原文
人間の行動認識のための3次元CNN (3D Convolutional Neural Networks for Human Action Recognition)
Shuiwang Ji (2013)
1. 要約/背景
- CNNの3Dの人間の動きを学習させた点がこの論文の差別化の点である。これまでは、2Dの特徴抽出がある程度コントロールされたデータの使用が関の山だった。
2. 骨子の理論
(1)3DCNNの畳込み層の一般的な定式化
m番目のフィルタリングによって、$(i-1)$層のフィルタポジション$(p,q,r)$が$i$層の映像$(x,y,z)$に与える影響を一般的に表現すると、次のようになる。
v_{i,j}^{xyz} = \tanh \Big( b_{ij} + \sum_{m}\sum_{p=0}^{P_i-1}\sum_{q=0}^{Q_i-1}\sum_{r=0}^{R_i-1}w_{ijm}^{pqr}v_{(i-1)m}^{(x+p)(y+q)(z+r)} \Big)
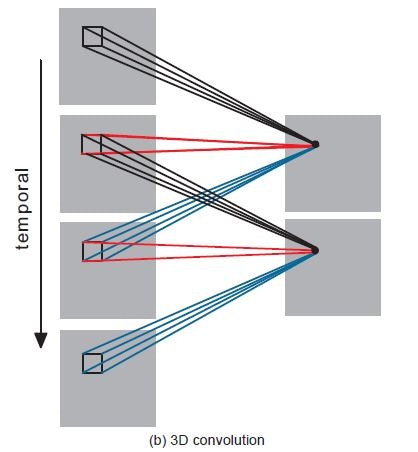
3Dの畳み込みの方法にも、特徴がある。
2Dでは、1方面の情報のみ畳み込んでいたが、3Dでは、様々な角度から捉えた情報を系列的に取り込んで、それを次の層に抽出していく(下図)。
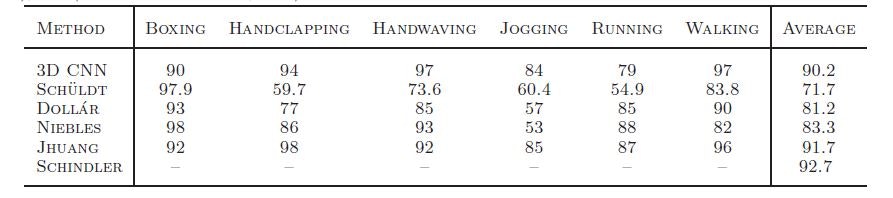
3. モデル適用例
HMAXという動画サンプルの分類を行った。
6種類の人間の動きを分類するものだが、識別率はトップレベルに拮抗するものの目覚ましい違いが出る感じではなかった。