この記事はTreasure Data Advent Calendar 9日目の記事です。
今年の10月頃からTreasure DataのBackend Teamで働いています佐々木といいます。
今回はTreasure Dataで動くHadoopの、中からみたすごいところをなるべく私自身の初々しさが残るうちに書いておきたいと思い筆をとりました。
Treasure DataのHadoop
まずはじめにTreasure Dataで動いているHadoopとその周りのアーキテクチャを簡単に紹介したいと思います。

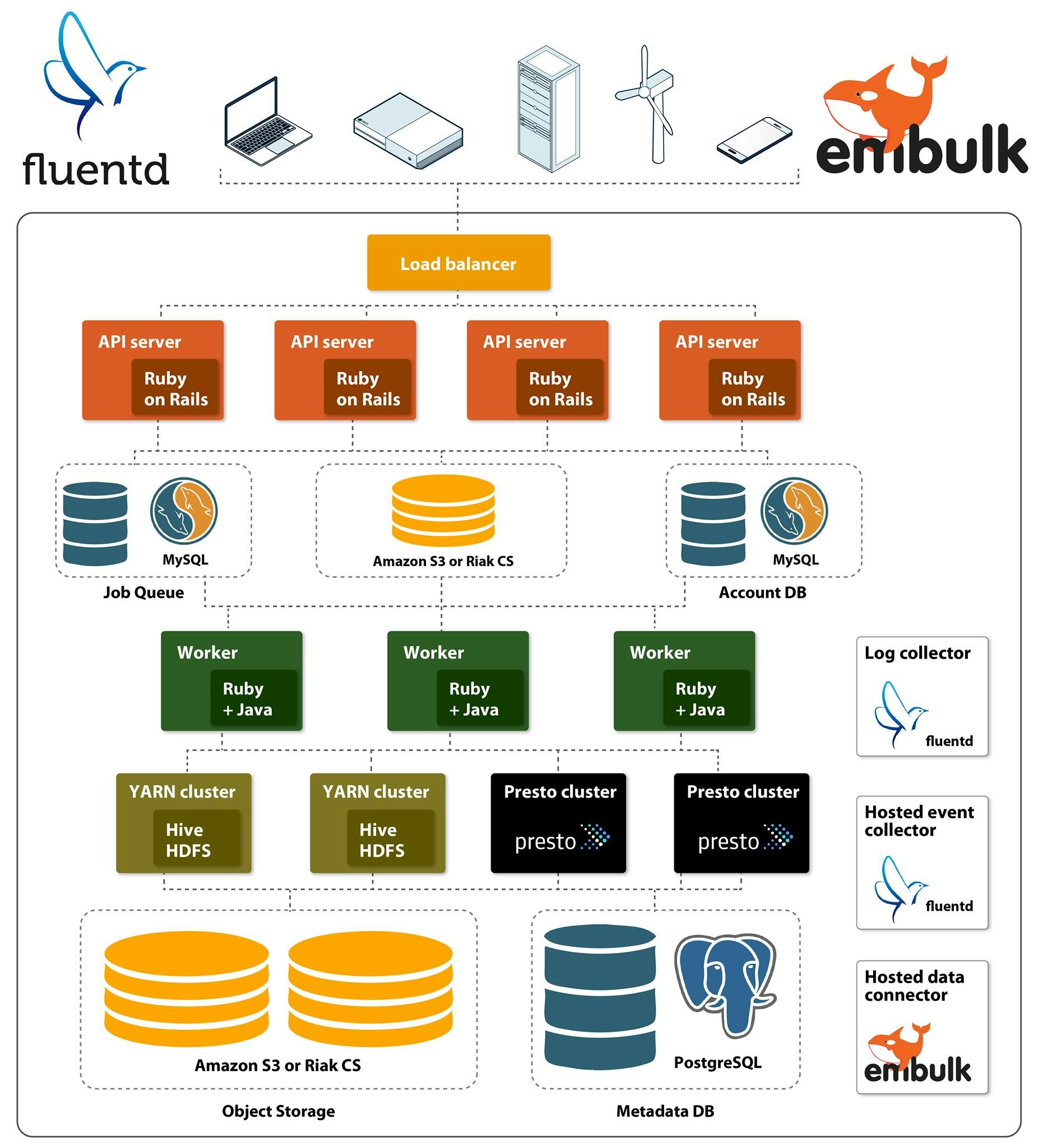
Treasure Data, Architecture Overviewより
Treasure Dataはフルマネージドなデータ処理、管理のためのCloudサービスです。Treasure Dataでは上記のように大きく分けて3つの役割を担うコンポーネントたちが存在します。
- データの取得(Acquire)
- データの保持(Store)
- データの分析(Analyze)
この中でHadoopが担っている部分は主に下の2つ、StoreとAnalyzeの部分です。上の図で言うとモクモクと雲のようになっている部分とそこから右に伸びているパイプあたりが該当します。現在Treasure DataのHadoopには合計で
- 14兆レコード
- 1.2PB
のデータが合計で入っています。またこれらに対してHiveクエリだけで約3万超のクエリが毎日発行されています。これらのデータを安定的に管理し、毎日の分析を容易にするためにどのような技術が使われているかを紹介します。
雲の上のHadoop
Treasure DataもCloudサービスですが、そのTreasure Data自体もAWSやIDCFのようなCloudサービスの上で稼働しています。Treasure Dataを導入していただくことでお客様にとってすぐに使えるフルマネージドなデータ分析環境が手に入るわけですが、同じように私達からみるとHadoopクラスタがほしいとなったらすぐに使えるHadoopクラスタが一瞬で立ち上げることができます。それもこれもAWSやIDCF Cloudのようなもっとインフラ寄りのCloudサービスがあるお陰です。
リソースが不足したり、何か障害が起きた場合でも何十台、何百台といったHadoopクラスタの追加、再構築がすぐにできます。データ処理に使うサーバはアドホックなスペックが必要とされたり、その台数も多くなることが考えられます。そうはいってもそれを取り巻く技術はものすごいスピードで進化しており、枯れる勢いを見せていません。なかなか長期に渡っての予測を踏まえたマシン調達、サーバ選定は難しいものがあります。こういった現状を鑑みるとBig Dataのための技術というのはクラウドサービスとかなりシナジーを効かせることのできる分野な気がします。
ChefとBlue-Green Deployment
Hadoopクラスタを幾つか管理していると、何か不具合があったり障害が発生したりすることがあります。何か設定値を変更する、パッチをあてるということもあるでしょう。Treasure DataのHadoopはBlue-Green Deploymentができるように設計されていて、お客様からのジョブを止めることなくクラスタの削除、構築、切り替えができるようになっています。上記のCloudインフラの利用もあり、Treasure Dataでは「あ、ちょっとクラスタ作っておいて」、「このクラスタそろそろつぶしますか」などといった会話が普通に行われます。HadoopクラスタはTreasure Dataではかけがいのない存在ではなくいつでも取り換え可能な消耗品です。
突撃!隣の開発環境 パート12【Treasure Data編】 in シリコンバレーより
またTreasure DataのインフラはHosted Chefを使っています。そのためクラスタの構築もdata bagsの更新などちょこちょこやって少し待つとできます。クラスタが立ち上がったらQueueの役割も兼ねたWorkerからの向き先を変更するだけでお客様のジョブを止めることなく新しいクラスタでジョブを動かすことができます。
Workerの話がでてきたのでもうひとつ説明をしますと、Treasure Dataにはジョブを受け付けるWorkerとジョブが利用するデータを保持するPlazmaと呼ばれる独自のストレージが別コンポーネントとしてありますが、これらは完全にHadoopクラスタからわけられています。そのためデータの保持、ジョブのキューイングなどをHadoop側からは全く考慮することなくHadoopクラスタを消したり、作ったりすることができます。クラスタのshutdownに伴うデータの欠損、損失は非常に神経の使う作業になりがちなのでそこを気にする必要がないというのは非常に心と体に優しい毎日を送ることにつながります。
ビッグデータのコピペ
お客様の問い合わせや、クエリの動作確認などでちょっとしたデータあるいは大規模なデータが必要になるということはよくあります。こういう時にデータを簡単に作ったり動かしたりできる機能がTreasure Data自体にあります。もちろんこれらはお客様のための機能として作られたものですが、中の開発者が試験や開発に使うときにも大変便利です。
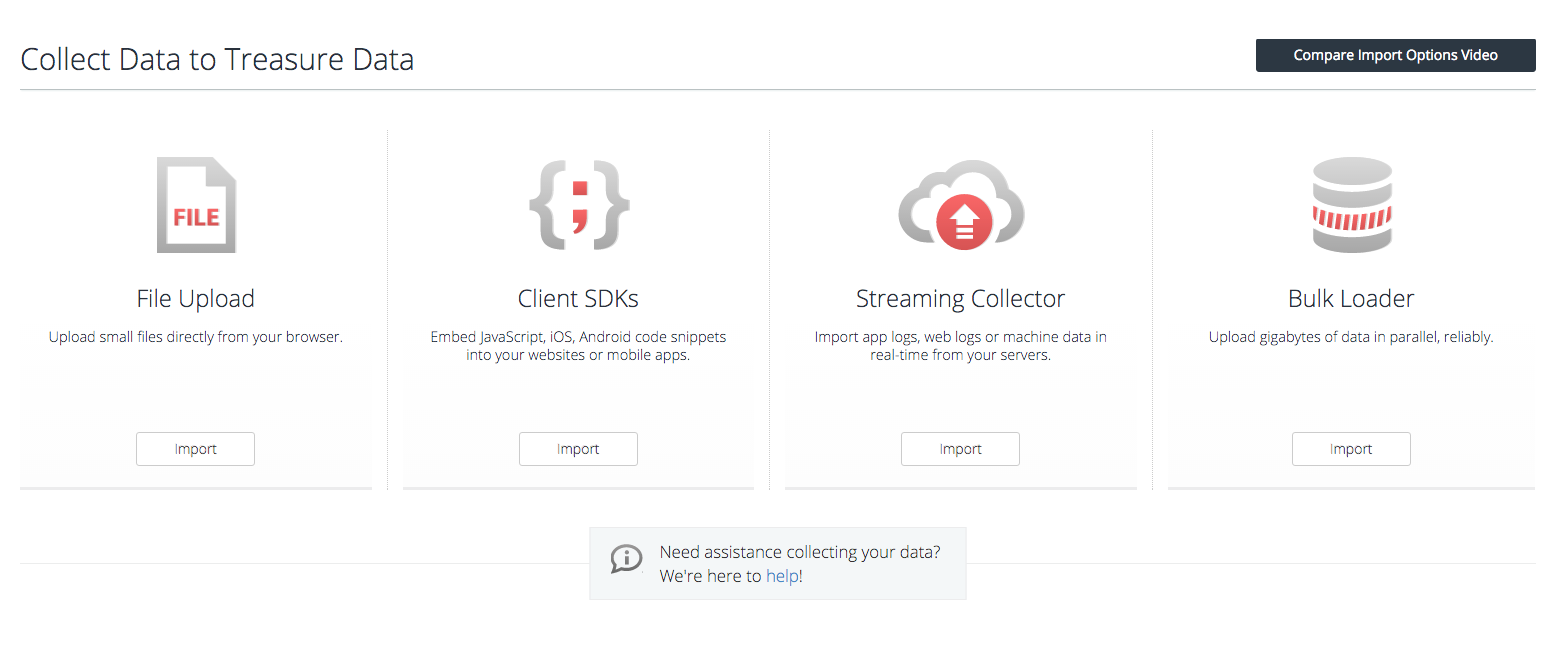
TSV, CSV, JSONなどのフォーマットのファイルがスキーマ設計なしにアップロードできますので手元でちょこちょこ作ったデータをアップロードしたり、dev環境にあったデータをstaging環境に持ってくるなどが簡単にできます。
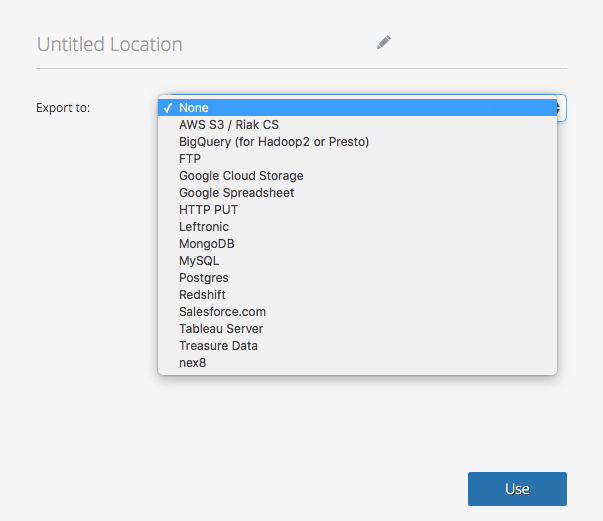
またジョブの結果を他のツール、サービスにExportするResult Exportの機能もあるので、結果に不整合がないか手元で調べたり、他のツールで可視化させたりしたい場合にとても便利です。現在では上の図に記載されているサービスに対してジョブの結果をexportすることができます。このように大きなデータをあっちに持って行ったり、こっちに持ってきたりすることが非常に簡単にできるのもすごいところのひとつです。
PTD?
こちらの投稿にもありますように現在Treasure DataではPatch set of Treasure Dataというものを開発しています。PTDを使って未来に渡っての開発を加速させるような野心的な取り組みが盛り沢山になる予定ですので来年のAdvent Calendarでまた紹介できればと思います。