原文
1. 要約
- CNNで鍛えた画像認識の識別器(Deep Architecture)を、テストデータ以外の汎用的なデータにも適用できないか、ということにチャレンジした。
- DeCAFは、ここで鍛えた識別器の略称である。
- この手の識別器の発展という視点では、Krizhevskyらによる研究成果を進化させた。彼らのモデルは、5層の畳込み層(間にReLUの活性化、プーリング層あり)、3層の完全結合層からなる。1000パターンほどの識別が可能。
2. 骨子の理論
基本的な理論構成は、従来のCNNと変わらない。
メイン手法の仕事としては、畳込みの層を7層に拡張したくらいである。
本稿では、3.のモデル適用に際してのテクニックのインプットの方に価値を置く。
3. モデル適用例
(1)画像認識
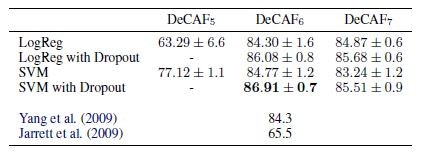
畳込み層増築に、ロジスティック回帰とDropoutを組み合わせて、性能向上を確かめた。
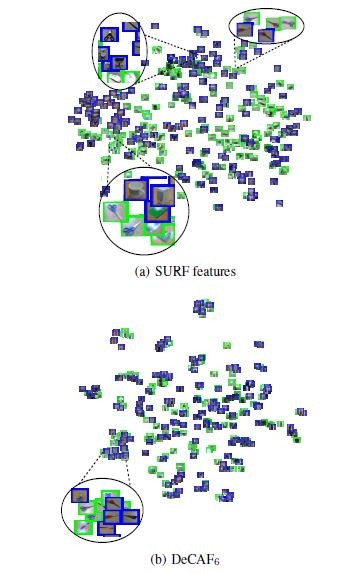
(2)ドメイン( = 特徴量の領域をベクトル量に基いて投射したもの)の適合
DeCAFにt-SNEというアルゴリズムを施して、2Dの投射領域図を作成した。すると、対象のSURFの図に対して良好な再現性を得られた。
(3)サブカテゴリ認識
画像の各部の特徴も認識し分けるというもの。
-
クロッピングアプローチ:
データの画像を切り分けて、それから基本サイズに拡張し直すこと(部分を改めてひとつの画像と見て、パターン認識するケース) -
可変型部分記述法 (Deformable Part Descript: DPD):
1画像内に見られる弱い特徴ごとに、領域を検知する(図の青い枠線)。それぞれを分離して、その特徴を記述するというもの 6層の畳込みにDPDを加えたものが、良好な結果を示した。

