原文
DBMを用いた多形態データの学習(Multimodal Learning with Deep Boltzmann Machines)
Nitish Srivastava (2012)
1. 要約/背景
- 画像と文字の混合データにDBMを適用したら、良好な結果を得られた。
- テキストと画像では抽出データの型が異なるため、もともと併用が難しい
テキスト→語数カウントベクトルであり、成分は離散的かつスパースである。
画像→ピクセルに分割し、各点の輝度をベクトルにまとめる。
- SVMとLDA→混合データの認識に使われるが、教師データがない場合、特徴抽出ができない…
混合データによる学習イメージを下に示す。
画像をインプットした時に、意味(タグ登録してある)を選択識別する感じ。

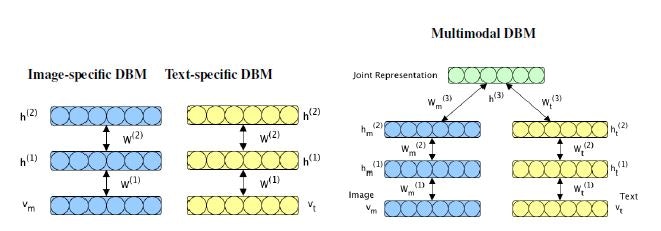
2. 骨子の理論
分析過程の模式図を以下に示す。
ポイントは、画像の特徴とテキストの特徴をそれぞれ別のDBMで学習させることである。
その上で、統合DBMで総合的な特徴抽出をする。
画像DBMとテキストDBMを統合する式は次のようになる。
(それぞれのボルツマン分布の定式化に特別な特徴はない)
P({\bf v}^m, {\bf v}^t; \theta) = \sum_{{\bf h}_m^{(2)}, {\bf h}_t^{(2)}, {\bf h}^{(3)}}P({\bf h}_m^{(2)}, {\bf h}_t^{(2)}, {\bf h}^{(3)})\Big( \sum_{{\bf h}_m^{(1)}}P({\bf v}_m, {\bf h}_m^{(1)}, {\bf h}_m^{(2)})\Big)\Big( \sum_{{\bf h}_t^{(1)}}P({\bf v}_t, {\bf h}_t^{(1)}, {\bf h}_t^{(2)})\Big)
積形式において、
第一項:2つの隠れ変数の統合層における同時分布
第二項:画像DBMにおける変数の同時分布
第三項:テキストDBMにおける変数の同時分布
すなわち、以上のファクターの積が、Multimodalケースの可視変数のボルツマン分布になる。
計算テクニックとしては、MCMCと平均場近似を併用した。
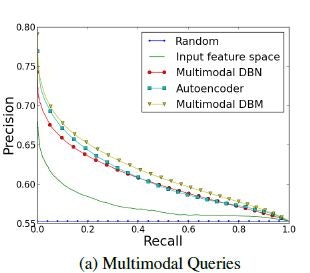
3. モデル適用例
1000枚のテキスト画像混合データを用意し、38クラス分類を学習させる。
適合判定関数に、コサイン類似関数を用いる。
5000枚のテストデータを元に行った試験結果が下のようになる;