概要
テキストファイルを行単位でループしたいです。それは IO.foreach や IO#each_line を使えば実現できるでしょう。しかし、ファイルの末尾から逆順にループしたい場合はどうでしょう。File クラスや IO クラスの API リファレンスを参照しても、reverse_each のような名前のメソッドは存在しないようです。困った ![]()
暫定的な解決策
Enumerable#reverse_each を使って Enumerable オブジェクトを逆順にループすれば実現できそうです。
File
.foreach('huge.txt')
.reverse_each { |line| puts(line) }
しかし結局のところ、reverse_each を呼ぶ場合は単に foreach だけを呼ぶ場合と異なり、すべての行が評価されてメモリに展開されてしまいます。そのため、テキストファイルの容量が大きい場合に膨大なメモリを消費してしまいます。
解決策
ファイルの末尾から特定のバッファサイズずつ行を読み込む仕組みを実装しました。
コード
def reverse_lines(file_path, buffer_size = 2**12)
Enumerator.new do |y|
File.open(file_path, 'r') do |f|
f.seek(0, IO::SEEK_END)
file_size = f.pos
remaining_size = file_size
buffer_size = [file_size, buffer_size].min
offset = 0
segment = nil
loop do
remaining_size = file_size - offset
if remaining_size <= 0
y.yield(segment) if segment
break
end
offset += buffer_size
position = [file_size - offset, 0].max
f.seek(position)
read_length = [remaining_size, buffer_size].min
buffer = f.read(read_length)
lines = buffer.split("\n")
if segment && buffer[-1] != "\n"
lines.last << segment
segment = nil
end
if segment
lines << segment
segment = nil
end
segment = lines.shift
lines.reverse.each { |line| y.yield(line) }
end
end
end
end
解説
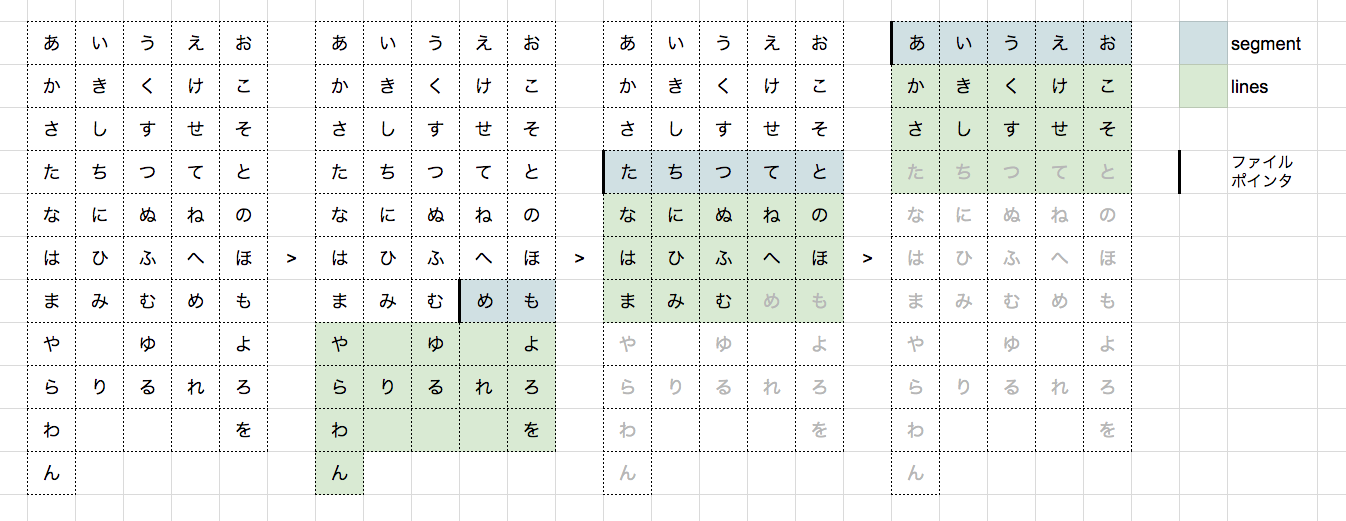
バッファサイズを 18 文字とします (実際のコードでの単位は文字ではなく byte です) 。まず、ファイルの末尾からバッファサイズの 18 文字分だけ前にファイルポインタを移動し、バッファサイズ分の文字列を読み取ります。このとき、読み取った文字列の一番上の部分は、上図の「めも」の部分のように、行として不完全である可能性があります。この部分は segment という変数に格納しておきます。そして、それ以降の行を逆順にループします。それから、さらにバッファサイズ分だけファイルポインタを前に移動して読み取り、読み取った文字列の末尾に格納しておいた segment を連結することで完全な行にします。以上の手続きをファイルをすべて読み取り終えるまで繰り返します。
実行例
あいうえお
かきくけこ
さしすせそ
たちつてと
なにぬねの
はひふへほ
まみむめも
や ゆ よ
らりるれろ
わ を
ん
reverse_lines('kana.txt')
.each { |line| puts(line) }
ん
わ を
らりるれろ
や ゆ よ
まみむめも
はひふへほ
なにぬねの
たちつてと
さしすせそ
かきくけこ
あいうえお
メモリ消費量の比較
huge.txt という 521,135 行、約 7 MB のテキストファイルを .first(100).each でループした結果です。プロファイラには memory_profiler を使用します。
require 'memory_profiler'
report = MemoryProfiler.report do
File
.foreach('huge.txt')
.first(100)
.each { |line| puts(line) }
end
report.pretty_print
# Total allocated: 13696 bytes (107 objects)
report = MemoryProfiler.report do
File
.foreach('huge.txt')
.reverse_each
.first(100)
.each { |line| puts(line) }
end
report.pretty_print
# Total allocated: 26026936 bytes (521144 objects)
report = MemoryProfiler.report do
reverse_lines('huge.txt', 2**12)
.each
.first(100)
.each { |line| puts(line) }
end
report.pretty_print
# Total allocated: 24441 bytes (415 objects)
| 方法 | メモリ消費量 |
|---|---|
| File.foreach | 13,696 bytes |
| File.foreach.reverse_each | 26,026,936 bytes |
| reverse_lines (今回の方法) | 24,441 bytes |
用途
例えば「容量の大きなログファイルの最新 10,000 行を対象に、任意の文字列を抜き出す」などの用途に使えそうです。
# 最新の 10,000 行から IP アドレスだけ抜き出したい。
reverse_lines('log/development.log', 2**12)
.lazy
.map { |line| line[/\d{1,3}\.\d{1,3}\.\d{1,3}.\d{1,3}/] }
.first(10_000)
.compact
.uniq
おまけ
クラスバージョン
class ReverseLines
extend Forwardable
attr_accessor :file_path, :buffer_size
def_delegators(:each, :lazy)
def initialize(file_path, buffer_size = 2**12)
self.file_path = file_path
self.buffer_size = buffer_size
end
def each
return enum_for(:each) unless block_given?
File.open(file_path, 'r') do |f|
f.seek(0, IO::SEEK_END)
state = State.new(file_size: f.pos, buffer_size: buffer_size)
loop do
state.update_remaining_size
if state.remaining_size <= 0
yield(state.segment) if state.segment
break
end
state.increment_offset
f.seek(state.position)
buffer = f.read(state.read_length)
lines = buffer.split("\n")
if can_append_segment_to_buffer?(state, buffer)
lines.last << state.segment
state.clear_segment
end
if state.segment
lines << state.segment
state.clear_segment
end
state.segment = lines.shift
lines.reverse.each { |line| yield(line) }
end
end
end
private
def can_append_segment_to_buffer?(state, buffer)
state.segment && buffer[-1] != "\n"
end
class State
attr_accessor :file_size, :remaining_size, :buffer_size, :offset, :segment
def initialize(file_size:, buffer_size:)
self.file_size = file_size
self.remaining_size = file_size
self.buffer_size = [file_size, buffer_size].min
self.offset = 0
self.segment = nil
end
def update_remaining_size
self.remaining_size = file_size - offset
end
def increment_offset
self.offset += buffer_size
end
def position
[file_size - offset, 0].max
end
def read_length
[remaining_size, buffer_size].min
end
def clear_segment
self.segment = nil
end
end
end
ReverseLines.new('log/development.log', 2**12)
.lazy
.map { |line| line[/\d{1,3}\.\d{1,3}\.\d{1,3}.\d{1,3}/] }
.first(10_000)
.compact
.uniq