![]()
はじめに
最近、ある程度の時間を割いてFalcorを触っています。
まだ日本語での情報は豊富とは言えない状況ですし、自分の理解を整理する意味も含め、何回かに分けてFalcorについて書いていきます。
1日目の今日は「Falcorとはどのような目的のために生まれ、どのような仕組みに依存しているのか」を説明します。
概念的な話ばかりでコードは殆ど出てきません。実装寄りの話は次回以降に書きますが、行ったり来たりしながら読むのも有りじゃないかなと思います。
ちなみに次回以降の目次はこちら:
- Falcor入門 2日目 FalcorのJSON Graphに触れてみる
- Falcor入門 3日目 Falcor Routerでサーバサイドを実装してみる
- Falcor入門 4日目 FalcorとReactを組み合わせる
Falcorとは何者か
昨今、Webアプリケーションの大半は、ReactやAngularなどのMVCフレームワークで画面を実装し、バックエンドにWeb APIを構えてJSONで通信する構成となっているのではないでしょうか。
Falcor はNetflixが開発した、クライアント - サーバ間のデータ通信を効率的に行うためのJavaScriptライブラリです。
FalcorはMVCフレームワークの代わりになるものでも、バックエンドの代わりになるものでもありません。クライアントとサーバの間に介在するMiddlewareです。
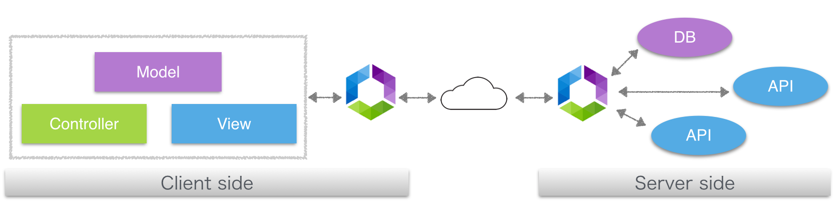
したがって、ブラウザで動作する falcor/browser や サーバで動作するfalcor/router といったモジュールが登場しますが、一旦それはさておいて、Falcorを使うとどのようなメリットを得られるかを見ていきます。
Falcorが解決してくれるものごと
What is Falcor?を見ると、"One Model Everywhere", "The Data is the API", "Bind to the Cloud"という章立てで説明がなされているのですが、初めてこれを読んだ時は何となく分かったような気になるものの、結局何が嬉しくて何のために作られたライブラリなのかを理解できませんでした。
ですので、このエントリでは下記の2軸で語ってみようと思います。
- データの透過性と一貫性
- データアクセスの効率性
データの透過性と一貫性
Falcorを利用する大きなメリットの1つは「データがサーバにあるのか、クライアントにあるのか意識することなく扱えるようになること」です。
Falcorが用意しているAPIはサーバサイド、クライアントサイド双方で扱えるようになっているため、Universal JavaScriptやSSR(Server Side Rendering)の文脈とも相性が良いです。
クライアントサイドがらみると、自分が必要とするデータが未取得であればサーバに問い合わせ、取得済みであればそのデータを再利用するように実装されています。
...と書いてしまうと、只のCacheライブラリの説明になってしまいます。FalcorはCacheの機能を有していますが、それだけではありません。
サーバのデータを透過的且つ一貫的に扱うことができます。
具体的な例で見ていきましょう。
例えば、僕がQiitaのAPIを利用してSPAでアプリケーションを作っているとしましょう。
このアプリケーションの要件として、自分の投稿一覧が表示できるものとします。
Qiitaで自分の投稿一覧を取得するためには次のAPIを実行します:
GET /api/v1/items
僕( @Quramy )が自分のアカウントで認証して実行した場合、次のようなレスポンスが返ってくるでしょう。
[
{
id: 'f7c751475032aab5ce98',
stocked: false,
title: 'gh-pagesコマンドで瞬殺deploy',
...
},
{
id: 'a5d8967cdbd1b8575130',
stocked: false,
title: 'TypeScript + React JSX + CSS Modules で実現するタイプセーフなWeb開発'
...
}
...
]
一方で、このアプリケーションでは"TypeScript"タグのの投稿一覧も表示したいとします。
GET /api/v1/tags/TypeScript/items
[
{
id: 'a5d8967cdbd1b8575130',
stocked: false,
title: 'TypeScript + React JSX + CSS Modules で実現するタイプセーフなWeb開発'
...
},
{
id: '5542daed0c408cb9f605',
stocked: true,
}
...
]
id: a5d8967cdbd1b8575130(TypeScript + React JSX + CSS Modules で実現するタイプセーフなWeb開発) の投稿が双方のリストに出現している状態です。
もし自分の投稿一覧と、TypeScriptタグの投稿一覧の各投稿要素にストックボタンを配置した場合、何が起こるでしょうか。
TypeScriptタグ投稿一覧の1番目の要素(「TypeScript + React ...」の投稿)をストックしたとしましょう。
この投稿は自分の投稿一覧にも含まれていますので、双方のリストでデータ不整合を起こさないようにするためには、もういちどGET /api/v1/items を呼び出して、リストを再構築しないといけません。殆ど全ての要素はcacheとして再利用できる可能性が高いですが、破棄せざるを得ません。
リストの再取得を嫌う場合は、自分の投稿リストに同じidを持つ投稿があるかどうか、クライアントでfindし、見つかったら該当要素のstocked をtrueにする必要が出てきます。
前者は安全な方法かも知れませんがネットワークに無駄な負荷がかかりますし、後者はサーバと同様の変更をクライアントで担保しなくてはならないためバグの元になりがちです。
不整合が起きてしまう理由をもう一度考えてみましょう。
サーバー上のDBでは単一のエンティティであった投稿が、クライアント上では別のオブジェクトとして扱われてしまったため、と言えますよね。

もし、ネットワークを跨いで「参照」の概念を受け渡せたのであれば、このような問題は発生しません。
しかし、JSONという表現は本質的に木構造であるため、ある投稿が複数のリストに含まれている状態をそのままでは表せません。
そこでFalcorが導入したのがJSON Graphです。Graph構造をJSONで表現するという概念です。
先ほどのQiita APIの例をJSON Graphで表現したら、次のようになるでしょう。
{
itemsById: {
'f7c751475032aab5ce98': {
id: 'f7c751475032aab5ce98',
stocked: false,
title: 'gh-pagesコマンドで瞬殺deploy',
...
},
'a5d8967cdbd1b8575130': {
id: 'a5d8967cdbd1b8575130',
stocked: false,
title: 'TypeScript + React JSX + CSS Modules で実現するタイプセーフなWeb開発'
...
},
'5542daed0c408cb9f605': {
id: '5542daed0c408cb9f605',
stocked: true,
},
...
},
myItems: [
{$type: 'ref', value: 'itemsById.f7c751475032aab5ce98'},
{$type: 'ref', value: 'itemsById.a5d8967cdbd1b8575130'},
...
],
typescriptItems: [
{$type: 'ref', value: 'itemsById.a5d8967cdbd1b8575130'},
{$type: 'ref', value: 'itemsById.5542daed0c408cb9f605'},
...
]
}
投稿の実体は全てitemsById という連想配列の中に情報を持たせ、自分の投稿一覧(myItems)とTypeScriptタグの投稿一覧(typescriptItems) はitemsByIdの要素を参照していることを表しています。
JSON Graphをクライアント - サーバでやりとりするようにすれば、一貫性が保証されるようになります。
FalcorはクライアントがJSON Graphを直接意識しなくて済むように、typescriptItems[1].title とすれば、referenceを解決した上で値を返却してくれるようにメソッドが準備されています。
この「サーバから取得したJSON Graphの参照構造を解決してクライアントには通常のJSONのように見せる」ことをFalcorではVirtual JSONと呼んだりしています。
データアクセスの効率性
JSON GraphをAPIの表現に用いるとして、1回1回のHTTP Requestで全部のJSON Graphをやりとりしていたら膨大な通信量になってしまいます。
そこで、Falcorを用いてデータにアクセスする際には、必要なJSONのパスを必要な分だけ要求するようになっています。
実際のコーディングについては、次回以降で見ていく予定ですが、チラ見せ的に書いてみましょう。
model.get('myItems[0].id', 'myItems[0].title')
このコードは、Falcorへの「myItems(自分の投稿一覧)の先頭要素のうち、idとtitleの値を頂戴」という要求を表します。
するとFalcorがサーバへ上記の情報を次のようなHTTP リクエストとして送信します。
GET /model.json?paths=["myItems[0].id","myItems[0].title"]
サーバ側では、上記のGETリクエストに対して下記のようなレスポンスを生成します。
{
itemsById: {
'f7c751475032aab5ce98': {
id: 'f7c751475032aab5ce98',
title: 'gh-pagesコマンドで瞬殺deploy'
}
},
myItems: [
{$type: 'ref', value: 'itemsById.f7c751475032aab5ce98'}
]
}
このレスポンスが先述のJSON Graphの一部分であることがポイントです。
Falcorはクライアント側でJSON Graphをcacheしており、サーバから部分的なJSON Graphを受けとるごとに、cacheにマージしていくようになっています。
その上で、JSON Graphの参照関係を解決しれくれます。
最終的に、先ほどのmodel.get('myItems[0].id', 'myItems[0].title')からは、{myItems: {0: { id: 'f7c751475032aab5ce98', title: 'gh-pagesコマンドで瞬殺deploy'}}}という結果が得られます。
部分的なJSON Graph(JSON Graph全体と区別するために、JSON Graph Envelopeと呼ばれる)を通信に用いることで、クライアントは自分が必要とするデータのみをサーバから効率的に取得できるのです。
上記はサーバからの値取得の流れに沿って説明しましたが、値更新系の処理においても「JSON Graphのどの部分を書き換えるか」をVirtual JSONのパスで指定、サーバ側では「値の更新処理によって置き換えるJSON Graphの部分集合」をJSON Graph envelopeとして返却する、というフローは一緒です。
したがって、JSON Graph, JSON Graph Envelope, Virtual JSON Pathの概念を把握しておくことはとても重要です。
また、Cacheの有無によってサーバへ非同期通信が発生する都合上、Falcorのメソッドは全て非同期(Observable or Promise)で動作することも押えておくとよいです。
サーバ側の話
さて、先ほどの説明では、さらっと「サーバ側では、上記のGETリクエストに対して下記のようなレスポンスを生成します」と書きました。
が、おそらくこの部分がFalcorを導入する上で一番の障壁となりやすい部分だと思います。
なぜなら、リクエストの送信やCacheの管理はFalcorがやってくれますが、サーバ側で値を返す部分は開発者が実装する必要があるからです。
「クライアントから送信されたFalcorのリクエストを読み解いて、バックエンドのサービス(DBやREST API)を呼び出し、JSON Graph Envelopeとしてレスポンスを返却する」役割を持った、Falcor Endpoint サーバです。
Netflixもそうですが、バックエンドのサービスはMicro Servicesの構成で複数に分散しているケースも考えられますし、Falcorからのリクエストが画面の表示項目と強く結びつきやすいことを考えると、このサーバの実装はフロントエンドエンジニアのタスクとして捉えることもできます。
一方で、サーバ実装に必要なスキルがクライアントサイド向けのスキルセットと異なることを考えると、バックエンドのエンジニアを引っ張ってくるのも変な話ではありません。
このエントリの冒頭で「FalcorはMVCフレームワークの代わりになるものでも、バックエンドの代わりになるものでもありません。クライアントとサーバの間に介在するMiddlewareです」と書きましたが、新しいMiddlewareであるということは、その面倒を見るエンジニアが新しく必要になるという意味でもあります。
Falcorに限った話ではないですが、新しいMiddlewareを導入するにあたっては、誰がその層に責任を持ってを実装するか、また実装スキルを持ったエンジニアがチームに存在しているか(アサイン可能かも含めて)といった組織論チックな話にも目を向ける必要があります。
MicroServiceの文脈でFalcorを語るのであれば、Falcor EndpointサーバはBackend for Frontend(BFF) architectureの実装例でしょう。 BFFについての詳細についてはPattern: Backends For Frontends を読むことをお勧めします。英語ですが、BFFサーバの実装粒度とチーム構成の話なども記載があり、読みごたえがあります。
まとめ
1日目の今日は、以下について解説しました。
- Falcorはクライアント - サーバ間で、データを透過的、一貫的、効率的に扱うことを目的に作られたMiddlewareである
- この目的を達成する要がJSON Graph。 JSONの木構造で「参照」を表せるようにした表現方法。
- Falcorを導入するためには、Falcorのリクエストを処理するためのendpointとなるサーバを実装する必要がある
2.については、僕自身、プロダクションでのFalcor適用を行った訳ではないため、まだ結論が見えてはいないのですが、自分で実装するかバックエンドのチームに任せるか悩みどころですね。久々にサーバ系の実装に手出すのも悪くないかも。
次回はFalcorのJSON Graphについて、値の取得/更新の実装方法を紹介したいと思います。