AWS Athenaは表題の通り、S3にあるファイルをSQLで検索できるAWSのサービスで、
内部にはPrestoが使用されているそうです。
Athenaの利用
Athenaは東京リージョン(ap-northeeast-1)に対応していないので、東京リージョンからAthenaを選択すると、
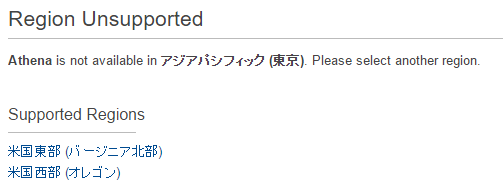
と出ますが、対応しているリージョンを選択すればいいので使用することに問題はありません。
Atenaを利用するリージョンと異なるリージョンにあるS3バケットも、検索の対象にすることができます。
注意:
AthenaのリージョンとS3のリージョンが異なる場合、リージョン間通信料金がかかります。
詳しくは、S3の料金についてを参照ください。
テーブルの作成
今回は、米国東部リージョンを利用しました。
Athenaが利用可能だと以下のような画面が表示されます。
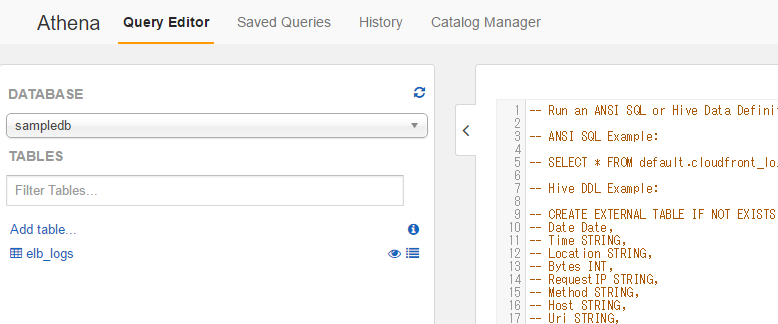
Query実行欄があるので直接Queryを書いてテーブルを作ることもできますが、
Hiveの記法で書く必要があり、Hiveを知らないので、
CatalogManagerに従ってテーブルを作成します。
CatalogManagerを押下して遷移する以下の画面で、Add tableを押下します。
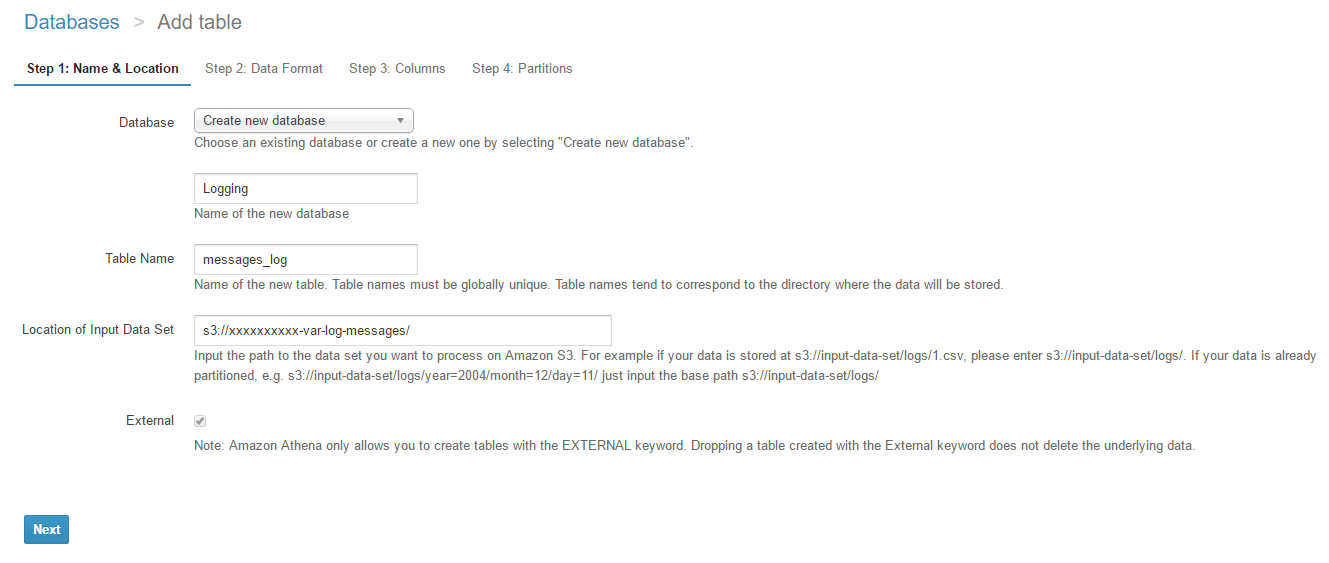
Name & Location
この画面では、作成するテーブルを配置するデータベースやテーブル名、
およびテーブルの元になるS3バケットのパスを指定します。
今回、テーブルを作成した時のバケット構成は以下の通りです。
(CloudWatch Logs + AWS Lambda で日付ごとインスタンス毎のログが.gzファイルに入っています。)
s3://xxxxxxxxxx-var-log-mssages/
┣━2016-12-29
┃ ┣━aws-logs-write-test
┃ ┗━5ce6a99c-bc8a-4af7-b818-061ed575183f
┃ ┣━i-03e629e997aa95f18
┃ ┃ ┗━000000.gz
┃ ┗━i-074549fdee10c46bc
┃ ┗━000000.gz
┗━2016-12-30
┣━aws-logs-write-test
┗━6c868fe1-d6ef-4d03-a6e0-4b2c89d1b44b
┣━i-03e629e997aa95f18
┃ ┗━000000.gz
┗━i-074549fdee10c46bc
┗━000000.gz
S3バケットで指定したパス以下にあるファイルがQuery対象のファイルになるので、
s3://xxxxxxxxxx-var-log-mssages/ 以下にあるファイルがQuery対象です。
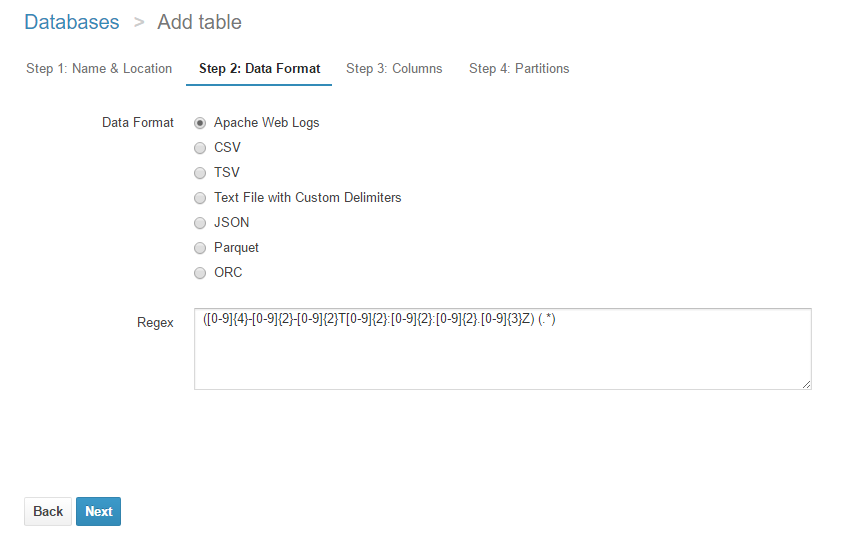
Data Format
ここでは、テキストをテーブルの列として扱うために、
どのようなフォーマットで列を区切るか指定します。
CSVやTSV、正規表現等が使えます。
今回Athenaで検索対象とするテキストは以下のように記載されているため、
2016-12-30T13:46:43.279Z Dec 30 22:46:42 ip-172-16-2-115 dhclient[2069]: bound to 172.16.2.115 -- renewal in 1663 seconds.
2016-12-30T13:46:43.279Z Dec 30 22:46:42 ip-172-16-2-115 ec2net: [get_meta] Trying to get http://169.254.169.254/latest/meta-data/network/interfaces/macs/06:65:2d:4e:6d:cf/local-ipv4s
2016-12-30T13:46:43.280Z Dec 30 22:46:42 ip-172-16-2-115 ec2net: [rewrite_aliases] Rewriting aliases of eth0
先頭の時刻部分(CloudWatch Logsの時刻)とDec 30以降の部分(ログファイルの本体)との2列になるよう、
以下の正規表現で列の区切りを設定しました。
([0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}Z) (.*)
Columns
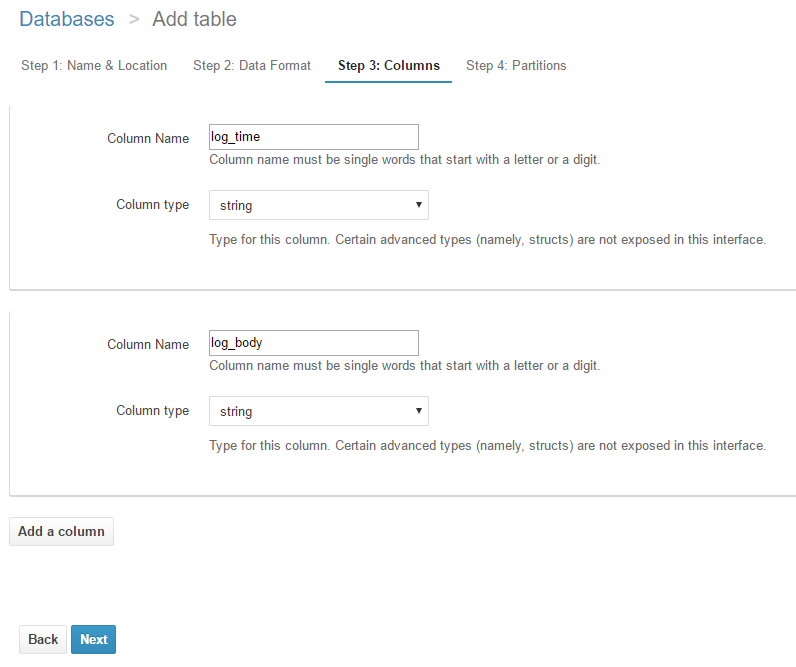
Data Formatで設定した列の区切りに対して、列名と型を設定します。
今回の列の区切りでは、1列目と2列目を文字列とするため、
以下のように設定しました。
Partitions
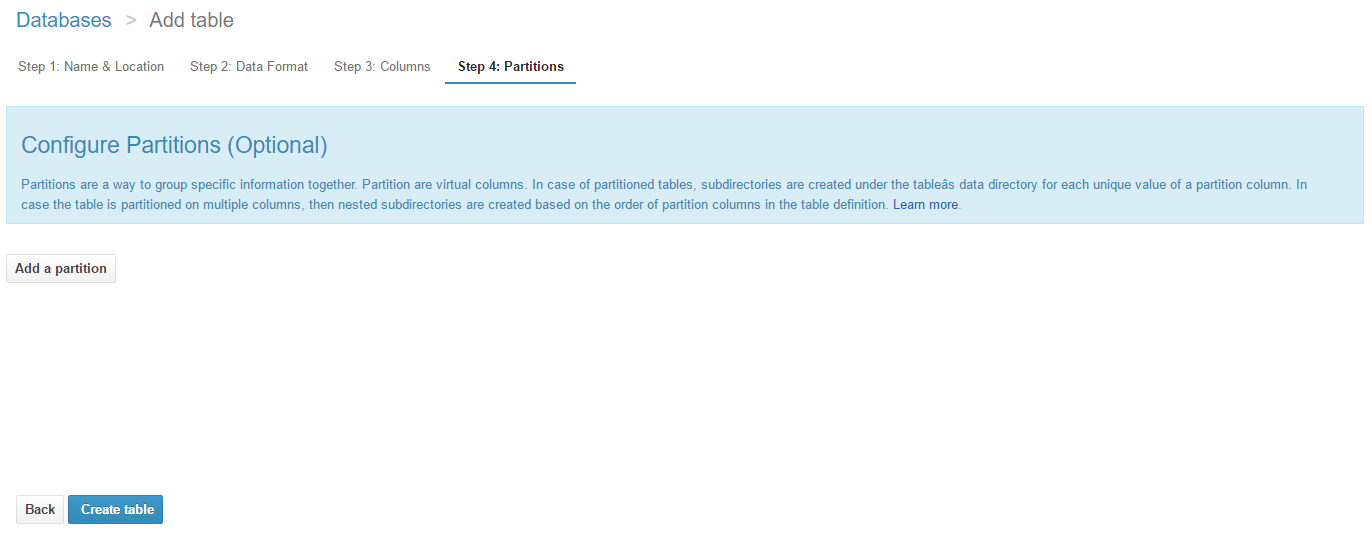
テーブルのパーティショニングを行うかどうかの設定ですが、
今回はお試しなのでパーティショニングは設定しません。
(Athenaはスキャン量に応じて課金されるので、
実際に運用する場合はスキャン量を減らすためにパーティショニングをしたほうがよいそうです。)
テーブル作成
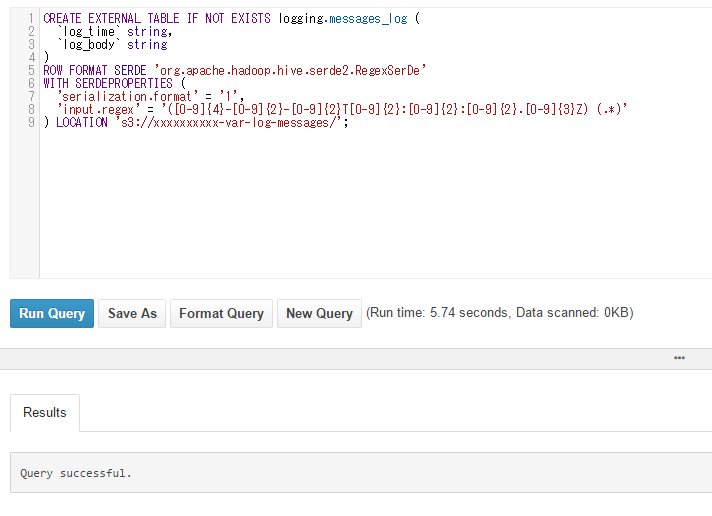
PartitionsでCreate tableを押下すると、
Query画面に戻され、先ほどまで設定した内容に基づいてSQLを作成・発行します。
検索
テーブルができましたので、
log_bodyにerrorの文字列が存在するものを検索します。
SELECT * FROM messages_log where log_body like '%error%' order by log_time desc;
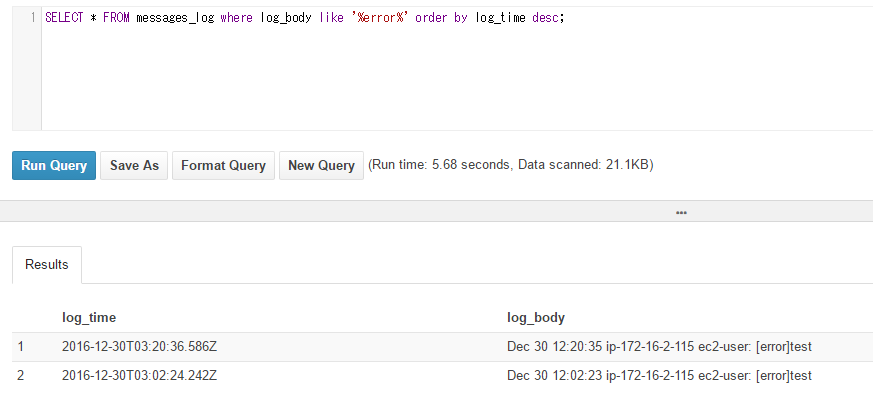
従来のSQLの書き方で、ログファイルにerrorの文字が存在するものを抜き出すことができました。
最後に
使った感想ですが、やはりログファイルをSQLで検索できるのは、
エラー頻度やエラー解析を行うには便利なように感じました。
ただ、クエリでスキャンしたデータ量に対して課金されるので、
エラー解析のためにガンガンSQLを実行するのは難しいかと思います。