TensorFlowで学習プロセスを分ける際,変数のsave/restoreが必要になるが,これはTensorFlowでは tf.train.Saver クラスがサポートしている.モデルのスケールが小さければ使用する変数全部をsave/restoreしてもよいが,モデルが大きくなると本当に必要な変数だけをsave/restoreしたくなってくる.
本記事では,手書き数字分類MNISTを例に,変数のsave/restore方法について確認していく.
(環境は,Python 2.7.11, tensorflow 0.8.0 になります.)
必要な変数にtrainable=Trueをつける
何が必要かについてはプログラムの内容によっていろいろな状況が考えられる.一番簡単なのは,使った変数全体(tf.Variableクラス変数)をsaveするやり方である.
chkpt_file = '../MNIST_data/mnist_cnn.ckpt'
# Create the model
def inference(x, y_, keep_prob, phase_train):
(中略)
ネットワークモデルの構築など.
return loss, accuracy, y_pred
if __name__ == '__main__':
(中略)
loss, accuracy, y_pred = inference(x, y_,
keep_prob, phase_train)
#
# Sessionに入る前に,saver 操作(ops)を引数無しで定義しておく
#
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
if restore_call:
# Restore variables from disk.
saver.restore(sess, chkpt_file)
if TASK == 'train':
print('\n Training...')
for i in range(5001):
(学習プロセス)
# Save the variables to disk. 最後にディスクに書く
if TASK == 'train':
save_path = saver.save(sess, chkpt_file)
print("Model saved in file: %s" % save_path)
上記の通り,引数なしで "tf.train.Saver()" を用いて操作(ops)を定義し,そのsaveメソッドでtf.Variable全体を保存することができる.(注.tf.placeholderで定義したものについては,対象外である.)
しかしながら,ニューラルネットワークのシンプルなモデルでは,各ユニットの重み wとバイアス bがあれば十分というケースがほとんどである.ここでお勧めなのが,変数定義においてtrainableフラグをつけるやり方である.
以下,畳込み層のクラス定義とフル結合層のクラス例である.
class Convolution2D(object):
'''
constructor's args:
input : input image (2D matrix)
input_siz ; input image size
in_ch : number of incoming image channel
out_ch : number of outgoing image channel
patch_siz : filter(patch) size
weights : (if input) (weights, bias)
'''
def __init__(self, input, input_siz, in_ch, out_ch, patch_siz, activation='relu'):
self.input = input
self.rows = input_siz[0]
self.cols = input_siz[1]
self.in_ch = in_ch
self.activation = activation
wshape = [patch_siz[0], patch_siz[1], in_ch, out_ch]
w_cv = tf.Variable(tf.truncated_normal(wshape, stddev=0.1),
trainable=True)
b_cv = tf.Variable(tf.constant(0.1, shape=[out_ch]),
trainable=True)
self.w = w_cv
self.b = b_cv
self.params = [self.w, self.b]
(中略)
# Full-connected Layer
class FullConnected(object):
def __init__(self, input, n_in, n_out):
self.input = input
w_h = tf.Variable(tf.truncated_normal([n_in,n_out],
mean=0.0, stddev=0.05), trainable=True)
b_h = tf.Variable(tf.zeros([n_out]), trainable=True)
self.w = w_h
self.b = b_h
self.params = [self.w, self.b]
(中略)
重み,バイアスに当たる変数 (w_cv, b_cv), (w_h, b_h) を宣言する際,‘trainable=True‘ (訓練可能)を付けている.このひと手間により,後で訓練可能変数のみを集めることができるようになる.
if __name__ == '__main__':
(略)
vars_to_train = tf.trainable_variables()
if os.path.exists(chkpt_file) == False:
restore_call = False
init = tf.initialize_all_variables()
else:
restore_call = True
vars_all = tf.all_variables()
vars_to_init = list(set(vars_all) - set(vars_to_train))
init = tf.initialize_variables(vars_to_init)
saver = tf.train.Saver(vars_to_train)
with tf.Session() as sess:
(後略)
上のコードでポイントは,
tf.trainable_variables() でtrainable=Trueの変数を,tf.all_variables()で宣言した変数全体を集めたところである.変数の集合のイメージは下のようになる.
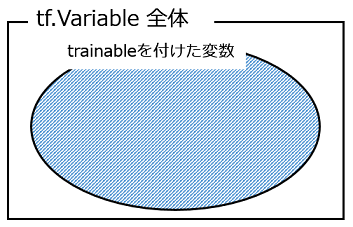
最初のプロセスで,trainableを付けた変数のみを保存し,2回目以降のプロセスでは,この保存した変数をrestoreして用いる.但し,save/restoreしない変数については(2回目以降も)初期化を行う,という流れである.
ここで,保存したファイルのサイズを比較しておく.
-rw-rw-r-- 1 52404005 5月 31 09:54 mnist_cnn.all_vars
-rw-rw-r-- 1 13100491 5月 22 09:15 mnist_cnn.trainable
あくまで一例であるが,保存ファイルが1/4と小さくできた.
(上のファイルは,mnist_cnn.ckpt からファイル名を変更しています.)
名前空間を用いて変数を集めるやり方
次に別のやり方,変数の名前空間を用いて変数を集め,save/restoreするやり方を紹介する.TensorFlowでは,Graph(モデル構成)の可視化のため,名前空間を定義しながらGraph構築を進めることがあると思うが,この名前空間を用いて,定義した変数を集めることができる.
次の例は,畳込み層に追加したbatch normalizationのところで用いた変数を集めたやり方である.
def batch_norm(x, n_out, phase_train):
with tf.variable_scope('bn'):
(batch normalizationの処理,いろいろ)
return normed
# Create the model モデル構築部分,上の batch_norm()を呼び出している
def inference(x, y_, keep_prob, phase_train):
x_image = tf.reshape(x, [-1, 28, 28, 1])
with tf.variable_scope('conv_1'):
conv1 = Convolution2D(x, (28, 28), 1, 32, (5, 5), activation='none')
conv1_bn = batch_norm(conv1.output(), 32, phase_train)
conv1_out = tf.nn.relu(conv1_bn)
pool1 = MaxPooling2D(conv1_out)
pool1_out = pool1.output()
with tf.variable_scope('conv_2'):
conv2 = Convolution2D(pool1_out, (28, 28), 32, 64, (5, 5),
activation='none')
conv2_bn = batch_norm(conv2.output(), 64, phase_train)
conv2_out = tf.nn.relu(conv2_bn)
pool2 = MaxPooling2D(conv2_out)
pool2_out = pool2.output()
pool2_flat = tf.reshape(pool2_out, [-1, 7*7*64])
(その他の層,省略)
return loss, accuracy, y_pred
# メイン処理
if __name__ == '__main__':
TASK = 'train' # 'train' or 'test'
# Variables
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
phase_train = tf.placeholder(tf.bool, name='phase_train')
loss, accuracy, y_pred = inference(x, y_,
keep_prob, phase_train)
# Train
lr = 0.01
train_step = tf.train.AdagradOptimizer(lr).minimize(loss)
vars_to_train = tf.trainable_variables() # option-1
vars_for_bn1 = tf.get_collection(tf.GraphKeys.VARIABLES, scope='conv_1/bn')
vars_for_bn2 = tf.get_collection(tf.GraphKeys.VARIABLES, scope='conv_2/bn')
vars_to_train = list(set(vars_to_train).union(set(vars_for_bn1)))
vars_to_train = list(set(vars_to_train).union(set(vars_for_bn2)))
if TASK == 'train':
restore_call = False
init = tf.initialize_all_variables()
elif TASK == 'test':
restore_call = True
vars_all = tf.all_variables()
vars_to_init = list(set(vars_all) - set(vars_to_train))
init = tf.initialize_variables(vars_to_init) # option-1
# init = tf.initialize_all_variables() option-2
else:
print('Check task switch.')
saver = tf.train.Saver(vars_to_train)
with tf.Session() as sess:
(以下,TensorFlow のセッション中身)
ここでは,畳込み層1(conv_1)と畳込み層2(conv_2)があってそれぞれbatch normalizationを行っているが,そこで使われる変数を以下のようにtf.get_collection()で集めている.
vars_for_bn1 = tf.get_collection(tf.GraphKeys.VARIABLES, scope='conv_1/bn')
vars_for_bn2 = tf.get_collection(tf.GraphKeys.VARIABLES, scope='conv_2/bn')
今回の例では,inference()で,conv_1, conv_2 の名前空間を定義し,その中で,bn の名前空間をもつ batch_norm() を呼び出しているので,上記のような(ネストされた)名前空間 conv_1/bn, conv_2/bn となっている.
この後,変数のセット(集合)を整理して,「保存するもの」「保存しない(次回以降も初期化する)もの」に分けている.(コードが読みにくいので,分かりやすさを助ける図を添付します.)
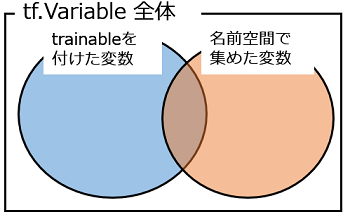
上図で色がついた部分を vars_to_train として tf.train.Saver() に渡すことで必要な変数を保存している.Batch Normalizationを「ブラックボックス的」に導入した際,必要な変数が保存されていないことが原因のbugが発生したが,上記のやり方をとることで,bugをfixできた.
最後に再度ファイルサイズを確認しておく.
-rw-rw-r-- 1 52404005 5月 31 09:54 mnist_cnn.all_vars
-rw-rw-r-- 1 13105573 5月 31 10:05 mnist_cnn.ckpt
-rw-rw-r-- 1 13100491 5月 22 09:15 mnist_cnn.trainable
一番上は,全ての変数を保存したケースで,約52 MB,2番目は,上記のtrainableと名前空間を併用したケースで,約13 MB,3番目は,trainableのみを使ったケースで(bugを含む動作となる),約13 MBとなっている.ファイルサイズの削減は,Diskの使用容量削減のためというより,Disk I/O時間の削減に効果的と考えている.
(最終的なコードをGistにアップしておきます. こちらになります .)
参考文献 (web site)
- Tenforflow documentation, Variables: Creation, Initialization, Saving, and Loading https://www.tensorflow.org/versions/r0.8/how_tos/variables/index.html
- How could I use Batch Normalization in TensorFlow? http://stackoverflow.com/questions/33949786/how-could-i-use-batch-normalization-in-tensorflow
- Tensorflow get all variables in scope - Stack Overflow http://stackoverflow.com/questions/36533723/tensorflow-get-all-variables-in-scope