原文
多予測性DBM (Multi-prediction deep Boltzmann machines)
Ian J. Goodfellow, Mehdi Mirza, Aaron Courville, Yoshua Bengio (2013)
1. 要約/背景
- MP-DBMは、一般尤度関数の変分近似で一価確率モデルを学習したものである。
- 多層化の際、貪欲法による積層化の処理が必要なくなる点で、斬新である。
従来の積層に比べて、次のようなメリットがある- 上層が下層の影響を汲み取りやすい
- 多様な確率モデルを適用できる
- 複層計算によるコストを防げる
2. 骨子の理論
(1)Multi-prediction training
MPTは、平均場近似を使い、再帰ネットワークを誘起する学習方法である。
対応モデルとして
- 1. 可変基準を持つ一価確率モデル
- 2. 再帰ネットワーク群
が挙げられる。
学習の際に観測される全ての変数群を$O$とする。$Q_i$を$i$番目の変数予測のための汎関数と取ると、$i$番目の変数予測の変分近似は次のように表される。
Q_i(O_{S_i},h) = \arg\min_QD_{KL}(Q(O_{S_i},h)||P(O_{S_i},h|O_{-S_i}))
すなわち、同時分布と、$i$番目を除いた系による条件分布とのカルバック・ライブラー・ダイバージェンスの最小化に等しい。
MPDBMの学習のコツは、RBMを積み上げてDBMを作った後に、RBM時代のパラメータ群$\theta$を全て棄却し、DBM全体で学習し直す点である。平均場近似を使って、隠し変数を推定する。その上で、パラメータ$\theta$を推定し直す(Multi Layer Perceptron)
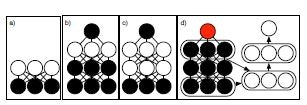
下図は、ミニバッチでMulti-predictionトレーニングをする挙動の様子を表す。
各段で、それぞれの学習例を示す。
黒丸は、そのネットワークが観測できる変数を表す。それに対し、青丸で予測された特徴が表現される。
これらの要素は、緑矢印で表現される関連性があってこそ、それぞれの挙動を発揮する。

3. モデル適用例
MNISTやNORBのテストでは、調整されたDBMよりやや効果的な結果が出た。