昨日はテーブル作ってデータをインポートするところまでやりました。今日はSQL書いてデータを取り出して、分析みたいなことをしてみます。
SQLを基本からコツコツやる
昔SQL書いたことあるけど、そんな昔のことを覚えているはずはありません。というわけで、基本からコツコツやります。Sequel ProでSQL文を書いたり実行したりは、「クエリ」からできます。
- twitterテーブルから全てのカラムを取ってくる:
SELECT * FROM twitter; - twitterテーブルのデータ数を取ってくる:
SELECT COUNT(*) FROM twitter; - twitterテーブルから、tweet本文にリンクを含むデータの全てのカラムを取ってくる:
SELECT * FROM twitter WHERE tweet_text LIKE '%http%'; - twitterテーブルの曜日ごとのデータ数を取ってくる:
SELECT DAYNAME(tweet_datetime), COUNT(*) FROM twitter GROUP BY 1;
分析に必要なデータを取り出す
Twitterのデータを分析して知りたいこととして、「内容は別として、何曜日の何時頃にどんな内容をtweetすれば、みんなに見てもらえるのかなー」ということがあります。というわけで、ちょっと切り分けてみました。
- 何曜日のtweetが一番よく見られているのか
- 何曜日のtweetのURLが一番よくクリックされているのか
- 何時のtweetが一番よく見られているのか
- 何時のtweetのURLが一番よくクリックされているのか
というわけで、こちらも基本から一歩一歩。まずはURLを含んだtweetとそのインプレッション数を曜日ごとに取ってきてみます。
SELECT DAYNAME(tweet_datetime), impression FROM twitter WHERE tweet_text LIKE '%http%' ORDER BY 1;
次に、URLを含んだtweetと、そのURLクリック数を曜日ごとに取ってきてみます。
SELECT DAYNAME(tweet_datetime), click_URL FROM twitter WHERE tweet_text LIKE '%http%' ORDER BY 1;
さて、合わせて取ってきてみます。
SELECT DAYNAME(tweet_datetime), impression, click_URL FROM twitter WHERE tweet_text LIKE '%http%' AND tweet_text NOT LIKE '%#ssci_new%' ORDER BY 1;
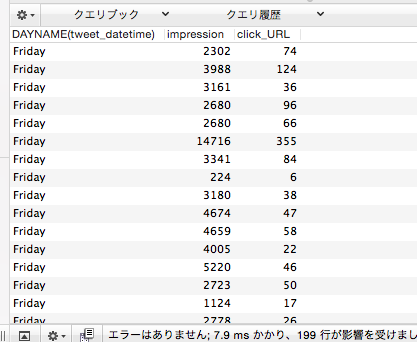
こんな感じで出てきます。やはり、数字が並んでいただけでは意味がわからない。というわけで、平均とか標準偏差とか中央値とかを求めてみたいところです。リファレンスを眺めてると簡単に見つかったので、まずは標準偏差と平均を出してみます。
SELECT DAYNAME(tweet_datetime), STD(impression), AVG(impression), STD(click_URL), AVG(click_URL) FROM twitter WHERE tweet_text LIKE '%http%' GROUP BY 1;
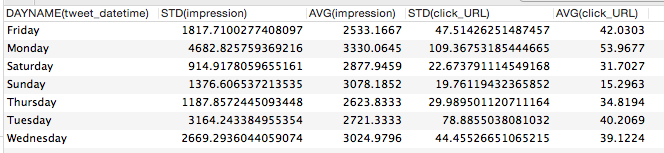
なんだかわかったような気にはなるけれども、これから言えることは何もなさそう。とにかく中央値を知りたいところ。が、とっても残念なことにmySQLには中央値を求める関数がありません。なのでさっき求めた「URLを含んだtweetと、そのインプレッション数およびURLクリック数を曜日ごとに取ってくる」SQL文で出た結果をcsvでエクスポートし、googleスプレッドシートで中央値を求めることにします。エクスポートはウィンドウのしたの歯車っぽいアイコンからできます。
あとはcsvファイルをgoogleさんに上げて、スプレッドシートで開いて中央値求めるだけ。これで、何曜日のインプレッションが良さそうで、何曜日のクリックが多そうか、なんとなく分かるのではないかと。
現在の問題点
「URLを含むtweet」では、対象として不十分
今回はURLの含まれるtweetを対象にデータを取り出しましたが、本心ではブログのURLが含まれるtweetだけを対象にしたいです。しかし、現時点ではそれができません。twitterは文字数の関係で、自動でURLを短縮してくれています。TwitterのAnalyticsからエクスポートできるcsvには、その短縮されたURLしか載っていません。なので、そのURLを見ても、それがブログのURLなのか違うのかわかりません。
この問題は、自分では解決できないので、hogelogに助けてもらいました。具体的にはtweet本文に含まれるURLを展開して、ブログのURLかそうでないかを判別し、別のテーブルに入れるプログラムを書いてもらいました。別のテーブルが絡むので、今日と同じ感じにはできないと思われます。もちろん忘れているので、次回はそこから始めます。
中央値を求めるだけでいいのかよく分かっていない
平均ではダメってことは分かります。インプレッションは幾何平均のほうがいいのかもしれない。クリック数はまれに0のことがあるので幾何平均ではダメ。この辺り、現在勉強中です。
参考にしたURL、本
- MySQL 5.6リファレンスマニュアル:https://dev.mysql.com/doc/refman/5.6/ja/
- 入門統計学 -検定から多変量解析・実験計画法まで-:http://www.amazon.co.jp/dp/B00QGK2Z4W
この統計学の本はまだ少ししか読めていません。問題点2を解決したくて読んでみているのですが、今のところ面白くてスラスラ読めます。入門者に本当にちょうど良い感じです。