EC2(スポット)インスタンスでChainerMNを使う(マルチノード分散学習)
概要
- EC2(スポット)インスタンスでChainerMNのマルチノード分散学習をする方法
- 環境変数の設定方法
- sshに
StrictHostChecking noを追加 - セキュリティグループの設定(VPC内からの全アクセスを許可)
- EC2上でマルチノード分散学習する場合の注意点
-
p2.xlargeを使ってマルチノード分散学習は性能がでない -
g3.4xlargeを利用すると良い
-
- マルチノード学習した際の性能の簡単な評価
- ImageNetの学習では
p2.8xlargeを使う時と同等かそれ以上のコストパフォーマンス
- ImageNetの学習では
やりたかったこと
スポットインスタンスの価格が比較的安いGPU1個のインスタンス(p2.xlargeやg3.4xlarge)を複数使って、ディープラーニングの学習を高速化させたかった。
学習を高速にする手段としては、マルチノードで分散する以外に、そもそも1台あたりのGPU数を増やす、という選択肢もある。
しかし、GPUを複数個積んでいるEC2のインスタンスはどれも高いし、スポットインスタンスで価格を抑えられないことがある。例えば、p2.8xlargeはオンデマンドインスタンスの場合、$7.2/hかかる。スポットインスタンスの価格は、ここ1週間くらいはp2.8xlargeが$2.5/h弱のようだが、ちょっと前は$72/hに張り付いていた。
あるいは、自前で学習用計算機用意する手もあるが、GPU複数台積むマシンとなるとかなり高くつくことになる。個人の趣味の範囲内だと、電気代を抜いてもAWSを使うより高くなる可能性が高そう。
なので、p2.xlargeなどのスポットインスタンスでの値段が低め(〜$0.3/h)で抑えられているインスタンスを複数利用して、学習を高速化させるという方針に至った。オンデマンドのp2.8xlargeと比べて、スポットインスタンスのp2.xlargeやg3.4xlargeは1GPU当たりの値段で1/3ほどなので、マルチノードの分散学習の複雑さや効率の悪さはGPUの台数で補えるという目論見。
ChainerMNを使った分散学習 in AWS
環境の準備
ChainerMNのインストール
ChainerMNをインストールする方法自体は、もう多数の記事・情報があるので、詳細は省く。自分はこことChainerMNのチュートリアルを参考にした。
やったことを列挙すると、以下の通り。
- CUDA 8.0のインストール
- cuDNN 6.0のインストール
- NCCL 1.xのインストール
- GitHubのページにはno longer maintainedとあるが、まだNCCL2は使えかった
- OpenMPIのビルド・インストール
- Chainer、ChainerMNのインストール
この作業はGPUを積んでいる中で安いインスタンス(p2.xlarge)を利用すると良い。
環境変数の設定
sshに非対話モードで入った時に、CPATHやLD_LIBRARY_PATHが適切な値(具体的にはcudaのパスを含む)になっていないと学習スクリプトがうまく動かない。
/etc/bash.bashrcを以下のようにした。
export PATH=/usr/local/cuda-8.0/bin:${PATH}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:${LD_LIBRARY_PATH}
export CPATH=/usr/local/cuda-8.0/targets/x86_64-linux/include:${CPATH}
以下のコマンドを叩いた時、PATHやLD_LIBRARY_PATHが適切に設定されていれば良い。
$ ssh localhost 'env'
sshの設定
マルチノード分散学習をする際、インタラクティブな操作なしに別ノードへsshで接続できる必要がある。したがって、鍵認証の設定をする。また、デフォルトでは最初に接続しようとすると、Are you sure you want to continue connecting (yes/no)? のメッセージが出て、yes/noの入力を求められるので、手間を考えるとこれも対処する必要がある。
まず、鍵認証の設定をする。
$ ssh-keygen #パスフレーズなし、~/.ssh/id_rsaに置く
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
次に、.ssh/configを以下のとおりにして、yes/no入力をなくす
Host *
StrictHostKeyChecking no
どちらもセキュリティ上良いとは言えないが、最終的にはAWSのセキュリティグループで外部ネットワークからのインバウンドを遮断して運用すれば許容範囲と思っている。
ENAの有効化
必要なのかはわからないが、UbuntuはデフォルトではENAが有効になっていないようだったので、有効にする。最新の手順はここにあるので、これの通りに行う。
やるべきことは以下の3つ
- インスタンス上で、ENAのモジュールを追加
- インスタンスを停止
- ローカルからaws CLIでENAを有効化
AWS上のリソースの準備
1. VPC、サブネット、プレイスメントグループの準備
それぞれ適当な名前で準備する。VPCとサブネットは一度EC2インスタンスを起動すればついでにできるし、プレイスメントグループは、EC2のコンソールから、ネットワーク&セキュリティ → プレイスメントグループのページに行って作成すれば良い。
なお、プレイスメントグループはいるのかどうか分からないが、ネットワークの帯域幅をフルに出すには必要らしいので自分は作成した。
2. 学習ノード用のセキュリティグループの準備
セキュリティグループの準備も必要。インバウンドルールでは、「すべてのトラフィック・すべてのポート範囲へのVPCからのアクセス」を許可する。本来はもっと絞りこめると思うが、調べるのが面倒だったのでVPC内に全部公開した。
EC2コンソール上では、すべてのトラフィック すべて 0-65535 カスタム <VPCのCIDR>となっていれば良い。
3. (Optional) AMIの作成
必要はないが、ここまで終えた時点でAMIを作っておくと別のことをしたい時に無駄な出費を防げる。
AMIの作成方法は省略。
学習スクリプトなどの準備
最後に、学習用のスクリプト、データセットなどを準備する。
今回、自分はchainermnについているImageNetのサンプルを使った。
git clone --depth 1 https://github.com/chainer/chainermn.gitとして、chainermnのソースを落とすとchainermn/examples/imagenetの下にImageNetのサンプルがあるのでこれを用いる。また、自分の場合、models_v2/nin.pyをchainerのexamples/imagenet/nin.pyに置き換えないと動かなかったので、chainerのソースも落としてきてcpした。
次に、データセットを準備する。データセットの準備方法は、ここやここなどが参考になる。
ここまで終えたら、インスタンスを止めてAMIを作成する。
実行方法(1ノード)
テストも兼ねて1ノードで学習を走らせる場合は、インスタンスを起動した後、sshでログインして、
$ mpiexec -n 1 python3 ~/chainermn/examples/imagenet/train_imagenet.py train.txt test.txt
などとすれば良い。ここで、train.txt、test.txtはそれぞれ準備したデータセットのパス
実行方法(マルチノード)
上で作成した学習スクリプトの入ったAMIを利用し、スポットインスタンスを適当に何個か立ち上げる。この時、VPC、プレイスメントグループ、セキュリティグループは上で準備したものを忘れず利用する。
なお、別にスポットインスタンスでなくてもいいが、費用を抑えて実験してみたいだけならスポットインスタンスの方が適していると思う。ただし、スポットインスタンスが突然中断するリスクを減らすため、高めに価格を設定しておくと安心。
また、多少値段は上がるが、p2.xlargeでなく、g3.4xlargeを使うと良い (理由は"注意点"で後述)。
以下では、2台のg3.4xlargeインスタンスを立ち上げ、それぞれのプライベートIPが172.31.41.13、172.31.41.14となったとする。
まず、どちらか1台(以下では172.31.41.13の方とする)にsshでログインする。ログインしたら、以下の内容のホストファイルを~/hostfileに作成する(パスはどこでも良い)。
172.31.41.13 cpu=1
172.31.41.14 cpu=1
(プライベートIPは、その時立ち上げたスポットインスタンスを見て適宜修正する必要あり。)
次に、以下のコマンドを叩くと、2台のマシンで分散学習される。
$ mpiexec -n 2 --hostfile ~/hostfile python3 ~/chainermn/examples/imagenet/train_imagenet.py train.txt test.txt
注意点(ネットワークの帯域幅を考慮する必要あり)
GPU付きインスタンスの中では**p2.xlargeが値段は安いのだが、ネットワークの帯域幅が小さく、性能が出なかった**。iperfを使ってはかった結果では、1.44Gbps。一方、g3.4xlargeは10Gbpsでるというスペックだし、実際iperfではかると10Gbpsでた(情報提供:https://twitter.com/grafi_tt/status/895274632177000449 )。
いくら安く分散学習させたいと言っても、p2.xlargeだと性能向上が見られなかったので、g3.4xlargeを使う方が良いと思う。
性能確認
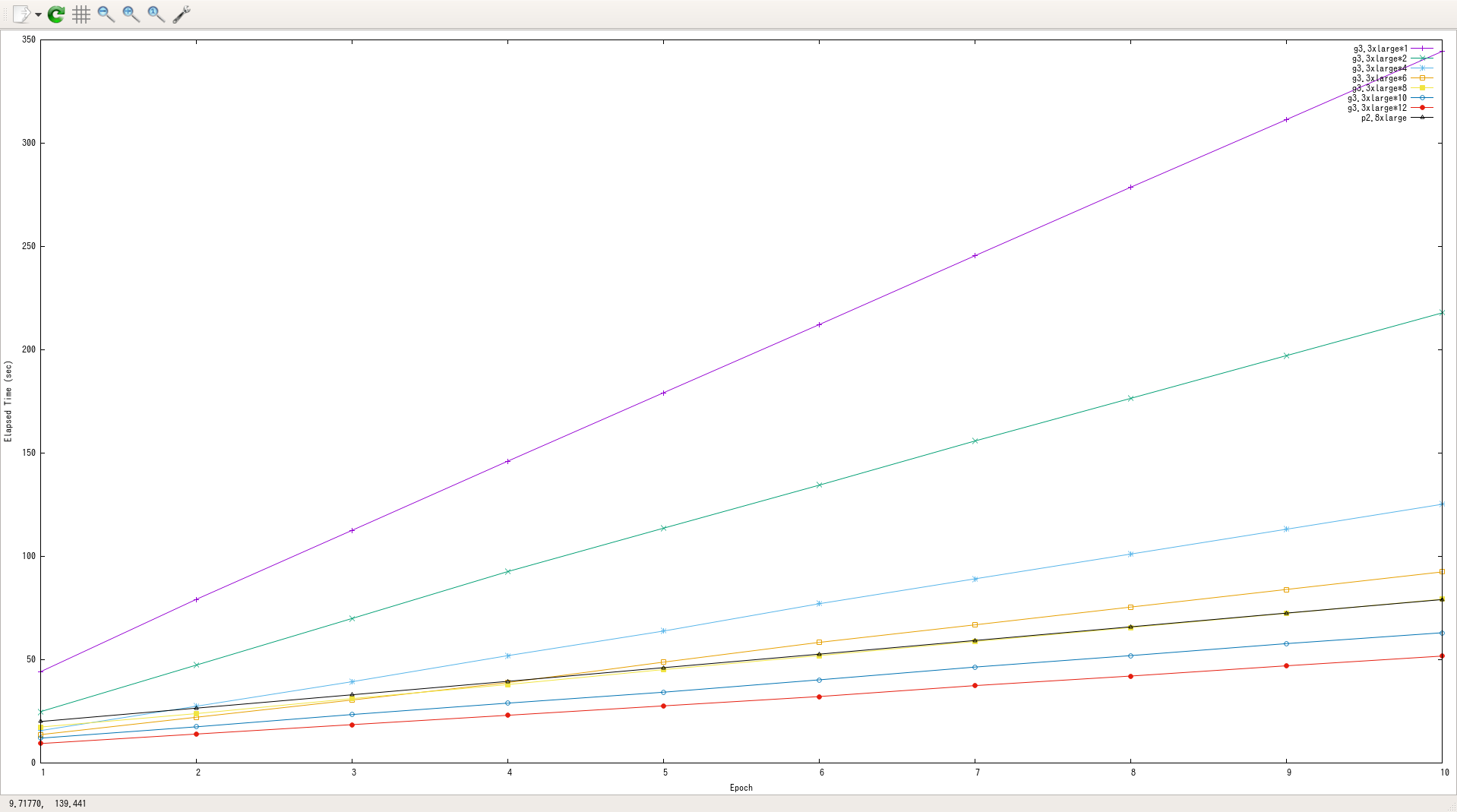
学習が高速化できるのか確認するため簡単な性能測定をした。なお、どれも1回しか計測してないし、真面目に条件を揃えたわけではないので、数字は参考程度に。
以下のパターンで、ImageNetの学習にかかる時間を測定した。
-
g3.4xlarge1台で、ChainerMNを利用 -
g3.4xlarge複数台(2, 4, 6, 8, 10, 12)で、ChainerMNを利用 -
p2.8xlarge(8GPU)で、ChainerMNを利用
結果
以下の通り。
分散すればちゃんと高速化されるし、p2.8xlargeと比べても安いまたは同等程度の値段でほぼ同じ性能を出せている。ただ、この辺は学習させるネットワークやデータセットによって色々異なるんだろうな。
表1: 1エポック当たりの時間
| 条件 | 1エポックあたりの平均時間 (sec) |
|---|---|
g3.4xlarge*1 |
34.4 |
g3.4xlarge*2 |
21.8 |
g3.4xlarge*4 |
12.5 |
g3.4xlarge*6 |
9.2 |
g3.4xlarge*8 |
7.9 |
g3.4xlarge*10 |
6.3 |
g3.4xlarge*12 |
5.2 |
p2.8xlarge |
7.9 |
ちゃんと分散するにつれて短い時間で学習できている。
表2: 値段 - 総実行時間
| 条件 | 値段 ($/h) | 総実行時間 (sec) |
|---|---|---|
g3.4xlarge*1 |
0.3 | 344.3 |
g3.4xlarge*2 |
0.6 | 217.8 |
g3.4xlarge*4 |
1.2 | 125.2 |
g3.4xlarge*6 |
1.8 | 92.4 |
g3.4xlarge*8 |
2.4 | 79.2 |
g3.4xlarge*10 |
3.0 | 63.0 |
g3.4xlarge*12 |
3.6 | 51.7 |
p2.8xlarge |
7.2(オンデマンド) / 2.5(スポットインスタンス利用時) | 79.1 |
備考:g3.4xlargeのスポットインスタンスの値段は$0.3/hとして計算
p2.8xlargeをオンデマンドで利用する場合に比べると、より安く高速な学習ができる。p2.8xlargeがスポットインスタンスの場合と比べても、ほぼ同等の性能が今回の例では出た。
グラフ1: epoch - elapsed_time
グラフ2: epoch-validation/main/accuracy
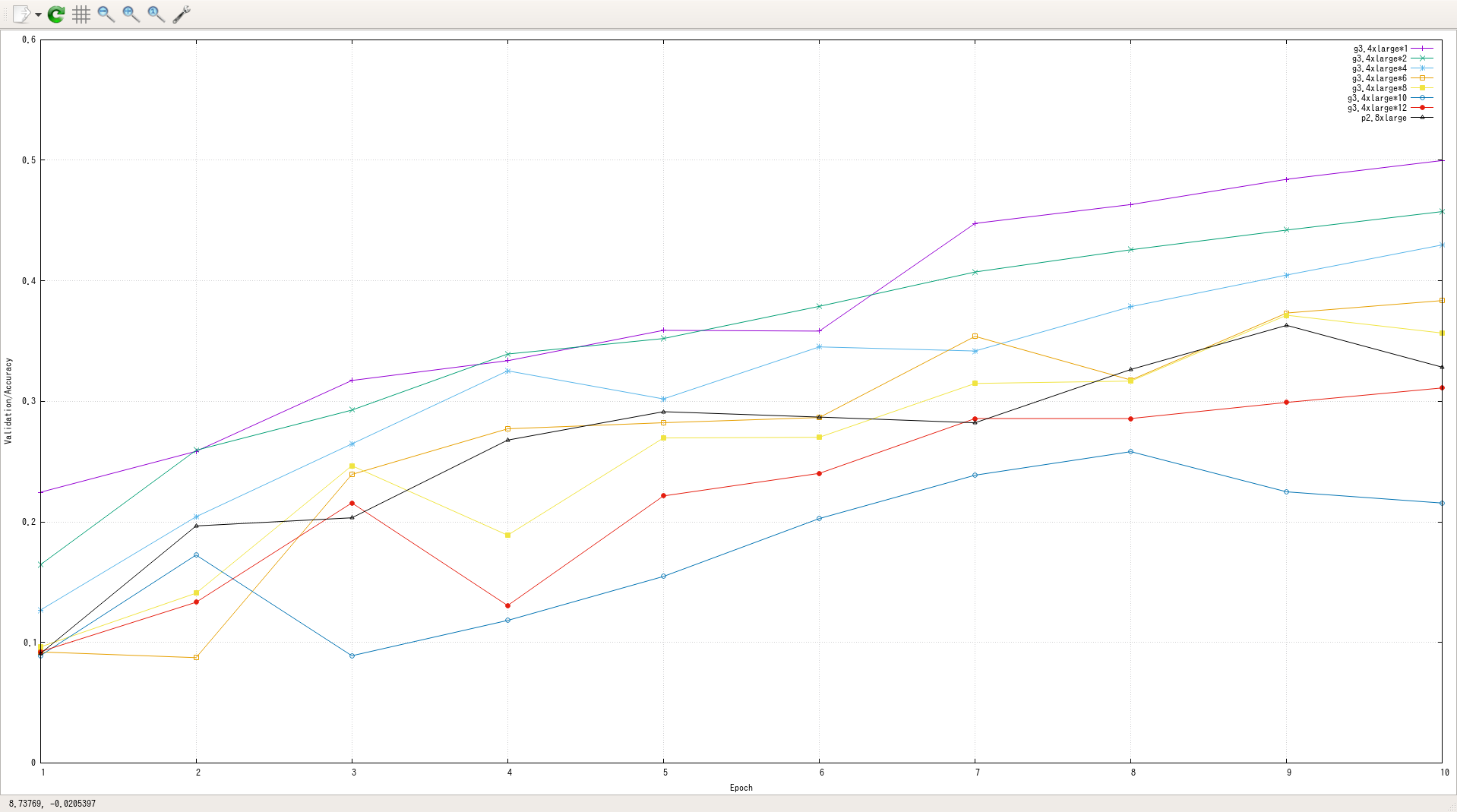
epochが少なすぎてわかりやすいデータにならなかったが、分散させるほど同エポックでの精度は悪化する傾向にあるらしい。直感的にもそんな気はする。とはいえ、マルチノードの場合とp2.8xlargeでノード内で分散した場合では大きな精度の差は見つけられない。分散学習するなら、エポックを大きめに設定する必要があるようだが、それはマルチノード分散学習の問題というより、現在のChainerMN全体の問題の可能性が高い。
その他備考:
分散学習では、最初の1回のmpiexecは時間がかかるらしい。上記計測は、2回目のmpiexecで行っている。原因は、ノード間の接続を確立する時間が追加されているからではないかと思うが、詳細は不明。ただし、学習時間が長くなるにつれて、その時間は無視できるものになると思われる。
まとめとか
少なくともImageNetでは、マルチノードの分散学習でも相当の学習時間の短縮が見込める。また、8/7からChainerMNを初めて5日でここまでできたので、非常に難しい作業が必要というわけでもない。
そのため、AWS上でのディープラーニング学習を高速化させたい時、選択肢に入れる価値はあると思う。最初に書いたような、複数GPUを積んだスポットインスタンスが高い時にも使えるし、あるいはp2.8xlargeを複数使ってさらに高速化する、という使い方もマルチノードの分散学習はできるはず。
一方で、データセットが増えた時どうなるのか、モデルが複雑になった時どうなるのか、などは調べてない。実際に使ってみるとたいして高速化されなかった、みたいなケースはありそう。
要改善点
とりあえずテストするだけなら上記手順でもできたが、実際にディープラーニングを利用するプロジェクトに組み込むとなると以下の点を改善しないといけない。
学習スクリプトの実行方法
本来は、aws CLIとかSDKからスポットインスタンスを立ち上げて、自動で学習を回したい(ここみたいに)。
そのためには、UserDataのスクリプトで学習スクリプトを実行する必要があるが、以下の点に注意が必要。
-
mpiexecをするインスタンスの決定方法 - ホストファイルの作成方法
- すべてのインスタンスが立ち上がるまでの待ち合わせ処理
1については、特定のタグを全インスタンスに付けておき、aws ec2 describe-instancesで全インスタンスのプライベートIPを取得、辞書順最小のインスタンスでmpiexecすれば解決しそう。
2は、describe-instancesした時に全部のプライベートIPがわかるんだからホストファイルもついでに生成できる。
3は、ポーリングなりなんなりでやればできるはず。この時、ついでに学習パラメータの環境変数への展開やS3からデータセットのダウンロードも待ち合わせ処理すると色々便利そう。
中断時の対処
スポットインスタンスなので、たまに強制終了させられることがある。
- 定期的なS3へのスナップショットアップロード(systemd-timer)
- 1台でも終了したら全台終了して無駄な出費の削減
- 学習開始時にスナップショットがあればそれを読み込み
の3つの対処が必要。