前回はTensorFlow.org掲載の「GET STARTED」をスカラー版からテンソル版(つまり学習させるデータが数値ではなくベクトルorテンソル)に拡張した例を共有しました。
前回 http://qiita.com/MATS_ELB/items/fec7f54de2dd18b043ae
今回は、その学習データを記録し、TensorFlowに装備されているTensorBoardを用いて可視化し、機械の学習とは何かを考えてみます。
[1] コードを書き換える
前回記載したPythonのコードを少し改修して、TensorBoardが読み込むデータを生成し書き込むようにします。前回とは変わらない部分のコメントは削除し、今回の改修部分にコメントを記載しました。
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
W_data = np.array([[0.1, 0], [0, 0.1]])
b_data = np.array([0.3, 0.3])
x_data = np.random.rand(100, 2, 1).astype("float32")
y_data = W_data * x_data + b_data
W = tf.Variable(tf.random_uniform([2, 2], -1.0, 1.0))
b = tf.Variable(tf.zeros([2]))
y = W * x_data + b
# TensorBoardへ表示するための変数を用意する(ヒストグラム用)
W_hist = tf.summary.histogram("weights", W)
b_hist = tf.summary.histogram("biases", b)
y_hist = tf.summary.histogram("y", y)
loss = tf.reduce_mean(tf.square(y_data - y))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# TensorBoardへloss(学習のダメ具合の指標として設定したスカラー値)を表示するための変数を用意する(イベント用)
loss_sum = tf.summary.scalar("loss", loss)
sess = tf.Session()
# 上記で用意した合計4つのTensorBoard描画用の変数を、TensorBoardが利用するSummaryデータとしてmerge(合体)する
# また、そのSummaryデータを書き込むSummaryWriterを用意し、書き込み先を'/tmp/tf_logs'ディレクトリに指定する
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("/tmp/tf_logs", sess.graph_def)
init = tf.initialize_all_variables()
sess.run(init)
# 学習を1000回行い、10回目ごとにSummaryデータを保存し、画面にWとbのその時点の値を表示する
for step in xrange(1001):
if step % 10 == 0:
result = sess.run([merged, loss])
summary_str = result[0]
writer.add_summary(summary_str, step)
print step, sess.run(W), sess.run(b)
else:
sess.run(train)
上記を実行すると、サーバの /tmp/tf_logs ディレクトリの下に「event」で始まるログファイルが出来ます。これが機械学習の過程と結果を記録したSummaryデータです。
[2] TensorBoardで学習でできたSummaryデータを見る
※「TensorBoardはウェブサーバで画面を表示し、見る人はブラウザで見るので、SummaryデータがあるサーバでApacheなどのHTTPdが動いている必要があります。それを前提に」と投稿時に書いたのですが、誤りでした。TensorBoardを利用する際、HTTPdを走らせる必要は無いことを確認しました。
下記を実行します。
tensorboard --logdir=/tmp/tf_logs
そして、ブラウザでそのサーバのポート6006を指定してアクセスすると、TensorBoard画面が開きます。EVENTSのビューには「学習のダメ程度」を表すlossの推移が、HISTOGRAMSのビューには学習で得られたWとbの推移が表示されています(下図)。
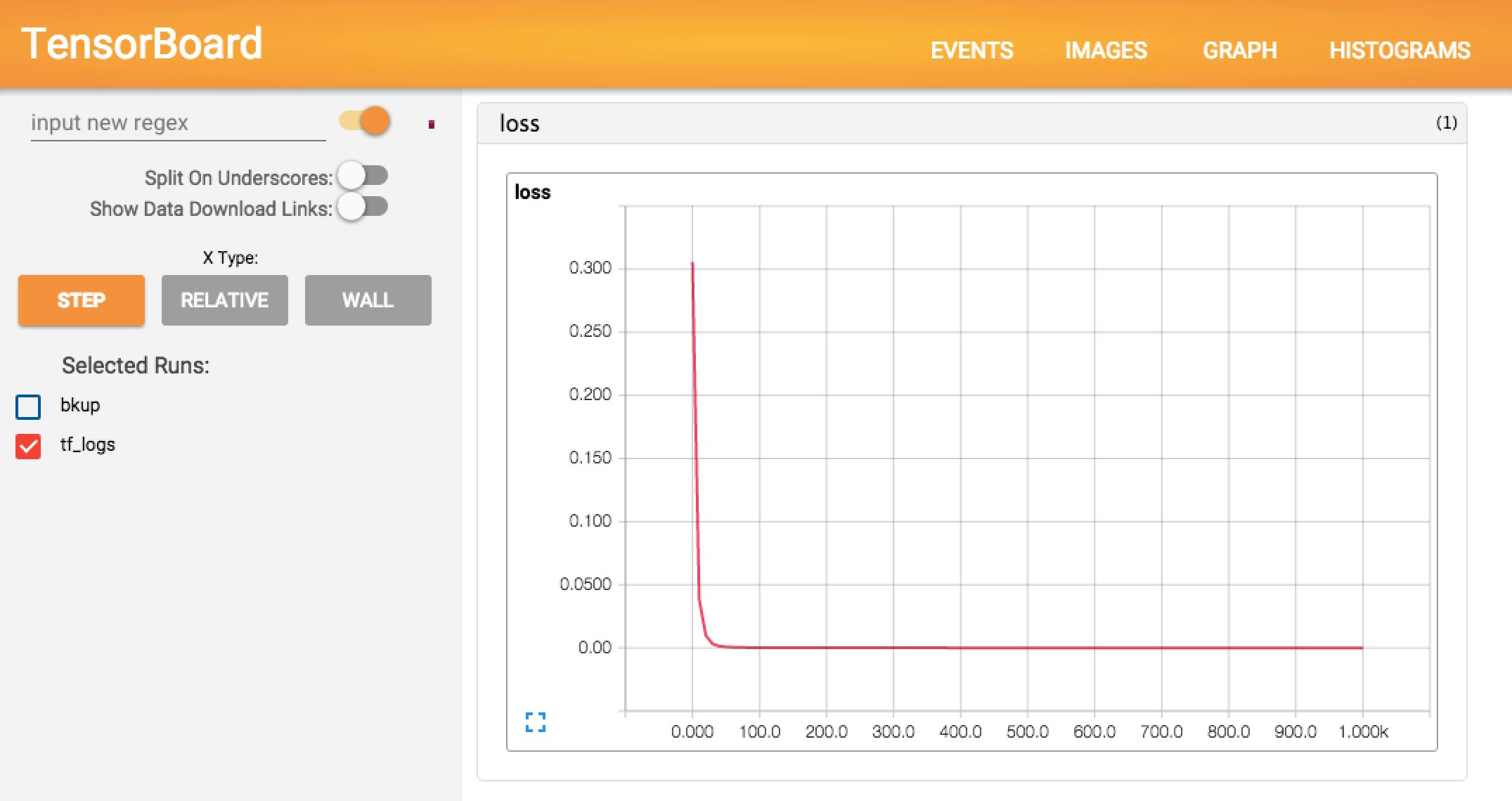
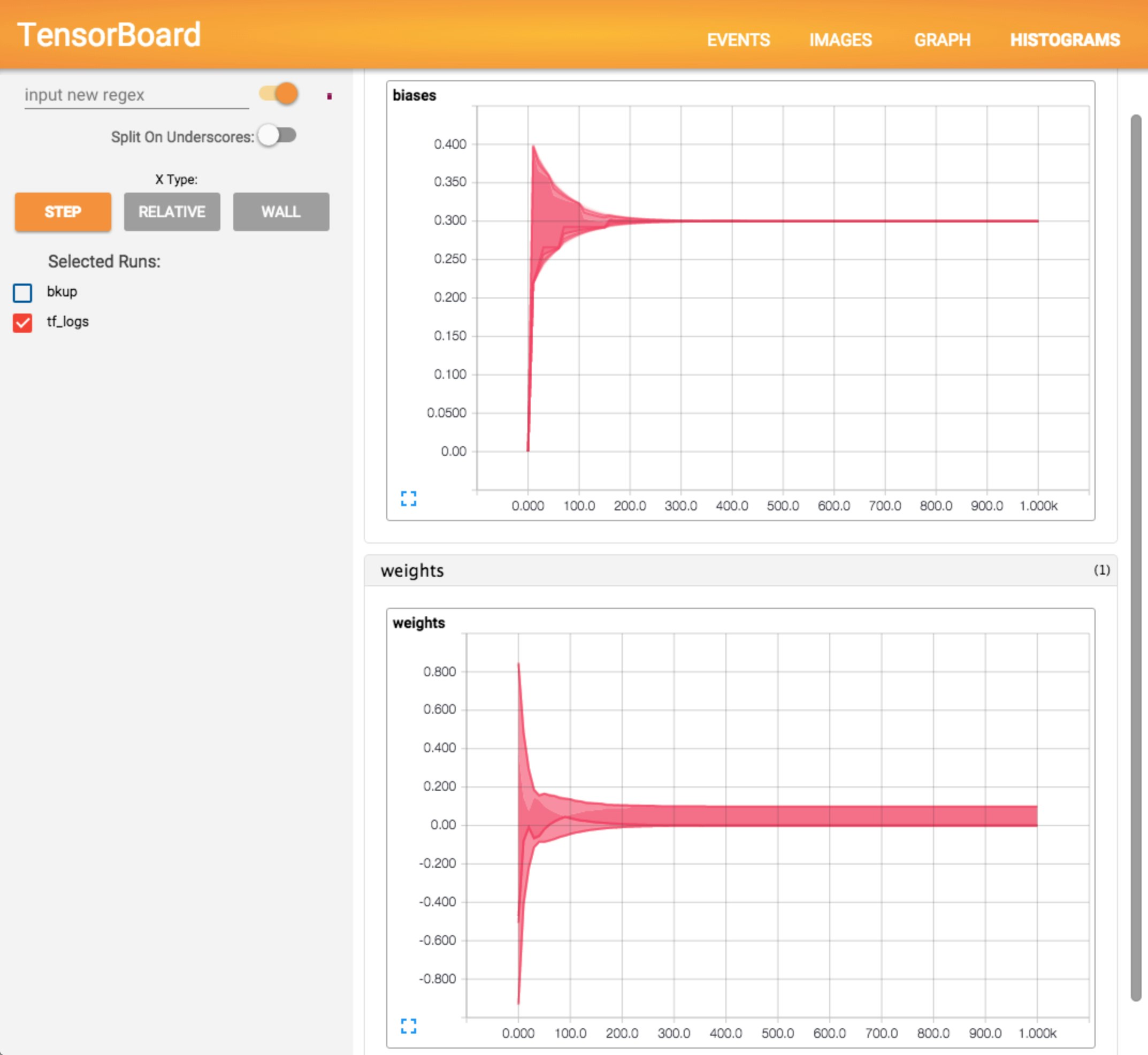
これらの意味を考えてみましょう。lossの値は学習回数が30回程度で0に収束していますので、用いた評価関数(学習データのy_dataと実出力のyの差分の2乗)で見て『学習ができている』様子が伺えます。Wもbもそれぞれ収束しているように伺えます。こうして可視化することによって「学習が適切に行われたか」をざっくり把握することができます。
[3] これでいいのか?
上記では「ざっくり把握することができる」と曖昧に書きました。それはなぜでしょうか?機械が学習の対象とする学習データが内包するパターンorルールが今回のケース(数学でいえば1次関数の入力と出力)のようなシンプルなケースの場合、評価関数が示す誤差がしばらく0であれば正常に学習が完了したと見なせるでしょうが、複雑なケースの場合はどうでしょうか?また、今回のケースでは学習最適化の手法を「最急降下法(勾配法)」という、いわば「lossを標高に見立てて、最も低い場所に辿り着くために、その時点で自分がいる場所で坂が一番急な方向に進むことを繰り返す」方法で行いました。自分がいる世界(=学習データのパターン)が下るだけの坂道世界ならその方法で一番低い場所(学習データの本当の正常完了)に辿り着けるかもしれません。歩いていく歩幅が大きい場合、最も低い場所をまたいでしまうかもしれませんが。自分がいる世界が山あり谷ありの地形だったらどうでしょう?遠くの山の向こうには今いる場所よりも深い谷があるかもしれないのに、ひたすら下に下るという学習最適化手法であるために山越えをせず局所的な「一番低い場所」に甘んじてしまうのではないでしょうか?例えば、鎖国していた頃の日本人は「富士山は世界一高い」と思っていたが、鎖国が解けて、海外にはもっと高い山があると知った状態です。
ということで、次回は精度の高い学習をするために何をどうしたら良いのかを考えてみます。みなさんからのアドバイス、喜んで伺いたいのでどうぞ宜しくお願い致します。
続編はこちらへ http://qiita.com/MATS_ELB/items/98d32ca79c3e8261ff1a