原文
1. 要約/背景
- 多語彙音声認識において、DBN (Deep Belief Network)による事前学習と隠れマルコフモデルを組み合わせた学習器を開発した。
- 本稿発表前までの主流は、混合ガウスモデルを事前学習に用いるスタイルだったが、それをDBNに置き換えた。DBNは、事前学習のみに用いる点も特徴である。
2. 骨子の理論
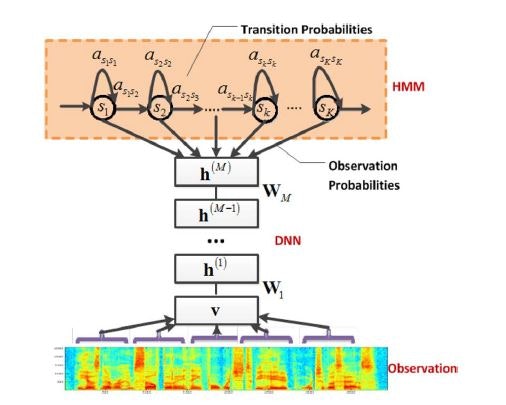
(1)DBNによる事前学習
積層RBMの学習で表現する。音声データは実数連続値を取るので、Gaussian RBMを用いる。
P({\bf v}|{\bf h}) = N({\bf v}; {\bf b} + {\bf h}^T{\bf W}^T, I)
(2)HMMによる信号の並びの予測
(1)の事前学習で抽出された特徴量は、繰り返し想起された確率モデルに当てはめられる(Generative Model; 生成モデル)。当てはめられた確率分布のうち、尤もらしいものが学習結果により決定される。
確率分布の型は、隠れマルコフモデルに基づく。
HMMで表現していることは、3音素(Senone)が「ある遷移確率」に制御されて移り変わる挙動である。
当てはまりの良いときのパラメータwが新しいパラメータとして更新される;
\hat w = \arg\max_w p(w|{\bf x}) = \arg\max_w p({\bf x}|w)p(w)/p({\bf x})
3. モデル適用例
5層の隠れ層・2000超のユニットを備えたDNNと、GMMによる性能の違いを確かめた。
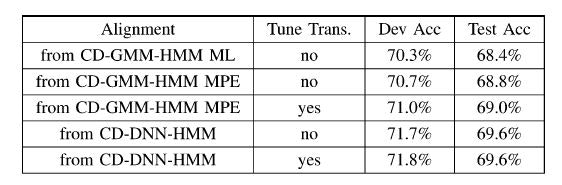
目覚しい変化があるとは言えないが、若干の変化は認められた。
課題は、計算時間である。
並列処理が難しい構造のため、時間省力化が難しい。