これなに
流量データの傾向をさくっと見るためのサンプル。
元データ
国交省の物流センサスから都道府県間流動量(品類別) -重量-を利用する。
各シートは、平成22年の県別の物流量の重量データ。シートは、合計, 農水, 林業, 鉱産, 金属機械, 化学, 軽工, 雑工, 排出, 特殊の10枚ある。
実行環境
graphviz をさくっと使えるように Dockerイメージ(tsutomu7/graphviz)を用意したので、下記を実行すればよい。
bash
firefox http://localhost:8888 &
docker run -it --rm -p 8888:8888 tsutomu7/graphviz
自前で構築する場合は、Anacondaインストール後に、"conda install graphviz"と"pip install graphviz"などをする。condaでgraphgvizの本体を、pipでラッパーをインストールする。
Pythonでやってみる
データの読込
read_excel で全シートを一度に変数 a に読み込む。a は、0-9をキー、DataFrameが値となる。a[0]は全産業の"合計"のDataFrameとなる。
python3
import numpy as np, pandas as pd
cat = '合計 農水 林業 鉱産 金属機械 化学 軽工 雑工 排出 特殊'.split()
rng = list(range(len(cat)))
a = pd.read_excel('http://www.mlit.go.jp/sogoseisaku/transport/butsuryucensus/T9-010301.xls',
rng, skip_footer=1, skiprows=8, header=None, index_col=0, parse_cols=np.arange(1,49))
a[0].ix[:3, :7]
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 北 海 道 | 944271.4669 | 6728.8486 | 1075.6893 | 7623.1429 | 2350.6049 | 164.8547 | 4221.1922 |
| 青 森 | 22969.4545 | 257605.0057 | 12702.7039 | 2857.1319 | 8079.5519 | 750.9524 | 1799.4754 |
| 岩 手 | 211.2175 | 5090.7300 | 194668.7805 | 10623.9818 | 1518.8552 | 676.9535 | 1244.9179 |
行がFromとなる県、列がToとなる県を表し、47 × 47 の行列となっている。
正規化する
各産業ごとに物流量の多い順にソートする。
python3
prefs = a[0].index.map(lambda x: x.replace('\u3000', ''))
b = [pd.DataFrame([(prefs[i], prefs[j], a[h].iloc[i, j]) for i in range(47) for j in range(47)
if i != j], columns=['From', 'To', 'Val']).sort_values('Val', ascending=False) for h in rng]
b[0][:3]
| From | To | Val | |
|---|---|---|---|
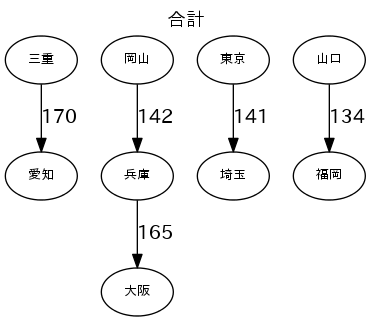
| 1080 | 三重 | 愛知 | 170322.9506 |
| 1268 | 兵庫 | 大阪 | 165543.7879 |
| 1499 | 岡山 | 兵庫 | 142949.9022 |
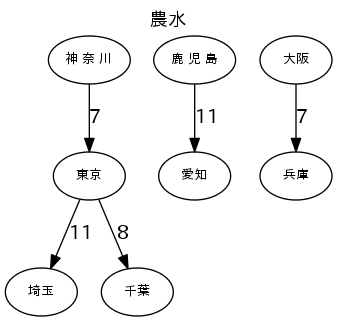
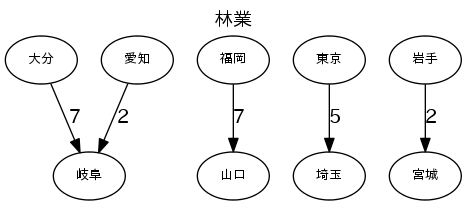
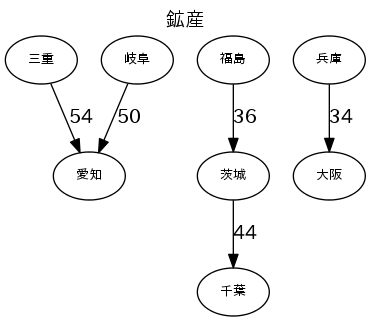
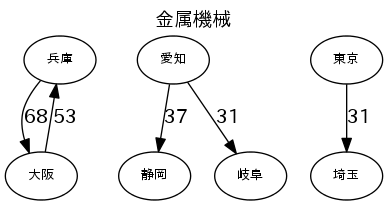
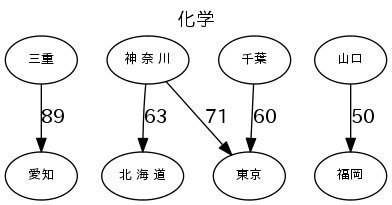
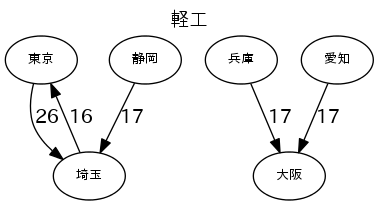
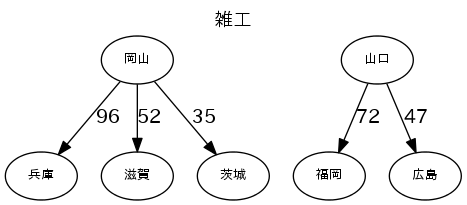
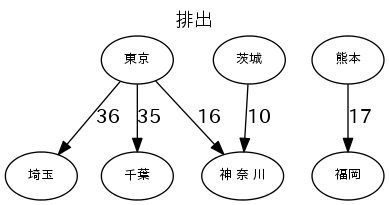
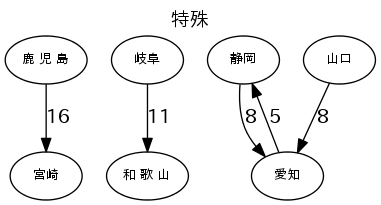
各産業のトップ5の流量で図を描く
図は、"fig_産業.png"で出力する。流量の数字は、1000トン/年。
python3
from graphviz import Digraph
from IPython.display import display
for h, c in zip(rng, cat):
g = Digraph(format='png')
g.attr('graph', label=c, labelloc='t')
g.node_attr['fontsize'] = '10'
for _, r in b[h][:5].iterrows():
g.edge(r.From, r.To, label='%d'%(r.Val//1000))
g.render('fig_%s'%c)
display(g)
以上