漫画家の北道正幸氏が2月22日の“猫の日”を記念して,フォント「きたみ字222」を制作・公開している.
http://kitamichi.sub.jp/Sites/iblog/C513573485/E937677024/
(紹介記事:http://www.forest.impress.co.jp/docs/review/20160303_746474.html )
まず初めに,ライセンスを確認しておく.
◆ご使用について
「きたみ字222」はフリーウェアです。
商用以外であれば制限なくご自由に使っていただいてかまいません。ただし「フォントファイル本体」の販売・再配布・加工はご遠慮ください。「きたみ字222」の著作権は北道正幸にあります。
フォント使用によって生じたマシンその他のトラブルには一切の責任を負いません。
(今回,フォントイメージを切り出して機械学習のデータとしましたが,「フォントファイル本体」の加工には当たらないと考えています.→ 北道氏より今回のフォントの使用に関し了承いただきました.)
例えば「あいうえお」「かきくけこ」は,次のような表示になる.
あいうえお

かきくけこ

このように母音の違いに対しては猫の顔の向きで表現し,子音の違いは,毛の模様の違いで表している.直観的に母音「あいうえお」の認識はニューラルネットで構成した分類器(classifier)で割と簡単にやれそうと感じたので,これにトライしてみた.(「あ」と「え」(「か」と「け」)は,やや似た感じに見えていて少し分類しにくそうですが.)
「きたみ字222] はTrueTypeフォントで提供されているので,作業を次の流れで行った.
- Numpyデータに変換するところまでを"Jupyter (ipython) Notebook" + python 3 kernel で処理.
- Numpyデータを読み込み分類するところを"Keras" + "TensorFlow"バックエンド(by python 2).
(プログラミング環境:IPython-notebook 4.0.4, python 3.5.1, numpy 1.10.4, pillow 3.1.1, python 2.7.11, keras 0.3.0, tensorflow 0.7.0 )
フォントイメージの切り出しとpickle保存
2バイトフォント,フォントイメージを扱った経験がほとんどなかったので,調査を含めて,このプリプロセス作業にかなり時間を要した.主な作業は,Pillow(PIL Fork) のImageクラスライブラリで行った.
まず,ライブラリのインポートとフォントの読み込みを実施する.
import numpy as np
import matplotlib.pyplot as plt
from PIL import ImageFont, ImageDraw, Image
%matplotlib inline
font = './kitamiji222_ver101.ttf'
font = ImageFont.truetype(font, 36)
次に必要なイメージのインスタンスを生成し,そこにテキストを書き込む.
text = u'あいうえお'
siz = font.getsize(text)
img1 = Image.new('RGB', siz, (255, 255, 255))
draw = ImageDraw.Draw(img1)
orig = (0, 0)
draw.text(orig, text, (0, 0, 0), font=font)
これを表示して確認.
plt.imshow(img1)
plt.xticks([])
plt.yticks([])
plt.show()

フォントには色情報が必要ないので,グレースケール化する.さらにNumpyマトリクスに変換する.
images = []
siz = (36, 36)
for hira_ch in hiralist:
img_ch = Image.new('RGB', siz, (255, 255, 255))
draw = ImageDraw.Draw(img_ch)
orig = (0, 0)
draw.text(orig, hira_ch, (0, 0, 0), font=font)
img_ch_g = img_ch.convert('L')
images.append(img_ch_g)
def PIL2npmat(img):
return np.array(img.getdata(), np.uint8).reshape(img.size[1], img.size[0])
imgmats = [PIL2npmat(img) for img in images]
最後にpickle形式でファイルに保存する.
import pickle
mydata = [imgmats, codelist]
filename = 'kitamiji222.pkl'
outputfp = open(filename, 'wb')
pickle.dump(mydata, outputfp, protocol=2)
outputfp.close()
上のリストでmydataが保存したいpythonオブジェクトである.今回,python3環境でpickle保存し,python2環境でそれを読み込むという手続きであるが,pickleファイルの互換性を保つために,pickle.dump()にてprotocol=2 を指定している.
MLP(Multi-layer Perceptron)モデルで試行
前述の通り,Deep Learning Framework "Keras"を用いたが,このサンプルコード"mnist_mlp.py"を参考に以下のようにネットワークモデルを定義した.
trXshape = trainX[0].shape
nclass = trainY.shape[1]
hidden_units = 800
model = Sequential() # Sequentialモデルのインスタンス生成
model.add(Dense(hidden_units, input_shape=trXshape)) # 隠れ層の定義
model.add(Activation('relu'))
model.add(Dropout(0.3))
model.add(Dense(hidden_units)) # 隠れ層の定義
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nclass)) # 出力層の定義
model.add(Activation('softmax'))
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08) # オプティマイザの定義
model.compile(loss='categorical_crossentropy', optimizer=optimizer) # コストを選択してモデルコンパイル
今回,5種類の母音の分類なので,ラベルデータ trainY には,事前につけたフォント・コードから算定した['a', 'i', 'u', 'e', 'o']に対応する情報を入れている.(したがって,nclass = 5 である.)
モデルはKerasのSequential型を用い,入力側から出力側に向けて順番に定義していく.入力側から,隠れ層1→隠れ層2→出力層の合計3層のMLPモデルとした.フォントイメージを 36x36 (=1296) としたので,隠れ層のユニット数を800にしている.また,RegularizationにはDropout()を用いている.学習のためのオプティマイザにはAdam()を用いた.
最近のKerasでは,バックエンドに"Theano"または"TensorFlow"を選択できるが,今回は"TensorFlow"を用いた.環境変数をセットすることで,Kerasバンクエンドを指定できる.
export KERAS_BACKEND=tensorflow
初めに,学習用データ(Train data)とテストデータ(Test data)を"ひらがな"から必要数ランダムサンプリングして計算を行った.その計算状況,コストと精度を下図に示す.
Fig. MLP model, Loss and Accuracy
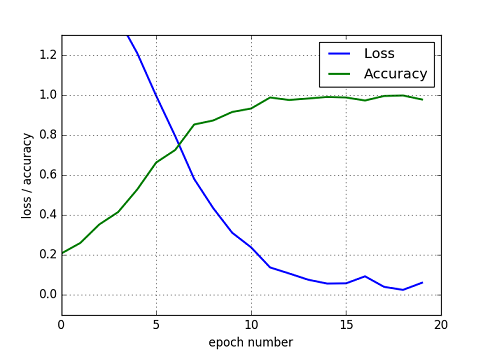
所定epoch回数をこなした後,Lossは0近傍,精度は1.0近傍に収束している.また,この後のTest dataを使った分類でも精度はほぼ1.0 (100%)の値となった.ランダムサンプリングしたとはいえ,Train DataとTest Dataを同じセット,母集団から取ってきているのでTrainとTestで精度に差は生じない.
MLPモデルで「カタカナ」をテスト
学習しただけでは面白くないので,学習用データと別にテストデータを用意することにした.幸い「きたみ字222」にはひらがなとカタカナが用意されてたので,学習用データとしてひらがなのセット,テスト用データとしてカタカナのセットを用いることにした.
それぞれのイメージを対比してみる.
Fig. ひらがな,あ行からた行まで

Fig. カタカナ,ア行からタ行まで

ひらがなとカタカナで同じ音の文字は,かなり形が近いことが観測される.ひらがなとカタカナの違いは口が「閉じている」か「空けている」かで表現されていることが分かった.
ということで,Train dataとTest dataを分けて用意して計算を実施した.
Fig. MLP model, Loss and Accuracy
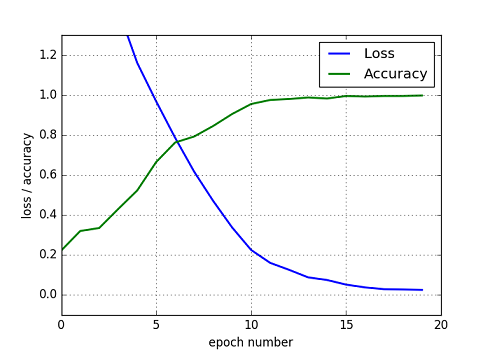
Fig. MLP model, Validation Loss and Validation Accuracy
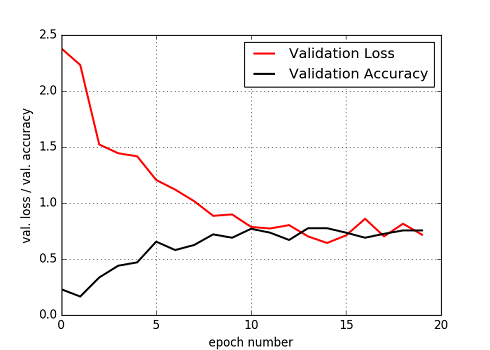
ひらがな(Train data)を用いた学習の状況は前の図とほぼ同じである.カタカナ(Test data)を用いたValidation Loss, Accuracyについてもねらい通りLossが低減し, Accuracyが増加する状況ができている.最終的な精度は,75% の数値となった.
精度を高めるために計算のパラメータを変えて状況をみたが,一番効くのが,ドロップアウトの数値である.ひらがなの顔文字への適合度をうまく調整することで,カタカナの分類精度を上げることができる.教科書で習ったことを顔文字の形状で実感できた次第である.(因みにいろいろ試行してみて良かった結果が上のリストに示したもので,前段のドロップアウト率=0.3, 後段=0.5 である.
CNN(Convolitional Neural Network)でテスト
より良い精度をめざしてCNN(Convolutional Neural Network)モデルを試してみた.少ないコード変更で簡単にモデル変更できるのが,Kerasのようなハイレベルのクラスライブラリのいいところである.以下,コードの主要部分を示す.
nb_classes = trainY.shape[1]
img_rows, img_cols = 36, 36 # image dimensions
trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols)
testX = testX.reshape(testX.shape[0], 1, img_rows, img_cols)
nb_filters = 32 # convolutional filters to use
nb_pool = 2 # size of pooling area for max pooling
nb_conv = 3 # convolution kernel size
model = Sequential() # Sequentialモデルのインスタンス生成
model.add(Convolution2D(nb_filters, nb_conv, nb_conv, # 畳込み層の定義
border_mode='valid',
input_shape=(1, img_rows, img_cols)))
model.add(Activation('relu'))
model.add(Convolution2D(nb_filters, nb_conv, nb_conv)) # 畳込み層の定義
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool))) # プーリング層の定義
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(128)) # フル結合層の定義
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes)) # 出力層の定義
model.add(Activation('softmax'))
optimizer = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08) # オプティマイザの定義
model.compile(loss='categorical_crossentropy', optimizer=optimizer) # コストを選択してモデルコンパイル
入力側から,畳込み層1→畳込み層2→プーリング層→フル結合層→出力層の5層構造となっている.(ご想像の通り,この層構造はサンプル mnist_cnn.py に倣っています.)またオプティマイザは,前回同様Adamを用いている.
計算結果は次のようになった.
Fig. CNN model, Loss and Accuracy
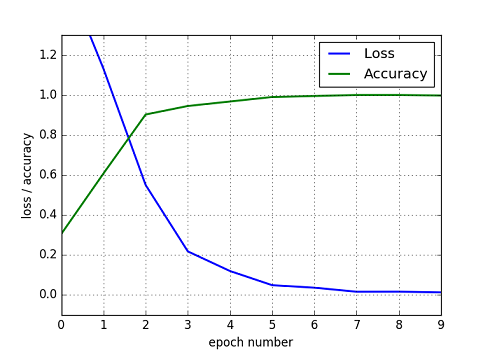
Fig. CNN model, Validation Loss and Validation Accuracy
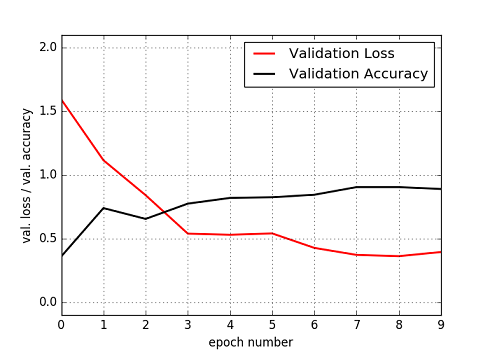
ねらい通り,分類精度が向上している.最終的なTest data(カタカナ)の分類精度は 89% となった.パラメータを調整して頑張ったが 90% 台に乗せることはできなかった.(ドロップアウト率を中心に調べてみましたが.)
手書き数字の分類課題"MNIST"で98 .. 99% の精度を出せることと比較すると,89%はやや残念な結果だが,データセットのサンプル数がMNISTと今回とでは決定的に異なる.(今回のケースでは,ランダムにサンプリングしますが,あくまで種類はフォントセットの中に限られてしまいます.)今回の絵文字分類でさらに精度を上げるには,フォントイメージの加工(変形,ノイズ付加)等,データサンプルを増やす苦労が必要となる.(あるいは,正則化(regularization)のやり方を変えてみるのも多少効果があるかもしれません.)
最後に,機械学習の面白い題材を公開された,北道氏に感謝いたします.
(別に機械学習を意識してフォントを作られたわけではないとは承知していますが,遊べました!!!)
参考文献 (web site)
- 4コマ漫画『プ~ねこ』の作者が制作した猫の絵文字フォント「きたみ字222」
http://www.forest.impress.co.jp/docs/review/20160303_746474.html - Pillow (PIL Fork) documentation
https://pillow.readthedocs.org/en/3.1.x/ - Load pickle file(comes from python3) in python2 - stackoverflow
http://stackoverflow.com/questions/29587179/load-pickle-filecomes-from-python3-in-python2 - 深層学習 - 講談社 機械学習プロフェッショナルシリーズ
- Keras Documentation http://keras.io/
- Keras as wrapper of Theano & TensorFlow - Qiita
http://qiita.com/TomokIshii/items/7de052565719add8e8ad