原文
強化学習における自己符号化器付き深層ニューラルネットワーク(Deep Auto-Encoder Neural Networks in Reinforcement Learning)
Sascha Lange and Martin Riedmiller (2010)
1. 要約
- (メモリ基盤の)バッチ強化学習(Reinforcement Learning; RL)アルゴリズムを考案した。これにより、自己符号化器でDNN (Deep Neural Network)を学習し、特徴空間を創出することができる。
- メインの機械学習アルゴリズムは、MLP(Multi Layer Perceptions) 、いわゆる多層自己符号化器を使う。
2. 背景
強化学習は、次の2ステップからなる。
①入力データから特徴を抽出する
②特徴空間から、教義(Policy)を学び、行動に落としこむ
これまで、①は人の手で行われてきたが、Deep Learningが取って代わるように期待されている。
3. 骨子の理論
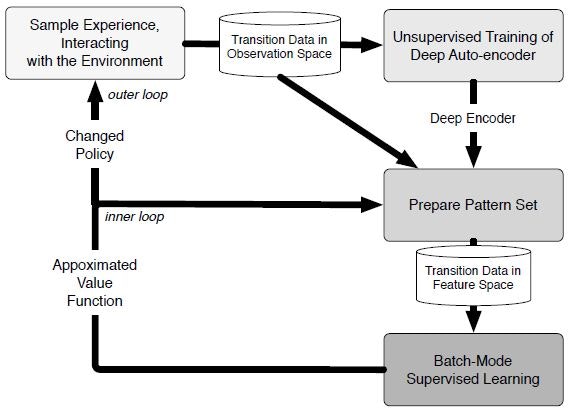
全体の分析構図を以下に示す。
ポイントは、DLで取得した特徴空間を、従来のRLの学習アルゴリズム(Fitted Q-Iteration)に組み込む点である。
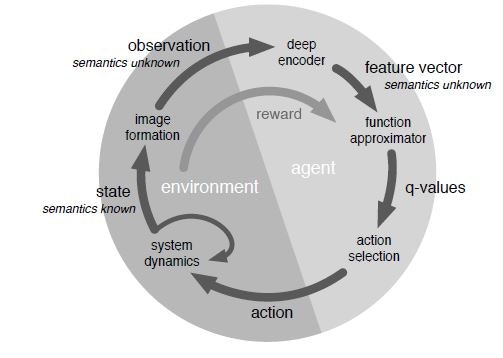
強化学習の基礎は、他書に譲るが、エージェント(学習する主体)は、Q値(関数)を貪欲法(Greedy method)という計算規則で算出し、その値に基いて、行動規範(Policy)を決定する。
3. モデル適用例
6*6=36ピクセルの画像を用意し、アルゴリズムのもとで事前学習(特徴抽出)。
400エポックで、分類が完成した。
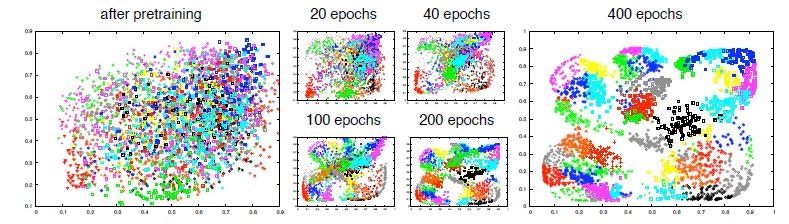
上図の分類は、自己符号化器の文脈で行われている。入力データの再構成時の元データとの誤差について、その他の手法と比較した。
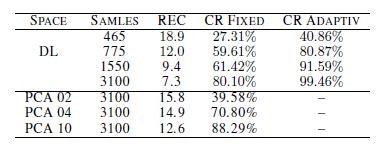
主成分分析に比べて、誤差が拮抗している点もある。
だが、マニュアルの特徴抽出が可能な点で、この手法の優位性が立つ。
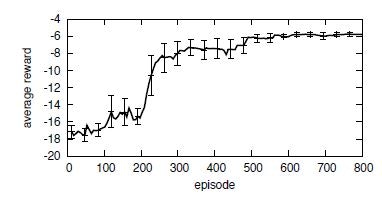
最後に、学習させたパターンに基づき、エージェントに行動させた時の報酬(Reward)関数の結果を示す(これは強化学習の文脈)。
300回あたりで、極大に近づき、600エピソード経過したところで、ほぼ最大報酬に収束した。