すべきは<|>の左側です。再帰になっています。ここがミソで、parserが成功する限り、最大限再帰し続けるわけです。再帰の途中で、bufferにガンガン途中経過をぶっこんでいきます。そして一番奥まで再帰した値が、パース結果として一番最初の要素として出現するからくりになっています。
シンプルに記述するには、bufferが邪魔なのと、0個も許容するzeroOrMoreを一緒に用意してあげると良いでしょう。
func oneOrMore<Token, Result>(parser: Combinator<Token, Result>.Parser) -> Combinator<Token, List<Result>>.Parser {
return oneOrMore(parser, none())
}
func zeroOrMore<Token, Result>(parser: Combinator<Token, Result>.Parser) -> Combinator<Token, List<Result>>.Parser {
return oneOrMore(parser) <|> pure(none())
}
では実際に使ってみましょう。
func parserAstream() -> Combinator<Character, String>.Parser {
return bind(oneOrMore(token("a"))) { chars in
pure(String(chars))
}
}
for (r, s) in parserAstream()(Array("aaaaab").toList) {
println("Success, found \(r), remainder: \(Array(s))")
}
<出力>
Success, found aaaaa, remainder: [b]
Success, found aaaa, remainder: [a, b]
Success, found aaa, remainder: [a, a, b]
Success, found aa, remainder: [a, a, a, b]
Success, found a, remainder: [a, a, a, a, b]
さて、先ほど説明した通り、初めて複数の結果がパーサーの結果として出現しました。
もちろん最初に出力した要素が最終結果です。
Lisp字句解析
さて、そろそろパーサーコンビネータのコア部分ができてきました。
この辺りでLispの字句解析フェーズを構築することを考え始めましょう。
まずはLispのトークンの定義を考えます。これは列挙するだけなので簡単です。
enum LispToken {
case ParenthesesL
case ParenthesesR
case Symbol(String)
case Number(Double)
}
ついでに文字列化できると、デバッグが捗るのでPrintableに準拠させておきましょう。
extension LispToken: Printable {
var description: String {
switch self {
case ParenthesesL:
return "("
case ParenthesesR:
return ")"
case let .Symbol(symbol):
return symbol
case let .Number(number):
return "\(number)"
}
}
}
では次に字句解析の型を決めてしまいます。
1つのトークンをパースできるパーサーの型は以下のようになります。
typealias LispTokenizerSingle = Combinator<Character, LispToken>.Parser
今まで積み上げてきたテクニックを使えば、あとは流れ作業で字句解析パーサーが出来上がります。
数値に関しては、簡略化のため、0~9の連続した文字列ということにしています。そして、このフェーズでdouble型にまでしてしまいます。
let tParenthesesL: LispTokenizerSingle = bind(token("(")) { _ in
return pure(LispToken.ParenthesesL)
}
let tParenthesesR: LispTokenizerSingle = bind(token(")")) { _ in
return pure(LispToken.ParenthesesR)
}
let tSymbol: LispTokenizerSingle = bind(NSCharacterSet(charactersInString: "+-*/").parser) { r in
return pure(LispToken.Symbol(String(r)))
}
let tNumber: LispTokenizerSingle = bind(oneOrMore(NSCharacterSet.decimalDigitCharacterSet().parser)) { r in
pure(LispToken.Number(NSString(string: String(r)).doubleValue))
}
さて、ここで紹介したtParenthesesL, tParenthesesR, tSymbol, tNumberの4つは、それぞれ1つしか読めません。なので、一気に全部読めるように結合しましょう。
型は以下のようになります。
typealias LispTokenizer = Combinator<Character, List<LispToken>>.Parser
パーサーは以下のように準備できます。
let tLispTokenizer: LispTokenizer = oneOrMore(tParenthesesL <|> tParenthesesR <|> tSymbol <|> tNumber)
おっと、大事なことを忘れていました。空白を無視しなければなりませんでした。
しかしこのような構造のパーサーであれば、簡単に対応できます。
func ignoreLeadingWhitespace<T>(p: Combinator<Character, T>.Parser) -> Combinator<Character, T>.Parser {
return bind(zeroOrMore(NSCharacterSet.whitespaceCharacterSet().parser)) { result in
return p
}
}
let tLispTokenizer: LispTokenizer = oneOrMore(ignoreLeadingWhitespace(tParenthesesL <|> tParenthesesR <|> tSymbol <|> tNumber))
さて、これを使って、Lispプログラムの字句解析を試してみましょう。
for (r, s) in tLispTokenizer(Array("(* (- 4 2) 10)").toList) {
println("Success, found \(r.toArray), remainder: \(Array(s))")
}
Success, found [(, *, (, +, 4.0, 2.0, ), 10.0, )], remainder: []
<以下略>
見事に意味を持つ最小単位の列に変換することができました。
もうあと一息です。
Lisp構文解析
ついに最終フェーズ、構文解析にやってまいりました。
最後のパーサーの型を出しましょう。入力は先ほどのLispToken、
そしてパーサーの結果はSExpr、そう、S式です。
typealias LispExpressionParser = Combinator<LispToken, SExpr>.Parser
本処理に入る前に、LispTokenにいくつかヘルパー関数を用意すると便利です。
extension LispToken {
var isParenthesesL: Bool {
switch self {
case .ParenthesesL:
return true
default:
return false
}
}
var isParenthesesR: Bool {
switch self {
case ParenthesesR:
return true
default:
return false
}
}
var expr: SExpr? {
switch self {
case let .Symbol(symbol):
return SExpr(Atom(symbol))
case let .Number(number):
return SExpr(Atom(number))
default:
return nil
}
}
}
exprは、データが直接S式に変換できる場合、S式を返し、できない場合はnilを返します。
さて、LispトークンからS式を構成するためのキモは括弧です。
括弧で囲まれたトークンを抜き出すパーサーは以下の関数で作成できます。
func parentheses<T>(factory: () -> Combinator<LispToken, T>.Parser) -> Combinator<LispToken, T>.Parser {
return bind(satisfy { t in t.isParenthesesL } ) { L in
bind(factory()) { insideList in
bind(satisfy { t in t.isParenthesesR }) { R in
pure(insideList)
}
}
}
}
なんてことはありません、"(" => (特定のパーサー)=> ")" をパースするだけです。
そして、すべての完成系はこれを使って以下のように定義できます。
func pLispExpression() -> LispExpressionParser {
let pAtom: LispExpressionParser = bind(consumer()) { r in
if let expr = r.expr {
return pure(expr)
}
return zero()
}
return bind(parentheses { zeroOrMore(pLispExpression() <|> pAtom) }) { exprs in
pure(SExpr(exprs))
}
}
pAtomは良いですね、単に数値やシンボルを機械的にS式に変換するだけです。
キモは、return 部でしょう。
pLispExpression()がparenthesesの内側に入っています。
そう、可能な限り奥深くまで()の蓋を開けていくのです。
そして一番奥までうまくたどり着けたものが、我々の追い求める究極のS式なのです(大袈裟でしたかね)。
早速試してみましょう。
for (r, s) in tLispTokenizer(Array("(* (+ 3 18) 2)").toList) {
let e = pLispExpression()
for (r, s) in e(r) {
println("Success \(r), eval = \(eval(r))")
}
}
<出力>
Success (* (+ 3.0 18.0) 2.0), eval = 42.0
以下略
とても長い道のりでした。ついに我々の極小Lispパーサーは完成しました。
計算の答えが、「人生、宇宙、すべての答え」になっているのはきっと偶然でしょう。
ガチなLisperさんにはこんなインタプリタなんてゴミだ!なんて言われかねないですが、
壮大なチュートリアルということでその寛大な心で許していただけたらと思います。
最後に今までの重要な部分を含んだソースコードをアップして締めようと思います。
最後までおつき合い頂いた方、ありがとうございました。
※こんな記事を書いていますが、実はLispはそこまで詳しく知っているわけではなかったりします。。
もし表現や構造等、間違いがありましたら、修正いたしますのでご指摘をお願いします。