はじめに
日々、StackOverflow や Qiita や Medium らで pythonについてググっている私がこれ使えるな、面白いなと思った tips や tricks, ハックを載せていくよ。
簡単な例文だけ載せてくスタイル。新しいの発見次第、じゃんじゃん頻繁に追加していくよ。
これも知っとけ!これ間違ってる!ってのがあったら、コメント下さい。
このモジュルやライブラリーの関数とか基本/応用的な使い方を知りたいけど、自分で探すの面倒、英語意味不ってのがありましたらそれもコメントにどうぞ。私が代わりに調査 • 解析を努力致します。
簡単な例文を心がけてはいますが、なにせ読むな!見て感じろ!なくらい説明不十分なので、初歩的な関数の使い方などのpython知識を所有しているとすんなり理解しやすいかと思います。多分。
注:リンク先は全て英語です。PEP8をいつかは読みましょう。良いスタイルガイドです。
目指せ、パイソニスタ!
読み直した時にどこをアップデートしたのかわからなくなると思うので、最近追加したセクションに★を置いておくよ
Python3.8 NEW FEATURES
- Python Version3.8から使える新しい機能 -> python3.8 official
- NOTICE: 2020年3月現在、pythonのhomebrewでのデフォルトバージョンは3.7 (link)
★ := syntax
a = [1,2,3,4,5]
if (n := len(a)) > 10:
print(f"List is too long ({n} elements, expected <= 10)")
else:
print(f"variable n is {n}")
print(n)
# ---> variable n is 5
# ---> 5
★ Positional-only parameters
- 関数のパラメータで /, * を使うことによって関数を呼ぶときの引数らをポジションのみ、キーワードのみ、又は両方可能で渡すかの設定ができる
def f(position1, position2, /, both1, both2, *, keyword1, keyword2):
print(f"ポジションのみ: {position1, position2}")
print(f"両方: {both1, both2}")
print(f"キーワードのみ: {keyword1, keyword2}")
# 正しい呼び方
f(10, 20, 30, both2=40, keyword1=50, keyword2=60)
# --->ポジションのみ: (10, 20)
# --->両方: (30, 40)
# --->キーワードのみ: (50, 60)
# 間違った呼び方
f(10, position2=20, 30, both2=40, keyword1=50, keyword2=60)
# position2 はキーワードで渡せない
f(10, 20, 30, 40, 50, keyword2=60)
# keyword1 はキーワードでしか渡せない
1. Basic :基本
print()
# print()は、末尾に改行を追加して出力するのがデフォルト
# end=
print("hello" end='\t')
print("world")
# ---> hello world
# 改行せずに1タブ分空くよ
# end=
print("python" end="")
print("awesome")
# ---> pythonawesome
# スペースがないよ
# sep=
print('Cats', 'Dogs', 'Pigs', sep=' & ')
# ---> Cats & Dogs & Pigs
x = 1
y = 2
print(x, y)
# ---> 1, 2
print((x, y))
# ---> (1, 2)
Slicing
# 初歩中の初歩
a = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
a[2:5] = [1, 2] # aのインデックス 2, 3, 4 にリスト[1,2]と入れ替える
# c,d,eが消えるよ
print(a)
# ---> ['a', 'b', 1, 2, 'f', 'g']
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
a[3:5] = ['a', 'b', 'c'] # 元のaの4,5のみ消えるよ。
print(a)
# ---> [1, 2, 3, 'a', 'b', 'c', 6, 7, 8, 9, 10]
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(a[::-1]) # リバース
# ---> [10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
print(a[::2]) # 偶数目
# ---> [0, 2, 4, 6, 8, 10]
print(a[1::2]) # 奇数目
# ---> [1, 3, 5, 7, 9]
b = "awesome"
reverse = b[::-1]
print(reverse)
# ---> emosewa
List copy: Shallow and Deep リストの浅いコピーと深いコピー
# Shallow Copy####### 浅いコピー
# import copy の copy.copy(a)と一緒
a = [1, 2, 3]
b = a[:]
print(a is b)
# ---> False
print(a == b)
# ---> True
# id(): そのオブジェクトのメモリーアドレスが返されるよ
print(id(a))
# ---> 4363798344
print(id(b))
# ---> 4363796936
# aとbのメモリーアドレスは違うのにそれぞれのリスト内のアイテムのメモリーアドレスは一緒なのだ
print(id(a[0]) == id(b[0]))
# ---> True
print(id(a[1]) == id(b[1]))
# ---> True
#### Deep Copy ######### 深いコピー
import copy
deep = [1, 2, 3]
super_deep = copy.deepcopy(deep)
deep[0] = 100
print(deep)
# ---> [100, 2, 3]
print(super_deep)
# ---> [1, 2, 3]
super_deep[1] = 999
print(deep)
# ---> [100, 2, 3]
print(super_deep)
# ---> [1, 999, 3]
print(id(deep))
# ---> 4363689672
print(id(super_deep))
# ---> 4363543368
###############
# これは変数bをaのメモリアドレスに向けただけだよ
# 同じメモリアドレスを指すよ
a = [1, 2, 3]
b = a
print(a is b)
# ---> True
print(a == b)
# ---> True
print(id(a))
# ---> 4363689672
print(id(b))
# ---> 4363689672
Shallow copy? Deep Copy? Huh??
極端な例で例えるなら…
a = b -> リストに別のニックネームをつけるようなもん。(コピーですらない)
a = b[:] , 又は a = copy.copy(b) -> リストaさんはリストbさん夫婦は二人とも別人だけどそれぞれのリスト内の子供a[0]美はb[0]美と同一人物 (浅いコピー)
a = copy.deepcopy(b) -> 全くの別人。ドッペルゲンガー。99.9%そっくりさん。はたまた双子。(深いコピー)
How to check if list is empty リストが空かどうかを調べる
a = []
if a:
print("ok")
else:
print("bye")
# ---> bye
if not a:
print("empty")
# ---> empty
# BAD WAY おすすめしません
if len(a) == 0: print("a is empty")
# ---> a is empty
# BAD WAY
if a == []:
print('a is an empty list')
# ---> a is an empty list
Converting to binary 2進数へ変換
print("{0:b}".format(1))
# ---> 1
print('{0:08b}'.format(1))
# ---> 00000001
print(format(1, '08b'))
# ---> 00000001
print(f'{1:08b}')
# ---> 00000001
print(bin(1))
# ---> 0b1
print(bin(1)[2:].zfill(8))
# ---> 00000001
############################
print("{0:b}".format(2))
# ---> 10
print("{0:b}".format(5))
# ---> 101
print("{0:b}".format(80))
# ---> 1010000
Ternary Operator 三項演算子
y = 9
# y が 9 だったら x = 10, それ以外だったら x = 20
x = 10 if (y == 9) else 20
# 上の例と同義
if y == 9:
x = 10
else:
x = 20
#変数ansが if条件と一致していれば 二つのクラスのうち, その中の一つのclass constructorを呼ぶ
class Dog:
def __init__(self, name):
print("dog's name is ", name)
class Cat:
def __init__(self, name):
print("cat's name is ", name)
ans = "yes"
my_pet = (Dog if ans == "yes" else Cat)("Bruce")
# ---> dog's name is Bruce
# ans が if とマッチしているので、my_pet = Dog("Bruce")
# 基本構造: x = (classA if y == True else classB)(param1, param2)
Decorator デコレータ
- decoratorの基礎を簡単な例で説明するよ
- 詳しくは:https://www.python.org/dev/peps/pep-0318/#syntax-forms
- もっと難しいのくれよって人には:https://www.codementor.io/sheena/advanced-use-python-decorators-class-function-du107nxsv
- decorator の前にfunctionを理解しよう
def hey(name="namibillow"):
return "hey " + name
print(hey())
# ---> hey namibillow
# 関数を変数に代入
# 注意: greeting = hey() だと hey functionを呼んでしまうyo
greeting = hey()
print(greeting)
# ---> hey namibillow
# 関数を呼ばずに関数ごとを渡すよ
greeting = hey
print(greeting)
# ---> <function hey at 0x101bb7e18>
print(greeting())
# ---> hey namibillow
# delete hey heyを削除
del hey
print(hey())
# ---> NameError
print(greet())
# ---> hey namibillow
頭がこんがらがったら自分はこう考えてます。
- 関数を呼ぶ、()をつける イコール 風呂敷の中身を広げたまんま変数aさんに渡す
- 関数を()なしで変数に代入 イコール 風呂敷を包んだまんま変数aさんに渡す。a さんは自分で風呂敷を開けなきゃいけない( ()をつける)
# pythonではfunctionの中に、いくつものfunctionを定義できるよ
def greetings(name="kame"):
print(name, "is inside the greetings() function!")
def morning():
return "now ", name, " is in the morning() function"
def night():
return "now ", name, " is in the night() function"
print(morning())
print(night())
print(name, "is back in the greetings() function!")
# greetings関数を呼ぶと morning(), night() も呼ばれるよ
greetings()
# ---> kame is inside the greetings() function!
# now kame is in the morning() function
# now kame is in the night() function
# kame is back in the greetings() function!
morning()
# ---> NameError: name 'morning' is not defined
# 中のfunctionはouter function外からじゃ呼べないよ
########################################################
def hi(name="nami"):
def greet():
return "now you are in the greet() function"
def welcome():
return "now you are in the welcome() function"
if name == "nami":
return greet # greet()だと処理した結果を返しちゃうよ
else:
return welcome # 関数を返すよ
# 変数a に関数hi()のreturnされたものを代入 (この場合 greet関数 が返される)
a = hi()
print(a)
# ---> <function hi.<locals>.greet at 0x104188488>
# つまり a は現在 関数hi() 内の 関数greetのメモリーアドレスを指している
# hi() は greet か welcome関数自体を返すよ
print(hi()())
# ---> now you are in the greet() function
print(a())
# ---> now you are in the greet() function
# 関数に他の関数を引数として渡せるよ
def afterEat():
return 'ごちそうさまでした'
def beforeEat(func):
print("いただきます")
print(func())
beforeEat(afterEat)
# ---> いただきます
# ごちそうさまでした
- それじゃあdecorator いってみよー
def a_decorator(a_func):
print("a_decorator内だよ")
def wrap():
print("a_func() がまだ呼ばれる前だよ")
a_func()
# decoratorで渡された 関数a_funcをa_decorator()内の関数wrap()内で呼ぶよ
print("a_func() はもう呼ばれ終わったよ!")
return wrap # 関数を返すよ
def calling():
print("名前はcalling だけど a_decorator関数内でのニックネームは a_func だよ")
calling = a_decorator(calling)
# now calling is wrapped by wrap(). callingと言う変数はwrap()を呼べるよ
calling()
# ---> a_decorator内だよ
# a_func() がまだ呼ばれる前だよ
# 名前はcalling だけど a_decorator関数内でのニックネームは a_func だよ
# a_func() はもう呼ばれ終わったよ
# @で呼んでもいいよ
@a_decorator
def calling():
print("名前はcalling だけど a_decorator関数内でのニックネームは a_func だよ")
calling()
# ---> a_decorator内だよ
# a_func() がまだ呼ばれる前だよ
# 名前はcalling だけど a_decorator関数内でのニックネームは a_func だよ
# a_func() はもう呼ばれ終わったよ
# @a_decoratorをdef calling()前につけるのは
# calling = a_decorator(calling)を省略したのと一緒だよ
itertools
import itertools
# list in list を、 1 list にしたい時
a = [[0, 1, 2], [3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
list(itertools.chain.from_iterable(a))
# ---> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
########################
from itertools import chain
for c in chain(range(3), range(12, 15)):
print(c, end=" ")
#---> 0 1 2 12 13 14
########################
from itertools import permutations
for p in permutations([1, 2, 3]):
print(p)
# --->
# (1, 2, 3)
# (1, 3, 2)
# (2, 1, 3)
# (2, 3, 1)
# (3, 1, 2)
# (3, 2, 1)
############################
from itertools import combinations
for c in combinations([1, 2, 3, 4], 2):
print(c)
# --->
# (1, 2)
# (1, 3)
# (1, 4)
# (2, 3)
# (2, 4)
# (3, 4)
more_itertools
import more_itertools
test = [[-1, -2], [1, 2, 3, [4, (5, [6, 7])]], (30, 40), [25, 35]]
print(list(more_itertools.collapse(test)))
# ---> [-1, -2, 1, 2, 3, 4, 5, 6, 7, 30, 40, 25, 35]
Return multiple variables 複数の戻り値をそれぞれの変数に返すよ
def x():
return 1, 2, 3, 4
a, b, c, d = x()
print(a, b, c, d)
# ---> 1 2 3 4
Enums 列挙型
class Shapes:
Circle, Square, Triangle, Quadrangle = range(4)
print(Shapes.Circle)
# ---> 0
print(Shapes.Square)
# ---> 1
print(Shapes.Triangle)
# ---> 2
print(Shapes.Quadrangle)
# ---> 3
###############################################
from enum import IntEnum
Shapes = IntEnum("Shapes", "Circle Square Triangle Quadrangle", start=0)
print(Shapes)
# ---> <enum 'Shapes'>
print(Shapes(0))
# ---> Shapes.Circle
print(Shapes(1))
# ---> Shapes.Square
print(Shapes(2))
# ---> Shapes.Triangle
print(repr(Shapes.Circle))
# ---> <Shapes.Circle: 0>
for shape in Shapes:
print(shape)
# ---> Shapes.Circle
# ---> Shapes.Square
# ---> Shapes.Triangle
# ---> Shapes.Quadrangle
# Example 2
# Name Aliases
class Color():
red = 1
green = 2
blue = 3
really_blue = 3
# use 'is' is optimal than using '=='
print(Color.blue is Color.really_blue)
# ---> True
print(Color.red is Color.blue)
# ---> False
zfill() 0埋め
# 注意:変数は文字列じゃなきゃzfill()は使えないよ
str = '2'
print(str.zfill(2))
# ---> 02
str = 'abc'
print(str.zfill(5))
# ---> 00abc
★String formatting★ 文字列のフォーマット
- リストのunpackでフォーマットもできるよ
# f''は、Python3.6以降のみ使用可能
a = 40
print(f'this is {a}')
# ---> this is 40
print('it is same as {}'.format(a))
# ---> it is same as 40
print('also same as %d' % (a))
# ---> also same as 40
format_list = ['鶴', '亀']
print("{}は千年、{}は万年".format(*format_list)) # unpack the list
# ---> 鶴は千年、亀は万年
print("my favorite actors are %(foo)s and %(bar)s." % {'foo': '竹野内豊', 'bar': '松坂桃李'})
# ---> my favorite actors are 竹野内豊 and 松坂桃李.
person = {'name':'Matsumoto','age':33}
sentence = "Hello this is {0[name]} and I am {0[age]} years old".format(person)
print(sentence)
# ---> Hello this is Matsumoto and I am 33 years old
l=['Lady','Gaga']
sentence = 'my favorite singer is {0[0]} {0[1]}!'.format(l)
print(sentence)
# ---> my favorite singer is Lady Gaga!
Dealing with file ファイルの読み書き
# sample.txt サンプルテキストファイル
Hello
My name is Namibillow
Nice 2 meet ya
Python is so easy
with open('sample.txt', 'r') as f:
print(f.name)
# ---> sample.txt
print(f.mode)
# ---> r
# r = read only ってことだよ。読むオンリー。
print("----first 14 caracters----") #最初の14文字のみ
f_contents = f.read(14)
print(f_contents) #次の14文字
# --->
# Hello
# My name
print("----next 14 caracters----")
f_contents = f.read(14)
print(f_contents)
# --->
# is Namibillow
- example 2
# another 'sample.txt'
THIS IS JUST AN EXAMPLE
Isn't this cool??
No? well, too bad!!
with open('sample.txt', 'r') as f:
size_to_read = 15
f_contents = f.read(size_to_read) # 15文字目まで読むよ
print(f.tell())
# ---> 15
print(f_contents)
# ---> THIS IS JUST AN
# 続きからではなくもう一回最初から15文字を読み込みたい時
f.seek(0)
f_contents = f.read(size_to_read)
print(f_contents)
# ---> THIS IS JUST AN
- Example 3:ファイル内容を新しいtxtにコピーしたい
# original.txt
Copying to new txt file yeaaa
with open('original.txt', 'r') as r_f:
with open('copy.txt', 'w') as w_f:
for line in r_f:
w_f.write(line)
- 新しい copy.txtが作られるよ。内容を確認するとコピーされているのがわかるよ
# copy.txt
Copying to new txt file yeaaa
shututil ファイルやディレクトリ操作
- os moduleと使うと便利
import shutil
shutil.copyfile('コピーしたいファイル名', 'コピー先のファイル名')
# copy data from src to dest. コピー元から指定ファイル名にデータをコピーするよ
# both names must be files. どちらともファイルじゃなきゃできないよ
shutil.move(files,destination)
# 移行先は既存のファイル又はディレクトリはNG
shutil.rmtree('everything/under/this/deleted')
# 指定ディレクトリとその中身を削除
filter
numbers = [0, 1, 2, 3, 4, 5]
# 偶数のみ返す
def is_even(numbers):
return numbers % 2 == 0
filteredVowels = filter(is_even, numbers)
print(list(filteredVowels))
# ---> [0,2,4]
update()
# パラメータにはdictionary, an iterable object of key/value pairs (generally tuples)を渡すことができるよ
# does not return any value. 何も返されないよ
d = {1: "one", 2: "three"}
d1 = {2: "two"}
# updates the value of key 2
# キーが2の値をアップデート
d.update(d1)
print(d)
# ---> {1: 'one', 2: 'two'}
d1 = {3: "three"}
# adds element with key 3
# ディクショナリーdにキーが3で値がthreeを追加
d.update(d1)
print(d)
# ---> {1: 'one', 2: 'two', 3: 'three'}
d = {'x': 2}
d.update(y = 3, z = 0)
print(d)
# ---> {'x': 2, 'y': 3, 'z': 0}
any(), all()
x = [True, True, False]
# any(): どれか一つでもtrueがあるなら
if any(x):
print("At least one True")
# ---> At least one True
# all(): 全てtrueなら
if all(x):
print("Not one False")
else:
print("There is False")
# ---> There is False
# どれか一つでもtrueであり、なおかつ全てtrue出ないなら
if any(x) and not all(x):
print("At least one True and one False")
# ---> At least one True and one False
print(any([]))
# ---> False
print(any([1]))
# ---> True
zip()
print("ZIP function:")
a = [1, 2, 3]
b = [4, 5, 6]
c = zip(a, b)
for d in c:
print(d)
# ---> (1, 4)
# (2, 5)
# (3, 6)
#########################
b = [[1, 2, 3, 4], [6, 5, 4, 3]]
b = zip(*b)
print(*b)
# ---> (1, 6), (2, 5), (3, 4), (4, 3)
variables, 変数
x, y = 10, 20
print(x, y)
# ---> 10,20
x = y = z = 2
print(x,y,z)
# ---> 2 2 2
x, y = y, x
print(x, y)
# ---> 20,10
a = ["This", "is", "awesome."]
print(" ".join(a))
# ---> This is awesome.
n = 10
result = 1 < n < 20
print(result)
# ---> True
x = 2
y = 8
print(0 < x < 4 < y < 16)
# ---> True
★★★★★★★★★★★★★
# Convert list to comma separated リストをカンマで分かれるようにする
fav_number = [1,100,7,3]
print(','.join(map(str,fav_number))) # strにタイプを変える
# ---> 1,100,7,3
Dictionary Comprehension ディクショナリーでの内包表記
- リストのみならず、ディクショナリーやセットでもできるよ
testDict = {i: i * i for i in range(5)}
print(testDict)
# ---> {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
Unpacking 中身の展開
a, b, c = (2 * i for i in range(3))
print(a, b, c)
# ---> 0 2 4
def unpack(x, y, z):
print(x, y, z)
testDict = {'x': 1, 'y': 2, 'z': 3}
print(unpack(*testDict))
# ---> x y z
print(unpack(**testDict))
# ---> 1 2 3
########################
(a, *rest, b) = range(5)
print(a)
# ---> 0
print(rest)
# ---> [1, 2, 3]
print(type(rest))
# ---> <class 'list'>
print(b)
# ---> 4
dir()
# モジュール内で定義されている関数、属性などの一覧を取得
# 引数なしの場合は自分自身の属性
print(dir())
# ---> ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__',
# '__loader__', '__name__', '__package__', '__spec__', 'a', 'str', 'x']
# 引数にモジュールを渡した時にはそのモジュール内で定義されている属性
import string
print dir(string)
# ---> ['Formatter', 'Template', '_ChainMap', '_TemplateMetaclass', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_re', '_string', 'ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords', 'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation', 'whitespace']
print(dir('hey')
# ---> ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
inspect
import inspect
print("このコードの行: ", inspect.currentframe().f_lineno)
# ---> このコードの行: 17
# 書かれたコードがスクリプト内の何行目に位置するのかを出力
map()
- マップ
print("map function:")
x = [1, 2, 3]
y = map(lambda x: x + 1, x) # x[0], x[1], x[2]とindex ごとにループしてそれぞれに1を足す
print(list(y))
# ---> [2,3,4]
def square(x):
return x*x
squares = map(square, [1, 2, 3])
print(list(squares))
# ---> [1, 4, 9]
print(list(squares))
# ---> []
# アレッ!最後のリストが空っぽじゃあないか!なんで?
# python3 から map() は iteratorを返すようになったので一回ポッキリしか使えないのだ
# リストで返したい場合:
solution1 = list(map(square, [1, 2, 3]))
# 又は
solution2 = [*map(square, [1, 2, 3])]
List comprehension: リスト内包表記
- 個人的にはmap, filter, reduce()よりかも内包表記の方が読みやすく理解しやすい
- Map と 内包表記 と 普通のfor loop文のどれが速いのか知りたい方は下のリンクをどうぞ
- https://stackoverflow.com/questions/22108488/are-list-comprehensions-and-functional-functions-faster-than-for-loops
- https://stackoverflow.com/questions/1247486/python-list-comprehension-vs-map
- 読む限り、ケースにもよるけど大抵は内包表記の方がまあ速い,と唄う人が多くみられるぞ
# 偶数のみのリストが欲しい場合
L = [i for i in range(10) if i % 2 == 0]
print(L)
# ---> [0, 2, 4, 6, 8]
################################
# nested lists を一つのリストに
matrix = [[1,2,3], [4,5,6]]
# 間違え
L = [x for x in row for row in matrix]
# 正解
L = [x for row in matrix for x in row]
print(L)
# ---> [1, 2, 3, 4, 5, 6]
# nested for loop??どっから読めばいいの??
# そんな時は実際にfor loopで書いてみよう
L = []
for row in matrix:
for x in row:
L.append(x)
print(L)
# ---> [1, 2, 3, 4, 5, 6]
# Outer loop から書けばいいのだ
# ちなみに,内包表記 じゃないけど
print(sum(matrix, []))
# ---> [1, 2, 3, 4, 5, 6]
###############################
a = [(x, x**2) for x in range(5)]
print(a)
# ---> [(0, 0), (1, 1), (2, 4), (3, 9), (4, 16)]
from math import pi
b = [str(round(pi, i)) for i in range(1, 6)]
print(b)
# ---> ['3.1', '3.14', '3.142', '3.1416', '3.14159']
# 偶数だけ *100にしたい時
c = [x if x % 2 else x * 100 for x in range(1, 10)]
print(c)
# ---> [1, 200, 3, 400, 5, 600, 7, 800, 9]
##############################################
y = [100, 200, 300, 301, 5]
# 2で割り切れて、なおかつ10の倍数である
x = [x for x in y if not x % 2 and not x % 10]
print(x)
# ---> [100, 200, 300]
x2 = [x for x in y if x % 2 == 0 if x % 10 == 0]
print(x2)
# ---> [100, 200, 300]
# 2か5で割り切れる
z = [x for x in y if not x % 2 or not x % 5]
print(x)
# ---> [100, 200, 300, 5]
##############################################
# nested list(リストのなかにリスト)を作りたい
matrix = [[0 for col in range(4)] for row in range(3)]
print(matrix)
# ---> [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, 0]]
lambda ラムダ
add = lambda x, y: x + y
print(add(5,3))
# ---> 8
print((lambda x, y: x + y)(5, 3))
# ---> 8
map, filter
- python3 では reduce は from functools import reduceからじゃなきゃ使えなくなったよ
- 内包表記 とどっちがいいのか:https://stackoverflow.com/questions/3013449/list-comprehension-vs-lambda-filter
- 私的に内包表記の方が読みやすく感じるけれど、自分がわかりやすいと感じた方を使えばOK
def fahrenheit(T):
return ((float(9)/5)*T + 32)
def celsius(T):
return (float(5)/9)*(T - 32)
temperatures = (10, 20, 25, 40)
CtoF = list(map(fahrenheit, temperatures))
FtoC = list(map(celsius, CtoF))
print(CtoF)
# ---> [50.0, 68.0, 77.0, 104.0]
print(FtoC)
# ---> [10.0, 20.0, 25.0, 40.0]
# Lambdaの場合
F = list(map(lambda x: (float(9) / 5) * x + 32, temperatures))
C = list(map(lambda x: (float(5) / 9) * (x - 32), F))
print(F)
# ---> [50.0, 68.0, 77.0, 104.0]
print(C)
# ---> [10.0, 20.0, 25.0, 40.0]
# 2つ以上のlists
a = [1, 2, 3, 4]
b = [9, 8, 7, 6]
c = [-10, -9, -8, -7]
a_m = list(map(lambda x, y: x + y, a, b))
print(a_m)
# ---> [10, 10, 10, 10]
b_m = list(map(lambda x, y, z: x + y + z, a, b, c))
print(b_m)
# ---> [0, 1, 2, 3]
c_m = list(map(lambda x, y, z: 5 * x + 2 * y - z, a, b, c))
print(c_m)
# ---> [33, 35, 37, 39]
# ただしそれぞれのリストの長さには気をつけること
# 例えば:
short_list = [1, 2, 3]
long_list = [5, 6, 7, 8, 9]
print(list(map(lambda x, y: x * y, short_list, long_list)))
# ---> [5, 12, 21]
x = list(filter(str.isalpha, ['x', 'y', '2', '3', 'a', '5.5', '10*2']))
print(x)
# ---> ['x', 'y', 'a']
def isOdd(x): return x % 2 == 1
y = list(filter(isOdd, [1, 2, 3, 4]))
print(y)
# ---> [1, 3]
z = list(filter(lambda s: len(s) > 0, ['abc', '', 'd', '1234', ' ']))
print(z)
# ---> ['abc', 'd', '1234', ' ']
z = list(map(str.lower, ['A', 'b', 'C','Z']))
print(z)
# ---> ['a', 'b', 'c', 'z']
import operator
mapping = list(map(operator.add, [1, 2, 3], [9, 18, 27]))
print(mapping)
# ---> [10, 20, 30]
enumerate
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
print(enumerate(seasons)) # メモリのアドレスを返すよ
# ---> <enumerate object at 0x10418da68>
print(list(enumerate(seasons))) # display list of tuples of each item. 個々のタプルを表示
# ---> [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
print(list(enumerate(seasons, 10)))
# ---> [(10, 'Spring'), (11, 'Summer'), (12, 'Fall'), (13, 'Winter')]
###############################################3
mylist = ["Wow","This","Awesome"]
for index, item in enumerate(mylist):
print(index, item)
# ---> 0 Wow
# 1 This
# 2 Awesome
datetime
import datetime
# 現在の時刻
print("RIGHT NOW IS:", datetime.datetime.now())
# ---> RIGHT NOW IS: 2018-10-23 01:24:33.761917
# 指定時刻
print(datetime.date(2019, 8, 12))
# ---> 2019-08-12
today = datetime.date.today() #今日の日付 現時点2018-10-23
tdelta = datetime.timedelta(days=7)
print("A week from today is: ", today + tdelta)
#---> A week from today is: 2018-10-30
# 今日から7日後の日付
print("A week before from today is: ", today - tdelta)
# ---> A week before from today is: 2018-10-16
# 一週間前の日付
Tuple as a key for dictionary タプルをディクショナリーのキーにする
d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys
t = (5, 6)
print(type(t))
# ---> "<class 'tuple'>"
print(d[t])
# ---> 5
print(d[(1, 2)])
# ---> 1
Merging two dictionaries 2つのディクショナリーを合体
# 2つ以上のdictionariesを1つにまとめる
x = {'a': 1, 'b': 2}
y = {'b': 3, 'c': 4}
z = {**x, **y}
# ---> {'a': 1, 'b': 3, 'c': 4}
pprint オブジェクトの整形出力
- 別名キレイキレイ(と勝手に呼ばせてもらっている)
from pprint import pprint
ugly = [(i, {'0': 'This',
'1': 'Makes',
'2': 'So',
'3': 'Much',
'4': 'Easier',
'5': 'To',
'6': 'Read!'
})
for i in range(3)
]
pprint(ugly)
# --->
[(0,
{'0': 'This',
'1': 'Makes',
'2': 'So',
'3': 'Much',
'4': 'Easier',
'5': 'To',
'6': 'Read!'}),
(1,
{'0': 'This',
'1': 'Makes',
'2': 'So',
'3': 'Much',
'4': 'Easier',
'5': 'To',
'6': 'Read!'}),
(2,
{'0': 'This',
'1': 'Makes',
'2': 'So',
'3': 'Much',
'4': 'Easier',
'5': 'To',
'6': 'Read!'})]
print(ugly)
# --->
[(0, {'0': 'This', '1': 'Makes', '2': 'So', '3': 'Much', '4': 'Easier', '5': 'To', '6': 'Read!'}), (1, {'0': 'This', '1': 'Makes', '2': 'So', '3': 'Much', '4': 'Easier', '5': 'To', '6': 'Read!'}), (2, {'0': 'This', '1': 'Makes', '2': 'So', '3': 'Much', '4': 'Easier', '5': 'To', '6': 'Read!'})]
sys
# どのpython バージョンを使っているのか知りたい時
import sys
print("Current Python version: ", sys.version)
# ---> Current Python version: 3.6.5
# Recursion(再帰関数) のリミットを変えたい(デフォルトは1000)
x=1001
print(sys.getrecursionlimit())
# ---> 1000
sys.setrecursionlimit(x)
print(sys.getrecursionlimit())
# ---> 1001
collections
from collections import Counter
# 要素を辞書のキーとして保存し、そのカウントを辞書の値として保存
a = Counter('blue')
b = Counter('yellow')
print(a)
# ---> Counter({'b': 1, 'l': 1, 'u': 1, 'e': 1})
print(b)
# ---> Counter({'l': 2, 'y': 1, 'e': 1, 'o': 1, 'w': 1})
# 最も多い n 要素を、カウントが多い順に並べたリストを返すよ
print((a + b).most_common(3))
# ---> [('l', 3), ('e', 2), ('b', 1)]
collections: namedtuple()
import collections
Person = collections.namedtuple('Person', 'name age gender')
print('Type of Person:', type(Person))
# ---> Type of Person: <class 'type'>
nami = Person(name='Nami', age=99, gender='female')
print('\nRepresentation:', nami)
# ---> Representation: Person(name='Nami', age=99, gender='female')
maho = Person(name='Maho', age=19, gender='female')
print('\nField by name:', maho.name)
# ---> Field by name: Maho
print('\nFields by index:')
for p in [nami, maho]:
print('%s is a %d year old %s' % p)
# ---> Fields by index:
# ---> Nami is a 99 year old female
# ---> Maho is a 19 year old female
########################################################
Dog = collections.namedtuple('Dog', ['name', 'age'])
puppy = Dog(name='shibata', age=5)
print(puppy)
# ---> Dog(name='shibata', age=5)
print(puppy.name)
# ---> shibata
print(puppy.age)
# ---> 5
defaultdict
from collections import defaultdict
my_dict = defaultdict(lambda: 'デフォルトだよ')
my_dict['a'] = 100
print(my_dict['a'])
# ---> 100
print(my_dict['b'])
# ---> デフォルトだよ
# 存在しないキーにデフォルトを設定できるよ。だからデフォルトがあると、KeyErrorは起きないよ。
jhonnys = '嵐 嵐 嵐 関ジャニ 嵐'.split()
j_count = defaultdict(int) # intのデフォルトは0
for j in jhonnys:
j_count[j] += 1 # j++
print(j_count)
# ---> defaultdict(<class 'int'>, {'関ジャニ': 1, '嵐': 4})
grades = [('数学', '5'), ('理科', '4'), ('国語', '1'), ('美術', '2')]
grade_book = defaultdict(list) #デフォルトをリストにもできるよ
for course, grade in grades:
grade_book[course].append(grade)
for c, g in grade_book.items():
print("あなたの{} の成績は、{}です".format(c, " ".join(g)))
# --->
# あなたの理科 の成績は、4です
# あなたの数学 の成績は、5です
# あなたの美術 の成績は、2です
# あなたの国語 の成績は、1です
Sort dictionary
ディクショナリーのソート
grade = {'俺':10,'私':100,'僕':60,'おいどん':70}
# Method 1 lambdaでソート
print(sorted(grade.items(), key=lambda x:x[1]))
# ---> [('俺', 10), ('僕', 60), ('おいどん', 70), ('私', 100)]
# Method 2 itemgetterでソート
from operator import itemgetter
print(sorted(grade.items(),key=itemgetter(1)))
# ---> [('俺', 10), ('僕', 60), ('おいどん', 70), ('私', 100)]
2. Python do and don't
- 美しいコードを書くためのガイド
if文
# Do this
if n in [1,2,3]:
print(n)
# Don't
if n==1 or n==2 or n==3:
print(n)
Out of range: 要素が存在しないとき
list = ['a', 'b', 'c', 'd', 'e']
print(list[10:])
# ---> []
# 空っぽ
Repeating same things 同じ物を二度以上プリントするとき
# Don't!
thanku = "thanks for reading"
print('------------------------------')
print(thanku)
print('------------------------------')
# DO this instead
print('{0}\n{1}\n{0}'.format('-'*30, thanku))
# ---> 結果:
# ------------------------------
# thanks for reading
# ------------------------------
Opening the file ファイルを開ける
# Do if you want to write in one line
with open('file_name.txt', 'r') as f:
# ホニャララ
# ホニャララ
# file.close()書かなくてもいいよ
# Don't (or more like not good & easily forget to close)
# この書き方だといちいちclose()を書かなくちゃいけないのでsimplicityで言うなれば上の書き方が好ましいと思う
f = open('text.txt','r')
f.close()
Else right after loops ループ直後のelse文
# elseをfor/while loop直後に書かない
for i in range(1):
print("looping")
else:
print("ELSE BLOCK")
# --->
# looping
# ELSE BLOCK
# breakがはいるとelse文は出力されない
for i in range(5):
print(i)
break
else:
print("ELSE BLOCK IS NOT PRINTED")
# --->
# 0
underscore _ アンダースコア
a, _, b = (1, 2, 3)
print(a, b)
# ---> 1, 3
a, *_, b, c = (1, 2, 3, 4, 5, 6)
print(a, b, c)
# ---> 1, 5, 6
print(*_)
# ---> 2,3,4
infinity 無限数
my_inf = float('Inf')
print(99999999 > my_inf)
# ---> False
my_neg_inf = float('-Inf')
my_neg_inf > -99999999
# ---> False
def f(x, l=[]):
for i in range(x):
l.append(i * i)
print(l)
f(2)
# ---> [0, 1]
f(3, [3, 2, 1])
# ---> [3, 2, 1, 0, 1, 4]
f(3)
# ---> [0, 1, 0, 1, 4]
# なぜ最後の関数呼び出しは[0,1,4]じゃないの? なぜなら最初の関数を呼び出した時の l のメモリーを使っているから
try-except: Error Handling エラー対処方の書き方
- json, csv file, Database connectionとかapi requestの時とかによく使ってるよ
try:
a = 10 / 0
except ZeroDivisionError:
print("0で割るんじゃありません!")
# ---> 0で割るんじゃありません!
try:
a = 10 / 1
except ZeroDivisionError:
print("0で割るなって言ったばっかりやん!")
else:
print("よくやった")
# ---> よくやった
# エラーが起きなかった時に出力されるよ
try:
f = open('file_not_exist.txt')
var = bad_boy # <--これもエラーだけど他のエラーが先に起きたからおざなりにされたよ
except FileNotFoundError:
print('そんなファイル知らないよ')
except NameError:
print('そんな変数知らないよ')
# ---> そんなファイル知らないよ
# 最初に起こったエラーのexceptionが出力される
# FileNotFoundError, NameError
try:
ok = 1 / 2
not_ok = go_error
except NameError as e:
print(e)
# ---> name 'go_error' is not defined
try:
f = open('test.txt')
except FileNotFoundError as e:
print(e)
except Exception as e:
print(e)
finally:
print("エラーだろうが知ったこっちゃねえぇ")
# ---> [Errno 2] No such file or directory: 'test.txt'
# ---> エラーだろうが知ったこっちゃねえぇ
# 成功してもしなくてもfinallyの中は出力されるよ
# 自分でerror のカスタマイズをできるよ
try:
f = open('bad_file_name.txt')
if f.name == 'bad_file_name.txt':
raise Exception
except Exception:
print("その名前はあかんて")
finally:
print("まあええわ…")
# ---> その名前はあかんて
# ---> まあええわ…
yield★★★
# Bad 悪い
def dup(n):
A = []
for i in range(n):
A.extend([i, i])
return A
print(dup(3))
# ---> [0, 0, 1, 1, 2, 2]
# Good そこそこ
def dup(n):
for i in range(n):
yield i
yield i
print(list(dup(3)))
# ---> [0, 0, 1, 1, 2, 2]
# Better 良い
def dup(n):
for i in range(n):
yield from [i, i]
print(list(dup(3)))
# ---> [0, 0, 1, 1, 2, 2]
- generator についてもう少し詳しく書いていくよ
gen = (x*x for x in range(3))
for i in gen:
print(i)
# ---> 0
# ---> 1
# ---> 4
# もう一回出力しようとすると...
for i in gen:
print(i)
# --->
# 何も出ないよ。ジェネレーターは1回しか使えないよ。
###########################################################
sum((x*x for x in range(10)))
# ---> 285
sum(x*x for x in range(10)) # <-- ()内はジェネレーター
# ---> 285
###########################################################
def foo():
print("始")
for i in range(3):
print('*' * 20)
print(i, " の前:")
yield i
print(i, " の後")
print('*' * 20)
print("終")
f = foo()
print(next(f))
print(next(f))
print(f.__next__())
print(f.__next__())
# 計4回よんだよ。けど4回目のコールでは range(3)は0,1,2のみだからエラー
# --> 始
# --> ********************
# --> 0 の前:
# --> 0
# --> 0 の後
# --> ********************
# --> ********************
# --> 1 の前:
# --> 1
# --> 1 の後
# --> ********************
# --> ********************
# --> 2 の前:
# --> 2
# --> 2 の後
# --> ********************
# --> 終
# --> Traceback (most recent call last):
# --> File "sample.py", line 19, in <module>
# --> print(f.__next__())
# --> StopIteration
###########################################################
def createGenerator():
mylist = range(3)
for i in mylist:
yield i*i # return みたいな?
mygenerator = createGenerator() # ジェネレーターを作ろう
print(mygenerator) # mygenerator はオブジェクトだよ
<generator object createGenerator at 0x1029d71a8>
for i in mygenerator:
print(i)
# ---> 0
# ---> 1
# ---> 4
##############################################
# n個イテレーターからゲットしたい時
import itertools
def mygen():
for i in range(10):
yield i
my_list = mygen()
# 最初の5個をゲッチュ
top5 = itertools.islice(my_list, 5) # grab the first five elements
print(top5)
# ---> <itertools.islice object at 0x104039cc8>
for i in top5:
print(i)
# Starts from 5!!
print(next(my_list))
# ---> 0
# ---> 1
# ---> 2
# ---> 3
# ---> 4
# ---> 5 # (next(my_list)) から
list -> dict
dict_as_list = [['a', 1], ['b', 2], ['c', 3]]
dictionary = dict(dict_as_list)
print(dictionary)
# ---> {'a': 1, 'b': 2, 'c': 3}
# list -> dictionary + new stuff added!
dict_as_list = [['a', 1], ['b', 2], ['c', 3]]
dictionary = dict(dict_as_list, d=4, e=5)
print(dictionary)
# ---> {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5}
using true or false as a Index
# True と False をインデックスとして使お!
test = True # 1
# False の場合は 0
result = ['Test is False', 'Test is True'][test]
print(result)
# ---> Test is True
switch文の代わりみたいな
def poke_1():
print('ピカチュウ、君に決めた!')
def poke_2():
print('ゼニガメ、君に決めた!')
def poke_3():
print('ミュウツー、ゲットだぜ!')
def unknown():
print('ポケモンがいません。')
# 普通だったら if, elif, else で大抵やりすごすけど…
choice = 2
functions = {1: poke_1, 2: poke_2, 3: poke_3}
functions.get(choice, unknown)()
# ---> ゼニガメ、君に決めた!
Class
# class のメソッドを のちに変える
class Dog:
def method(self):
print('わんわん')
puppy = Dog()
puppy.method()
# ---> わんわん
def new_method(self):
print('バウバウっ')
Dog.method = new_method
puppy.method()
# ---> バウバウっ
##############################################################
# 色々なクラスメソッド
class Class:
@classmethod
def a_class_method(cls):
print("私は ", cls)
@staticmethod
def a_static_method():
print("私はどこから呼ばれたのだろう")
def an_instantce_method(self):
print("俺は ", self)
person = Class()
Class.a_class_method()
# 私は <class '__main__.Class'>
person.a_class_method()
# ---> 私は <class '__main__.Class'>
Class.a_static_method()
# ---> 私はどこから呼ばれたのだろう
person.a_static_method()
# ---> 私はどこから呼ばれたのだろう
person.an_instantce_method()
# ---> 俺は <__main__.Class object at 0x10cd87d68>
Class.an_instantce_method()
# ---> TypeError: an_instantce_method() missing 1 required positional argument: 'self'
Sorting Dictionary
- Note: Python3 dictionaries preserve insertion order
# Using Builtin function .sort() or sorted() to Dictionary will output an ordered list of (key, value) tuples. Thus if we want the dict output,
import collections
x = {1:10,2:3,3:9,4:2,0:4,8:11}
sorted_x = sorted(x.items(), key=lambda kv: kv[1])
print(sorted_x)
# ---> [(4, 2), (2, 3), (0, 4), (3, 9), (1, 10), (8, 11)]
sorted_dict = collections.OrderedDict(sorted_x)
print(sorted_dict)
# ---> OrderedDict([(4, 2), (2, 3), (0, 4), (3, 9), (1, 10), (8, 11)])
print(sorted_dict[4])
# ---> 2
Sorting tuple
# Sorting a List of Elements by the First element but if Equal sort by the second
same = [(13,'a'),(10,'a'),(10,'d'),(10,'b'),(10,'e'),(10,'c'),(0,'z'),(5,'f'), (0,'a')]
same.sort(key=lambda tup: (-tup[0],tup[1]))
print(same)
# ---> [(13, 'a'), (10, 'a'), (10, 'b'), (10, 'c'), (10, 'd'), (10, 'e'), (5, 'f'), (0, 'a'), (0, 'z')]
# 最初のタプルの要素をdescendingソート。もし同じ要素(この場合10や0)があったらascendingソートする。
Max from list of tuple
lis=[(3, 153),(10,200),(11,999), (2, 900), (1,1000)]
max(lis, key=lambda item:item[1])
# ---> (1, 1000)
3. 面白そうなLibraries, Modules
emoji :
- Site: https://pypi.org/project/emoji/
- 絵文字も表せちゃうんです
pip install emoji
from emoji import emojize
print(emojize(":thumbs_up:"))
# ---> 👍
print(emoji.demojize('Python is 👍'))
# ---> Python is :thumbs_up:
print(emoji.emojize(':alien:'))
# ---> 👽
PrettyTable:
- Site: https://pypi.org/project/PrettyTable
- テーブルをプリチーにしてくれる
from prettytable import PrettyTable
table = PrettyTable(['programming language', 'awesomeness'])
table.add_row(['Python', '100'])
table.add_row(['C++', '99'])
table.add_row(['Java', '80'])
table.add_row(['PHP', '40'])
print(table)
# --->
+----------------------+-------------+
| programming language | awesomeness |
+----------------------+-------------+
| Python | 100 |
| C++ | 99 |
| Java | 80 |
| PHP | 40 |
+----------------------+-------------+
wikipedia:
- Site: https://wikipedia.readthedocs.io/en/latest/quickstart.html
- wikipedia検索ができるよ
pip install wikipedia
import wikipedia
result = wikipedia.page('tsunami')
print(result.summary)
# --->
# A tsunami (from Japanese: 津波, "harbour wave";
# English pronunciation: soo-NAH-mee) or tidal wave, also known as a seismic sea
# wave, is a series of waves in a water body caused by the displacement of a large
# volume of water, generally in an ocean or a large lake. Earthquakes, volcanic #
# eruptions and other underwater explosions (including detonations of underwater
# nuclear devices),...
print(wikipedia.search("Barack"))
# ---> ['Barack Obama', 'Barack Obama Sr.', 'Family of Barack Obama', 'List of things named after Barack Obama', 'List of federal judges appointed by Barack Obama', 'Barack Obama citizenship conspiracy theories', 'Barack Obama Supreme Court candidates', 'Timeline of the presidency of Barack Obama (2009)', 'Barack (brandy)', 'Protests against Barack Obama']
Snowballstemmer:
import snowballstemmer
stemmer = snowballstemmer.stemmer('english');
print(type(stemmer))
# ---> <class 'snowballstemmer.english_stemmer.EnglishStemmer'>
print(stemmer.stemWords("We are the world".split()));
# ---> ['We', 'are', 'the', 'world']
from snowballstemmer import EnglishStemmer, SpanishStemmer
print(EnglishStemmer().stemWord("Gregory"))
# ---> Gregori
Calendar
- カレンダー
import calendar
cal = calendar.month(2018, 9)
print(cal)
# --->
September 2018
Mo Tu We Th Fr Sa Su
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
hello
import __hello__
# ---> Hello World!
import this
- ZEN of python
- pythonの心得みたいな
import this
# --->
# Beautiful is better than ugly.
# Explicit is better than implicit.
# Simple is better than complex.
# Complex is better than complicated.
# Flat is better than nested.
# Sparse is better than dense.
# Readability counts.
# Special cases aren't special enough to break the rules.
# Although practicality beats purity.
# Errors should never pass silently.
# Unless explicitly silenced.
# In the face of ambiguity, refuse the temptation to guess.
# There should be one-- and preferably only one --obvious way to do it.
# Although that way may not be obvious at first unless you're Dutch.
# Now is better than never.
# Although never is often better than *right* now.
# If the implementation is hard to explain, it's a bad idea.
# If the implementation is easy to explain, it may be a good idea.
# Namespaces are one honking great idea -- let's do more of those!
Colorama:
- Site: https://pypi.org/project/colorama/
- コードをカラフルにしましょう
from colorama import Fore, Back, Style
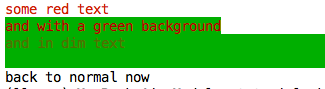
print(Fore.RED + 'some red text')
print(Back.GREEN + 'and with a green background')
print(Style.DIM + 'and in dim text')
print(Style.RESET_ALL)
print('back to normal now')
# --->
FuzzyWuzzy:
pip install fuzzywuzzy
from fuzzywuzzy import fuzz
# 比較対象の文字列がどのくらい似ているかの比率
print(fuzz.ratio("this is a test", "this is a test!"))
# ---> 97
fuzz.token_sort_ratio("fuzzy wuzzy was a bear", "wuzzy fuzzy was a bear")
# ---> 100
★Biopython★
- https://biopython.org
- bioinformatics やってる人向け
pip install biopython
from Bio.Seq import Seq
my_seq = Seq('CATGTAGACTAG')
print("ワイのDNAシーケンスは %s" %(my_seq))
# ---> ワイのDNAシーケンスは CATGTAGACTAG
googletrans
- 我らが相棒グーグル翻訳
- 現在なぜか使えんぬ...
- 公式: https://py-googletrans.readthedocs.io/en/latest/
- Stack overflowで質問: https://stackoverflow.com/questions/47725342/why-python-googletrans-suddenly-not-working
4. QUIZ
- ここまで読んだそこのあなた!今こそ得た知識を脳フル回転して使うべき!
- てな訳で、以下はネットで見つけたpythonトリックたちをクイズにしたもの(それぞれ原文リンク載せとくので参考に
- まずはパソコンでビルドせずに紙に書くなりして、何をアウトプットするか考えて見てね
Question 1: Python Interview Question FizzBuzz
# Q: What will this prints out??
print(' '.join(['FizzBuzz' if not(i % 3 or i % 5) else 'Fizz' if not i % 3 else 'Buzz' if not i % 5 else str(i) for i in range(1, 21)]))
# ただし実際にlist comprehensionを使う時は長くなりすぎぬよう気をつけよう
Question 2: next()
my_list = [1, 3, 6, 10]
a = (x**2 for x in my_list)
print(next(a), next(a))
Question 3: Decorator
def Foo(n):
def multiplier(x):
return x * n
return multiplier
a = Foo(5)
b = Foo(5)
print(a(b(2)))
Question 4: map
# Question:
x = list(map(len, [1, 2, 3]))
print(x)
# hint: list内の1,2,3 はそれぞれint, 整数型
# Question2:
y = list(map(len, ['1', '2', '3']))
print(y)
Question 5: filter
x1 = {'x': 1}
y2 = {'y': 2}
x3_y4 = {'x': 3, 'y': 4}
ans = list(filter(lambda d: 'x' in d.keys(), [x1, y2, x3_y4]))
print(ans)
5. 参考文献:
- An A-Z of useful Python tricks
- useful modules
- Awesome Python
- essential python tips tricks
- 30 Python Language Features and Tricks You May Not Know About
- Python 3 Patterns, Recipes and Idioms
- 10 Neat Python Tricks Beginners Should Know
- Effective Python by BrettSlatkin (ガチおすすめ本)
- What’s New In Python 3.0