前記事でTensorFlowのTutorialコードとして,Neural Networkの基本MLP(Multi-layer Perceptron)のコードを紹介した.今回は,そのコードを発展させる形でTensorFlowの諸機能について調べてみた.
コードの変更点は以下の通り.
- 活性化関数を tf.sigmoid() から tf.nn.relu() に変えた.
- オプティマイザーを勾配降下法(Gradient Descent)のものからAdagrad法のものに変更.
- 2層レイヤーから3層レイヤーに変更.
- TensorBoardの機能を使い,学習カーブをプロットしてみた.
(プログラミングの環境は,Python 2.7.10, tensorflow 0.5.0 になります.)
"Wine"データセットの概略
季節がら(?) "Wine" データセットを用いることにした.UCI Machine Learning Repositoryでも現時点で人気第3位である.データには,13の特徴量(Attribute)が含まれている.(特徴量の詳細については,調べていません.アルコールとかマグネシウムとかいくつかは名前だけで分かりますが.)
-- Attributes
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
これらの特徴量をつかってWineを3つのクラスに分ける多クラス分類問題である.(これも番号が大きい方がいいのか,小さい方がいいのかよくわかっていません.)
-- Number of Instances
class 1: 59
class 2: 71
class 3: 48
このようなデータセットを扱うために入力層13ユニット,出力層3ユニットのMLPモデルを用意して分類を行った.当初は,お手本通り確率的勾配降下法でmini-batchのデータ供給を行うつもりであったが,データの総数が178しかないので,ループ内計算で一括してデータを与えるBatch Gradient Descentの手法をとることにした.
コードの詳細説明
初めに活性化関数にReLU (rectified linear unit) を導入しようとして,TensorFlowのドキュメントを調べたところ,
- tf.nn.relu()
- tf.nn.relu6()
の2種類が記載されていた.この relu6() について知識がなかったので,Jupyter Notebookで関数をプロットしてみた.
Fig. "tf.nn.relu()" & "tf.nn.relu6()"
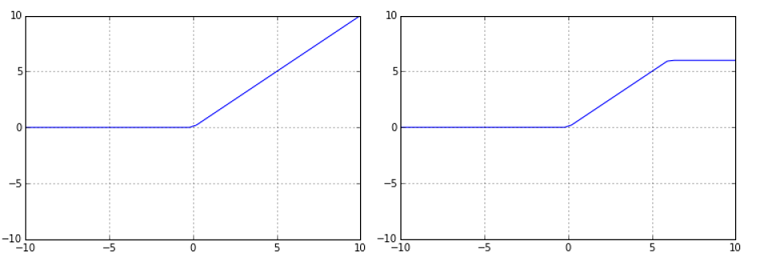
上図の通り,普通のReLUではxが+方向に増加するのに従いyも増加しているが,ReLU6では,y=6.0 で飽和するような関数となっている.(飽和ポイントのディフォルト値がy=1.0 はなくy=6.0である理由がよくわかりません...)今回は,よく使われている関数 (tf.nn.relu())を用いることとした.
これを含めて隠れ層(Hidden Layer)のコードを次のようにした.weightの初期化は,前回同様,tf.random_normal() を使って正規分布のランダム値を発生させている.
# Hidden Layer
class HiddenLayer(object):
def __init__(self, input, n_in, n_out):
self.input = input
w_h = tf.Variable(tf.random_normal([n_in,n_out],mean=0.0,stddev=0.05))
b_h = tf.Variable(tf.zeros([n_out]))
self.w = w_h
self.b = b_h
self.params = [self.w, self.b]
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.nn.relu(linarg) # switch sigmoid() to relu()
return self.output
また出力層については,"MNIST"と同様 "Wine"分類問題も「多クラス分類」のケースなので,活性化関数にはSoftmax関数を用いている.(わずか3クラスですが,「多クラス」になります.)
# Read-out Layer
class ReadOutLayer(object):
def __init__(self, input, n_in, n_out):
self.input = input
w_o = tf.Variable(tf.random_normal([n_in,n_out],mean=0.0,stddev=0.05))
b_o = tf.Variable(tf.zeros([n_out]))
self.w = w_o
self.b = b_o
self.params = [self.w, self.b]
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.nn.softmax(linarg)
return self.output
これらのネットワーク層をモデル化した2つのクラスを用いて,MLPの構成をプログラムで定義した.(コードは後ろに掲載します.)
また,変更したオプティマイザーAdagradであるが,単に関数名(オプティマイザー名)をGradientDescentOptimizerからAdagradOptimizerに変更するだけで済んでしまった.
# Train
optimizer = tf.train.AdagradOptimizer(0.01)
train_op = optimizer.minimize(loss)
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
. . .
ただ1点,注意を要するのが,オプティマイザーの定義と変数初期化のタイミングである.上のコードには明示的にならないが,AdagradOptimizer() はプログラムで指定されると,内部で用いるパラメータ用の変数(tf.Variable)を生成するとのことである.従って,TensorFlowの変数初期化プロセス(tf.initialize_all_variables())はその後に行わなければならない.仮に,順番を入れ換えて,
# Train (ERROR)
init = tf.initialize_all_variables()
optimizer = tf.train.AdagradOptimizer(0.01)
train_op = optimizer.minimize(loss)
とやってしまうとエラーとなるので要注意である.(当初,ここでデバッグに手間取りました.stackoverflow.com で上記解決策を得ました.)
TensorBoardで計算プロセス表示
何事も初めてだと動かすまでにいろいろ手間取るが,下がうまく動作したコードになる.(TensorBoard関連箇所に "T.B."のコメントを入れています.)
(前略)
loss, accuracy = mk_NN_model()
logloss = tf.scalar_summary('loss_w_L2', loss) # T.B.
logaccu = tf.scalar_summary('accuracy', accuracy) # T.B.
summary_op = tf.merge_summary([logloss, logaccu]) # T.B.
# Train
optimizer = tf.train.AdagradOptimizer(0.01)
train_op = optimizer.minimize(loss)
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
summary_buff = tf.train.SummaryWriter('/tmp/tf_logs',
graph_def=sess.graph_def) # T.B.
print('Training...')
for i in range(10001):
train_op.run({x: train_x, y_: train_y})
if i % 100 == 0: # for T.B. logging
summary_str = sess.run(summary_op, {x: train_x, y_: train_y})
summary_buff.add_summary(summary_str, i)
if i % 1000 == 0: # echo status on screen
train_accuracy = accuracy.eval({x: train_x, y_: train_y})
print(' step, accurary = %6d: %8.3f' % (i, train_accuracy))
(後略)
ログ記録ためのの手続きとしては次の通り.
- tf.scalar_summary() で記録したい変数を指定する.
- tf.merge_summary() で変数をまとめる.それを使って操作(summary_op)オブジェクトとする.
(セッションを起動後...) - tf.train.SummaryWritere()で,ログを入れるディレクトリを指定,サマリ用のバッファを確保する.
- sess.run(summary_op, {feed_dict}) に操作オブジェクト(summary_op)を渡してサマリ文字列を生成.
- 生成した文字列を add_summary() で記録.
デバッグに時間をとられたのは,上の4番めのプロセス,sess.run() で文字列を作るところである.当初,訓練データのfeed_dictを与えていなかったが,動作しなかった.
(誤)
if i % 100 == 0: # for T.B. logging
summary_str = sess.run(summary_op) # <--- {feed_dict} が与えられていない
summary_buff.add_summary(summary_str, i)
(正)
if i % 100 == 0: # for T.B. logging
summary_str = sess.run(summary_op, {x: train_x, y_: train_y})
summary_buff.add_summary(summary_str, i)
このプロセスの詳細については理解できていないが,TensorBoard用に記録を取る場合には,上記のようにsess.run()に訓練データ(feed_dict)を指定しなければいけないというルールは覚えておく必要がある.
以上,プログラムを実行した結果を以下に示す.
Training...
step, accurary = 0: 0.258
step, accurary = 1000: 0.944
step, accurary = 2000: 0.984
step, accurary = 3000: 0.984
step, accurary = 4000: 0.984
step, accurary = 5000: 0.992
step, accurary = 6000: 0.992
step, accurary = 7000: 0.992
step, accurary = 8000: 0.992
step, accurary = 9000: 0.992
step, accurary = 10000: 0.992
accuracy = 0.944444
TensorBorad Plot (Loss with L2 term), (Accuracy)
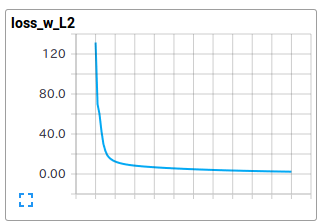
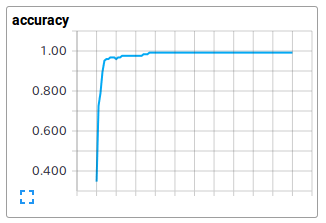
loss_w_L2 は,L2正則化項を加えたコスト関数,accuracyは精度を示す.
約10,000回の反復計算を実施しているが,実際には4,000-5,000回ぐらいで十分な精度が得られているように見える.ランダムシャッフル後に訓練データとテストデータに分割する処理上,結果はばらつくが,約94 ~ 95% の分類精度となった.
全体コード
以上をまとめて,コードの全体を記載する.
"input_data.py"
import numpy as np
import pandas as pd
def load_data(filename):
# Shuffle data by row
def data_shuffle(xm, ym, siz):
idv = np.arange(siz)
idv0 = np.array(idv) # copy numbers
np.random.shuffle(idv)
xm[idv0] = xm[idv]
ym[idv0] = ym[idv]
x_new = np.zeros_like(xm)
y_new = np.zeros_like(ym)
x_new[idv0,:] = xm[idv,:]
y_new[idv0] = ym[idv]
return x_new, y_new
# Split dataset to train data and test data
def split_data(xm, ym, tr_ratio, te_ratio):
tot = len(ym)
itr = int(tot * tr_ratio / (tr_ratio + te_ratio))
return xm[:itr,:], ym[:itr,:], xm[itr:,:], ym[itr:,:]
mydf = pd.read_csv(filename, header=None)
mydf.dropna(inplace=True)
xdata = (mydf.iloc[:, 1:]).values # Wine features
iydata = (mydf.iloc[:, 0]).values # Wine class (1, 2, 3)
m = len(iydata)
data_shuffle(xdata, iydata, m)
ydata = np.zeros((m, 3))
for i in range(m):
ic = int(iydata[i] - 1)
ydata[i, ic] = 1.0
xtr, ytr, xte, yte = split_data(xdata, ydata, 0.7, 0.3)
return xtr, ytr, xte, yte
"wine_classifier.py"
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
# Import data
from input_data import load_data
# Hidden Layer
class HiddenLayer(object):
def __init__(self, input, n_in, n_out):
self.input = input
w_h = tf.Variable(tf.random_normal([n_in,n_out],mean=0.0,stddev=0.05))
b_h = tf.Variable(tf.zeros([n_out]))
self.w = w_h
self.b = b_h
self.params = [self.w, self.b]
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.nn.relu(linarg) # switch sigmoid() to relu()
return self.output
# Read-out Layer
class ReadOutLayer(object):
def __init__(self, input, n_in, n_out):
self.input = input
w_o = tf.Variable(tf.random_normal([n_in,n_out],mean=0.0,stddev=0.05))
b_o = tf.Variable(tf.zeros([n_out]))
self.w = w_o
self.b = b_o
self.params = [self.w, self.b]
def output(self):
linarg = tf.matmul(self.input, self.w) + self.b
self.output = tf.nn.softmax(linarg)
return self.output
# Create the model
def mk_NN_model():
# Define network structure
h_layer1 = HiddenLayer(input=x, n_in=13, n_out=20)
h_layer2 = HiddenLayer(input=h_layer1.output(), n_in=20, n_out=20)
o_layer = ReadOutLayer(input=h_layer2.output(), n_in=20, n_out=3)
# Cost Function basic term
out = o_layer.output()
cross_entropy = -tf.reduce_sum(y_*tf.log(out), name='xentropy')
# Regularization terms (weight decay)
L2_sqr = (tf.nn.l2_loss(h_layer1.w)
+ tf.nn.l2_loss(h_layer2.w)
+ tf.nn.l2_loss(o_layer.w))
lambda_2 = 0.01
# the loss and accuracy
loss = cross_entropy + lambda_2 * L2_sqr
correct_prediction = tf.equal(tf.argmax(out,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
return loss, accuracy
if __name__ == '__main__':
train_x, train_y, test_x, test_y = load_data('./wine.data')
# Variables
x = tf.placeholder("float", [None, 13])
y_ = tf.placeholder("float", [None, 3])
loss, accuracy = mk_NN_model()
logloss = tf.scalar_summary('loss_w_L2', loss) # T.B.
logaccu = tf.scalar_summary('accuracy', accuracy) # T.B.
summary_op = tf.merge_summary([logloss, logaccu]) # T.B.
# Train
optimizer = tf.train.AdagradOptimizer(0.01)
train_op = optimizer.minimize(loss)
init = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init)
summary_buff = tf.train.SummaryWriter('/tmp/tf_logs',
graph_def=sess.graph_def) # T.B.
print('Training...')
for i in range(10001):
train_op.run({x: train_x, y_: train_y})
if i % 100 == 0: # for T.B. logging
summary_str = sess.run(summary_op, {x: train_x, y_: train_y})
summary_buff.add_summary(summary_str, i)
if i % 1000 == 0: # echo status on screen
train_accuracy = accuracy.eval({x: train_x, y_: train_y})
print(' step, accurary = %6d: %8.3f' % (i, train_accuracy))
# Test trained model
print('accuracy = ', accuracy.eval({x: test_x, y_: test_y}))
まだTensorFlowフレームワークの一部機能しか使っていないが,Neural Network モデルを実装する上で,キーとなるところは,かなりカバーできたのではないかと考えている.
参考文献 (web site)
- TensorFlow ドキュメント http://www.tensorflow.org/
- 深層学習(講談社 機械学習プロフェッショナルシリーズ)
http://www.kspub.co.jp/book/detail/1529021.html - 落ちこぼれないためのTensorFlow Tutorialコード - Qiita
http://qiita.com/TomokIshii/items/92a266b805d7eee02b1d - UCI Machine Learning Repository: Wine Data Set
https://archive.ics.uci.edu/ml/datasets/Wine - Tensorflow: Using Adam optimizer - stackoverflow
http://stackoverflow.com/questions/33788989/tensorflow-using-adam-optimizer