概要
KDD2016 workshopに出てる, IBM Research, Indiaの人の「[Joint multi-modal representations for e-commerce catalog search driven by visual attributes] (https://kddfashion2016.mybluemix.net/kddfashion_finalSubmissions/Joint%20multi-modal%20representations%20for%20e-commerce%20catalog%20search%20driven%20by%20visual%20attributes.pdf) 」をchainerで実装しようというものです.
論文の手法の元論文はこちらです.
この論文の本実装は,Theanoで書かれています.
論文の内容は,ざっくり読んだ感じ,テキストと画像がペアで与えられたとき,その共通空間をNeural Netを使って求めて(手法名は「Correlational Neural Net, 略してCorrNet」)検索エンジンに役立てようというなものになってます.
2つの異なるモーダルの共通空間を求める場合,CCAを使うのが一般的かと思いますが,実用上scikit-learnのCCAはデータサイズが大きくなるととたんに訓練に時間がかる&MemoryErrorで使い物にならないこともありますし,今回はサクッとchainerで実装してみました.
python3で,jupyter notebookで書いたコードは**こちら**です.
相関係数を共通空間で大きくなるように学習させるのがポイントみたいです.
イメージ図
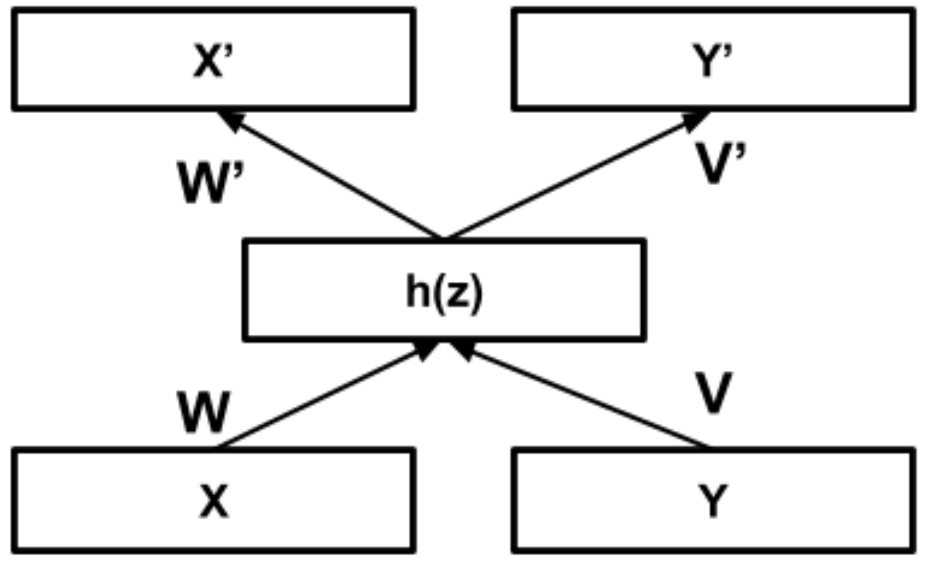
ロス関数は,2つのモーダルが与えられたとき両方復元する際の損失,片方のモーダルが与えられたとき両方復元する際の損失,そして隠れ層での相関が高くなるようにする損失で構成されてます.
使用したデータ
簡単に試してみたかったのでMNIST使って,28x28の画像と,one-hot-vector形式にしたラベル情報の共通空間を求めました.
今後違うデータでも試すつもりです.
結果
もともとの画像

復元後の画像(「画像」 → 「画像」)

うまく復元できてるようです
ラベルを使っての復元後の画像(「ラベル」 → 「画像」)
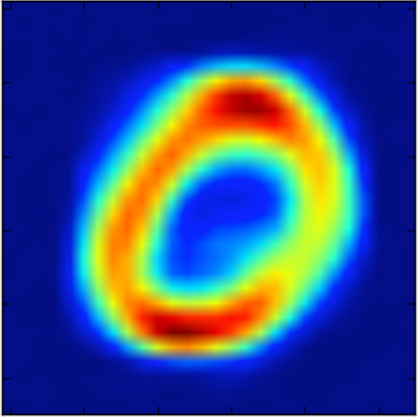
ラベル情報を組み合わせて(0と8)の復元後の画像(「ラベル」 → 「画像」)
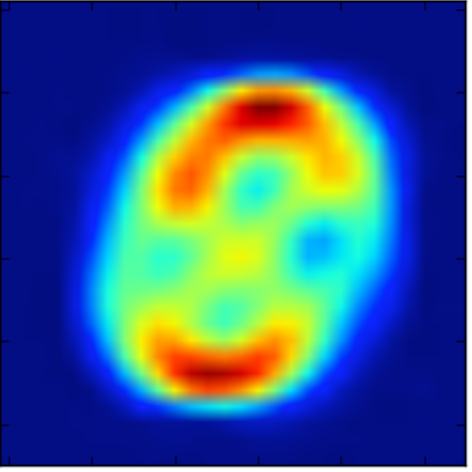
0と8の中間のような画像がちゃんと生成されております.
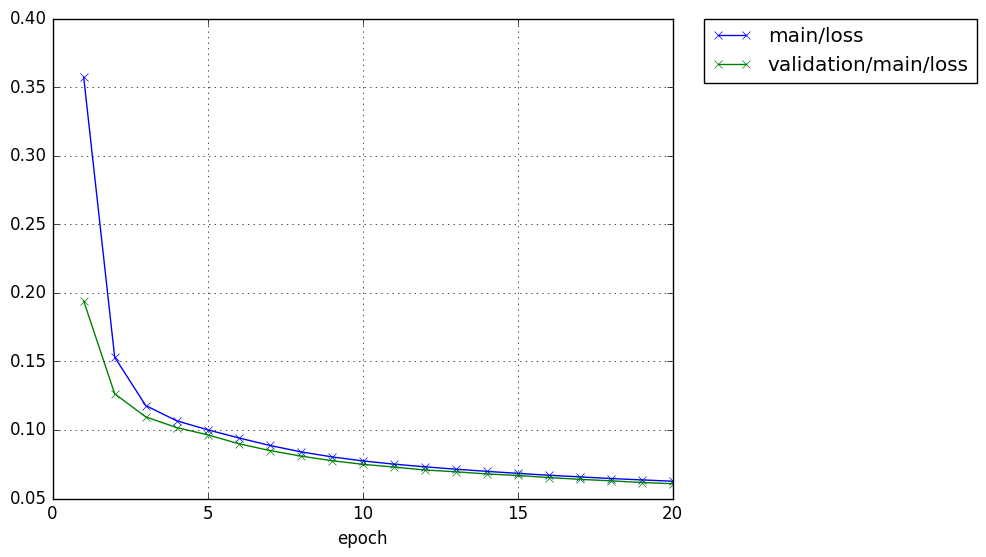
ロスの推移
Total
Detail
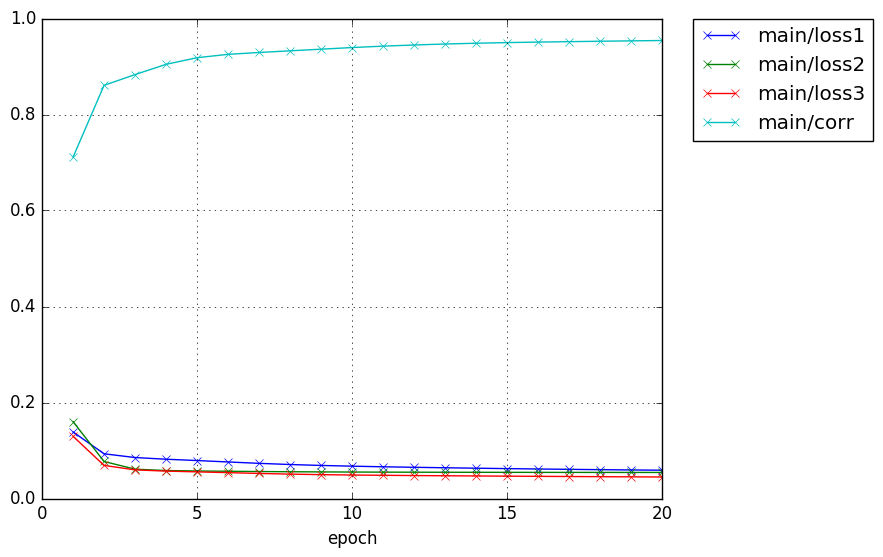
ちゃんと隠れ層で相関が高くなるように学習が進んでおります!
考察
ラベル情報からだけでも復元できるようです!
いずれにせよ,chainer,やはりTheanoよりだいぶ簡単に書けてログも出力できて便利ですね^^