DRY原則…
Don't Repeat Yourselfの略で、「繰り返しを避けること」という意味です。
初回出典はどこなのかわかりませんが、私は「達人プログラマー」で読んだのが最初でした。
信頼性の高いソフトウェアを開発して、開発そのものを簡単に理解したりメンテナンスできるようにする唯一の方法は、DRY原則に従うことです。
すべての知識はシステム内において、単一、かつ明確な、そして信頼できる表現になっていなければならない。
DRY原則を破るということは、同じ知識を2箇所以上に記述することです。この場合、片方を変更するのであれば、もう片方も変更しなければならないのです。
・・・中略・・・
我々はこれが達人プログラマーの道具箱の中にある道具のうちで最も重要なものの一つであると考えています。達人プログラマー アンドリュー・ハント/デビッド・トーマス-
DRY原則は、単なるソースコード上のこと(メソッドやクラス債務の重複)に言及している訳ではないと感じます。
プログラマーの生産性を劇的に高めてくれる原則でもあります。
様々な文献で見かけますが、優秀なプログラマは、一般のプログラマと20倍以上の生産性の違いがあると言われています。
タイピングが20倍速いとか(遅いより速いほうがいいですが)
マウスを全く使わないとか(もちろん、様々なショートカットを駆使したほうがカッコイイし仕事も速いですが)
もちろんそれらも要因の一つにはなると思いますが、「劇的」と言うとちょっと違うかな、と思います。
DRY原則視点で考えると、劇的な生産性向上のテクニカルなコツは、**「自動化」**にありそうです。
DRY原則を守ると恩恵を受けられる領域が私が考えるに6つほどあると考えます。
- コード
- コードとコメント
- コードとドキュメント(設計書)
- 自動生成
- 作業(タスク)の自動化
- アプリケーション・ライフサイクル全般
それぞれ見ていきます。
コード
コードの重複は可能な限り排除したいですよね。
Joel on Softwareにこんな記事があります。
「君のプログラミング言語で、これできる?」(本では、More Joel on Softwareに記載されています。)
この例を引用させていただきます。
ある日、自分のコードを眺めていて、ほとんど同じに見える2つの大きなコードブロックがあるのに気付く。
実際、一方が"スパゲッティ"、他方が"チョコレートムース"について言及しているところを別にすれば、どちらもまったく同じだ。
//簡単な例:
alert("スパゲッティが食べたい!");
alert("チョコレートムースが食べたい!");
この例ではたまたまJavaScriptを使っているが、この後の話は別にJavaScriptを知らなくとも理解できるはずだ。
同じコードが繰り返し現れるのは、もちろん良くないことだ。だから関数を書くことにしよう:
function SwedishChef( food )
{
alert(food + "が食べたい!");
}SwedishChef("スパゲッティ");
SwedishChef("チョコレートムース");確かにこれは単純な例だが、もっと中身のある場合も想像できるだろう。
多くの点でこちらのコードの方が良く、そういった理由については何百万回も聞いていることだろう。
保守性、可読性、抽象性 = 良い!
基本的には重複コードはなるべく無くそうというスタンスは必要かと思います。
ただ、やりすぎると保守しにくいコードになることもあるかと思いますので、その辺りは加減が重要です。共通化故にメタメタなプログラミングをしちゃうとかえってわかりにくくなることも時々あります。
個々人の心がけも重要なのですが、アプリケーションの規模が拡大し、開発人員が増加するにつれて、DRY原則を破られる可能性は高くなってきます。
1人で開発している場合は、自分の作ったメソッドを覚えている可能性が高いです。数ヶ月経つとわかりませんが・・・。
人数が増えてくると、同じようなメソッドがあちこちに増えてきます。
よく言われる手法が詳細設計書を作ったり、APIドキュメントを作ったりすることですが、これらは実はDRY原則に反します。
APIドキュメントは最たる例で、メソッドヘッダに必ずコメントをつけることを強制します。書くことがないと、コメントとメソッド名がイコールになります。ここでDRY原則に反します。
そこで重要なのはメソッドやクラスが「探しやすい事」。そして「探す癖をつける」ことだと思います。
「探しやすさ」
命名規則に方針を持たせて周知・共有する
システム全体で統一感があれば尚更良いと思いますが、1システムで多くの言語を利用しているケース、利用言語の特性もありますので、そう簡単には決められません。リーダシップの見せ所かも知れません。
- メソッド
- クラス
- パターン
- 名前空間
- モジュール(Project)
- レイヤー構成
規模が大きい開発の場合、あらかじめすべての命名規則は作成できないです。発見の都度熟考する必要があります。
DRY原則を破らない最善の方法は、「アプリケーションに出てくる全てのNaming(名前付け)に気を使う」だったりします。
Naming(名前付け)に関しては、以前記事を書きました。
http://qiita.com/Koki-Shimizu/items/f3d3e824f98d182d4100
書いたコードは必ず他の人に見てもらう
方針を立てて周知されても、やはり「人」がやることですので間違いは絶対に起きます。起きる前提のほうがいいと思います。
よって、書いたコードは必ず他の人に見てもらうと間違う確率が減ります。
大文字小文字のタイプミス、スペルミスにも注意を払う必要がありますが、自動でのチェックは難しいので、みんなの目を介する必要があります。
Googleでは、必ずレビューを行うそうです。
グーグルはコードレビューを開発プロセスの中心に置いている。コードを書くことよりもレビューすることのほうがずっと大切なこととして大々的に取り扱われる。
-テストから見えてくるグーグルのソフトウェア開発- ジェームズ・A・ウィテカー/ジェーソン・アーボン/ジェフ・キャロー より
またGoogleでは"可読性の良い/悪いコミッター"という概念もあるようで、リポジトリにコミットする人に評価をつけており、この資格証明は、コードベース全体が1人のデベロッパーによって書かれたかのような感じにするために役立つそうです。
IDEの機能を利用して、これも周知・共有する
IDEの機能を使うと目的のものが探しやすいです。
クラスやメソッド、ファイルを当該ソリューションの中から探すショートカット
- Visual Studioであれば、Ctrl + 「,」
- Eclipseであれば、Ctrl + Shift + 「R」
便利な方法はみんなで共有すると良いですね。
「探す癖をつける」
啓蒙が必要かと思います。
啓蒙の手段としては、メールだったりWikiだったり朝ミーティングだったり、様々なのですが、要は「コミュニケーションの時間を増やす」ですね。啓蒙するリーダシップも大切です。
チームやプロジェクト、組織メンバとのコミュニケーションを密し、方針を共にすれば大幅にずれることはありません。
まさに
”ソースコードはコミュニケーションの結晶”
です。
コードとコメント
ときどき以下の様なコメントを見かけます。
private void ShowMessageBox( bool IsDisplay )
{
// もしIsDisplayがtrueなら
if( IsDisplay )
{
// スパゲッティが食べたいというメッセージボックスを表示する。
alert("スパゲッティが食べたい!");
}
}
コードを見れば、自明なことをわざわざコメントに書いています。
これは不要なコメントです。
表示文字列が"スパゲッティ"じゃなくなったら、コードもコメントも修正する必要があります。
達人プログラマーでは以下のように記載されています。
###コード中のドキュメント
「良いコードには多くのコメントがある」とコード中にコメントを記述することの重要性をプログラマーは新人の頃から教えこまれます。
しかし残念なことに「見苦しいコードには多くのコメントが必要となる」という、コメントが必要となる理由については教えられていないのです。
DRY原則に従えば、低水準の知識はコードに任せて、高水準な解説をコメントで記述ということになります。
-達人プログラマー アンドリュー・ハント/デビッド・トーマス-
リーダブルコードでも以下のように記載されています。わかりやすいです。
###コードの意図を書く
コメントというのはコードを書いているときに考えていたことを読み手に伝えるためのものだ。でも、コードの動作をそのまま書いているだけで、何も情報を追加していないコメントが多い。
>void DisplayProducts( list<Product> products)
>{
> products.sort(CompareProductByPrice);
>
> // listを逆順にイテレートする
> for(list<Product>::reverse_iterator it = products.rbegin(); it != products.rend(); ++it )
> {
> DisplayPrice(it->price);
> }
>}
これだと直下のコードをそのまま説明しているだけだ。もっといいコメントを考えてみよう。
> // 値段の高い順に表示する
> for(list<Product>::reverse_iterator it = products.rbegin(); it != products.rend(); ++it )
>
-リーダブルコード Dustin Boswell/Trevor Foucher-
高水準な解説をコメントしていますね。
このようにコメントには、コードで表現しきれないこと(意図や理由)を書くと良いと思います。
コードとドキュメント(いわゆる設計書)
大規模・中規模開発においては、アーキテクチャ方針に関しては、ドキュメントとして残すべきと感じます。
特にそのアーキテクチャをデザインした理由はどこかに残す必要があります。
開発規模が大きく・長く・複雑になるにつれて、ステークホルダーが増えるので、すべてを口頭でというのは無理があります。
ただし、必要最低限のドキュメントを用意することを念頭に置きます。
例えば、中・大規模システムでは、以下の様な観点はコードを書く前に考えたほうがいいかも知れません。
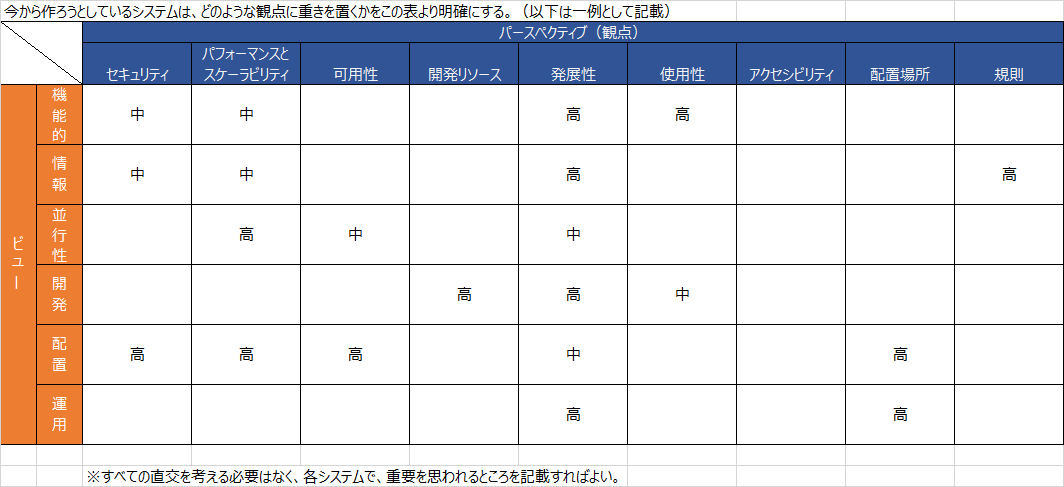
ビューポイントカタログ
| ビューポイント | 定義 |
|---|---|
| 機能的 | システムの機能要素、その債務、インターフェースおよび主な相互作用を記述する。機能的ビューは、ほとんどのアーキテクチャデザインの土台となり、たいていはステークホルダが読もうとする最初の記述である。情報構造、並行性構造、配置構造など他のシステム構造の形を決める。また、変更能力やセキュリティ能力、実行時パフォーマンスなどシステムの品質特性にも重大な影響を与える。 |
| 情報 | アーキテクチャが情報を格納、操作、管理および配布する方法を記述する。事実上、どのコンピュータシステムでも究極の目的は、何らかの形で情報を操作することであり、このビューポイントは、静的データ構造と情報の流れに関する完全だが高レベルのビューを展開する。この分析の目的は、内容や構造、所有権、待ち時間、参照、データ移動にまつわる大きな疑問に答えることである。 |
| 並行性 | システムの並行性構造を記述し、機能要素を並行性単位へマップして、並行して実行可能なシステム部分と、並行実行を調整および制御する方法を明白に識別する。これには、システムが使用するプロセスおよびスレッドの構造と、それらの働きの調整に使われるプロセス間通信メカニズムを示すモデルの作成が伴う。 |
| 開発 | ソフトウェア開発プロセスをサポートするアーキテクチャを記述する。開発ビューは、システムの構築、テスト、保守、機能拡張に携わるステークホルダが関心を持つアーキテクチャ側面を述べる。 |
| 配置 | 実行時環境でのシステムの依存性を把握することを含め、システムが配置される環境を記述する。このビューでとらえるのは、システムが必要とするハードウェア環境(主に、処理ノード、ネットワーク相互接続、必要なディスク記憶装置設備)、各要素の技術的環境要求、ソフトウェア要素のそれを実行する実行時環境へのマッピングである。 |
| 運用 | 本番環境での実行時におけるシステムの運用、管理、サポート方法を記述する。ごく単純なシステムを除き、システムを導入、管理、運用することは、設計時に検討して計画しなければならない重要な課題である。運用ビューポイントの狙いは、システムのステークホルダが持つ運用上の関心事に対応する、システム全体としての戦略を居つけ、それに対処する解決策を識別することである。 |
| パースペクティブ | 望まれる品質 |
|---|---|
| アクセシビリティ | 障害のある人々によって使用されるシステムの能力 |
| 可用性とレジリエンス | 必要な時に応じて全体または部分的に運用可能であり、システムの可用性に影響のおそれがある障害を効果的に処理するシステムの能力 |
| 開発リソース | 人、物、金、そして時間に関する既知の制約内で、設計、構築、配置、運用されるシステムの能力 |
| 発展性 | 配置後にあらゆるシステムが経験する避けようのない変更にも柔軟であり、そういう柔軟性を提供するコストに釣り合っているシステムの能力 |
| 国際化 | 特定の言語や国家または文化集団から独立しているシステムの能力 |
| 配置場所 | 構成要素の絶対位置とその要素間の距離によってもたらされる問題を克服するシステムの能力 |
| パフォーマンスとスケーラビリティ | 指定されたパフォーマンス概要の範囲で予測したとおりに稼働して、増大する処理量をさばくシステムの能力 |
| 規則 | 国内法と国際法、準法律的規則、会社方針、その他の規則や基準を遵守するシステムの能力 |
| セキュリティ | 誰かどんな操作をどのリソースに対して実行することができるかを確実に制御・監視・監査して、セキュリティメカニズムの障害を検出・回復するシステムの能力 |
| 使用性 | システムと会話する人々が効果的に仕事をすることができる容易さ |
上記のビューポイントと、パースペクティブ・カタログを直交させて、開発するシステムがどの観点に重点を置くのか明確にします。
その上で、各観点に関するドキュメントを記載します。
上記のような情報はコード上で表現することがなかなか難しいので、ドキュメントが必要になります。
詳細はコードに任せるつもりで、あとは実際にコードを書いてみて、コードで表現できない、しづらい部分に関しては、ドキュメントをアペンドしていくほうが効率が良いと感じます。
一律でクラス図やシーケンス図を書かなければならないとか、そうゆうのはNGかと思います。(テンプレート・ゾンビ)
ここがソフトウェア開発の面白くも難しいところで、模範解答がないと感じます。適材適所になります。
2014年の日本Microsoftのイベントde:codeでは、以下の様な触れ込みがされていました。
Source Code as Documents
ドキュメントとしてのソースコード。コードはすなわちドキュメントであると。
確かに、読みやすいコード・一貫性のとれたコードは、どのようなドキュメントにも勝るのかも知れません。
自動生成(コード・ジェネレータ)
優秀なプログラマと一般のプログラマの20倍以上の生産性の開きは、この自動生成をうまく作れるか、使えるかに起因する部分が大きいと考えます。
例えば、Ruby on Railsの Active Recordは、Modelを作成することによってDBスキーマを自動生成してくれます。JavaのO/RマッパーのHibernateもActive Recordほどお気軽ではないですが、同じようなことができます。
ASP.NET MVCにはEntity Frameworkという仕組みがあります。これもActive Recordと同様、Modelクラス(POCOエンティティ)を定義することで、DBスキーマを用意してくれます。(Code Firstと呼ばれます。)
これらは生産性という意味では、あるとないとでは劇的に違います。
達人プログラマーでは、以下の様に紹介されています。
###コードを生成するコードを作成すること
コード・ジェネレーターには、2種類あります。
消極的なコード・ジェネレーターと積極的なコード・ジェネレーターです。消極的コード・ジェネレーターは、タイピング量を削減するものです。これは基本的にパラメータ化されたテンプレートであり、入力の組から指定通りの出力を生成するものです。一旦結果が生成されれば、それはプロジェクトにおける一人前のソース・ファイルとなり、編集、コンパイルされ、その他のファイルと同様ソース管理の対象にもなります。そして、その出自は忘れされてしまうのです。
消極的なコード・ジェネレーター
消極的なコード・ジェネレーターの例としては、以下の様なものがあります。
新規ソース・ファイルの生成
- テンプレート
- ソースコード管理指示
- コピーライト文
- プロジェクトにおける各新規ファイルの標準コメントブロック
プログラミング言語の一括変換
・完璧を求めなくて良い。精度が甘くても良い。消極的なコード・ジェネレーターの目的はタイピング量の削減なので。自動生成と手作業を組み合わせて目的が素早く達成できれば良い。
・検索テーブルやその他のリソースの生成
・初期のグラフィックスシステムでは、三角関数を使用する代わりに前もって計算したサイン値やコサイン値のテーブルを用意。
積極的なコード・ジェネレーター
積極的なコード・ジェネレーターは、単に利便性を追求したものですが、DRY原則を実践する際に必要となるものです。積極的なコード・ジェネレーターを使うことにより、元となる唯一の知識を読み込み、それをアプリケーションが必要とするさまざまな形式に変換することができるようになるのです。変換された形式は使い捨てであり、必要に応じてコード・ジェネレーターによって再生成できるため、二重化とは「なりません」(それが積極的と呼ばれる所以です)
2つの異なった環境をまとめたい場合には、常に積極的なコード・ジェネレーターの使用を考えるべきでしょう。
あなたがデータベース・アプリケーションの開発をしているのであれば、あなたはすでに2つの環境 --すなわち、データベース環境とプログラミング言語環境に直面しているのです。スキーマを元にして、特定のデータベース・テーブルのレイアウトと同じ低レベル構造の定義を行う必要が出てきたと考えてください。こういったものを直接手作業でコーディングすることも可能ですが、これではDRY原則に違反します。
・・・中略・・・
こういったことを無くすには積極的なコード・ジェネレーターを使用することです。
Active RecordやEntity Frameworkはまさに達人プログラマーを実践していますね。
コードジェネレーターを自作した場合、簡単な例ですが、以下の様なイメージです。
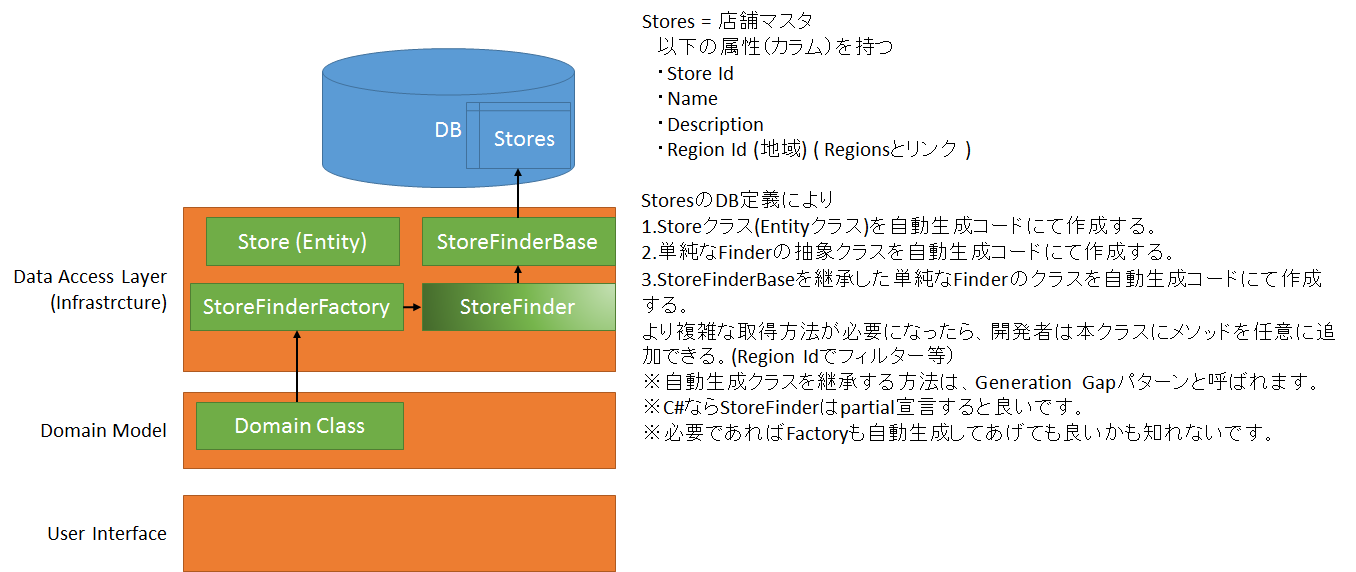
この場合、
積極的なコード・ジェネレーターにて生成されたコードは、
Store/StoreFinderBase/StoreFinderFactory
となり、消極的なコード・ジェネレーターにて生成されたコードは、
StoreFinder
になります。
他にも積極的コード・ジェネレーターにて以下のようなものを作ることがあります。
- ラッパークラス・メソッド(AOPが使えない場合に、あるAPIを呼び出した場合の一律ロギング等)
- 腐敗防止層作成(ラッパーに近いが・・・)
- ディープコピー用処理
適切に正規化されたリレーショナル・データベース・スキーマは、DRY原則と相性が良いと感じます。
「One Fact in One Place」であり、上記のようにコード・ジェネレーターをフル活用できるからです。(そこかしこに真実(と言われるもの)がある場合どれを信用していいかわかりません。)
この他にも、以下の様なテクニックを私はよく使います。
- テーブル定義(メタ・データ)やテーブル内のデータからSQLにてコードを作成する(消極)
- テーブル定義(メタ・データ)やテーブル内のデータからSQLにてテスト・コードを作成する(消極)
- テーブル定義(メタ・データ)やテーブル内のデータからSQLにてSQLを作成する(消極)
- .NET限定ですが・・・あるDLLに情報を詰め込んで、(それをメタ・データやデータが詰まったモノにみせかけて)コードを生成する(T4を利用すると便利)(積極)
”SQLを制するものはアプリを制す” なんて言われていた時代もあったようです。
リレーショナル・データベースの出番は少し減ったかもしれませんが、SQLはまだまだ使いそうです。アプリ実行時というより、開発時の手段としてより多く利用しているような気がします。
作業(タスク)の自動化
DRY原則は単にコードについてのみ言及しているわけではありません。
私たちが行う作業(タスク)については「繰り返しを避けよ」と言っています。
自動化できる対象はたくさんあるかと思いますが、例えば以下の様なタスクです。
- 開発マシンの自動起動(朝決まった時間に起動させておくと、仕事始めがスムーズ)(マシンスペックにも依存(SSDなら不要かも))
- プロジェクトのコンパイル
- 開発環境の構築(RubyではBunlderやGemでしょうか。.NETだとNuget。Eclipseはこの手のインストールは以前から得意でした。)
- 上述のとおり、コードの生成。主に積極的なコード・ジェネレーターの場合です。軽量な開発プロセスのルーチンに組み込むと良いと思います。
- 回帰テスト JUnit/NUnitなどの自動UTはもはや当たり前のようになりました。GoogleではUIテストも自動化していると聞きました。(テストから見えてくるグーグルのソフトウェア開発(クオリティボットの実験より))
- ビルドの自動化(コードチェックアウトからビルド、成果物配置まで)中央サーバでのビルドならJenkins、個人の開発マシンなら簡単なバッチを作れば自動化できます。
アプリケーション・ライフサイクル全般
よくアジャイル手法と対比されるV字モデルというプロセスがあります。
開発の段階を各工程とみなして、各工程が終わらないと次の工程に移ることは原則できません。
顧客の要求が固定化されており、その要求がすべて引き出せている場合にはこの手法は有効かも知れませんが、現実的にそのようなケースは非常に少ないと考えます。要求は絶えず変化します。
それはちゃんと要求を固定化できない顧客が悪い訳ではなく、世の中の流れからしてそうせざるを得ないからです。(顧客からみた)外部要因も目まぐるしく変化します。
誤解を恐れずに簡単に言えば、V字モデルを数週間レベルにまで短縮させ、さらにそれを繰り返し行うことでアプリケーションの精度を高めるという手法がアジャイルになります。
数週間レベルで1サイクルを回すためには、無駄なものは省く必要があります。そこで「顧客に真の価値をもたらすものは何か」という考えのもと、不要なものはバサバサと切り落とします。
現在の仕組みだと、ソースコードがないとアプリケーションが出来ないので、一番重要なものはソースコードになります。ソースコードを中心に考える必要があります。
アプリケーションを迅速に完成させる手段は何か?
と考えると、すなわちソースコードを迅速に完成させ、テストを迅速に完成・繰り返し可能にさせることになります。
DRY原則はここにも適用するべきかと考えます。
もう一度、DRY原則を記載します。
信頼性の高いソフトウェアを開発して、開発そのものを簡単に理解したりメンテナンスできるようにする唯一の方法は、DRY原則に従うことです。
すべての知識はシステム内において、単一、かつ明確な、そして信頼できる表現になっていなければならない。
「システム内」という言葉が出てきましたが、「開発プロセス全体も含む」とも捉えられます。アプリケーションのライフサイクル全般にわたって、DRYを適用するということになります。
極論をしてしまうと以下の様な流れになります。(全自動は不可能だとは思いますが・・・)
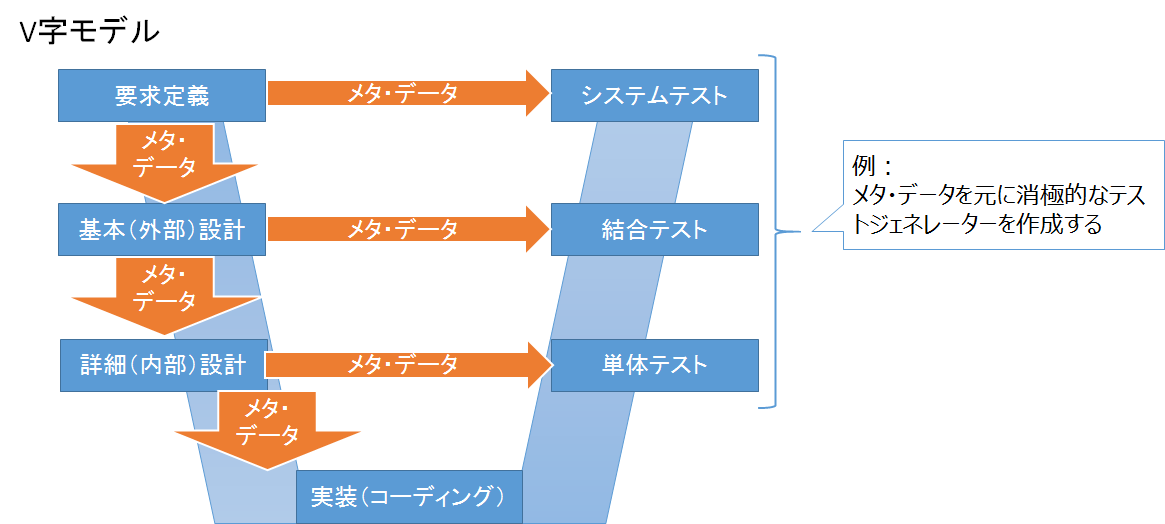
メタ・データのフォーマットとしては、プレイン・テキスト(XMLやCSV等)またはシステムで利用するRDBを用いると、後工程での加工が簡単になります。
実はこれも、達人プログラマーに記載されています。
###プレイン・テキストの威力
知識を永続的に格納するためのフォーマットで最も適しているものがプレイン・テキストなのです。プレイン・テキストを使えば手作業、自動的な作業を問わず、事実上すべてのツールを使って思い通りに知識を操作することができるようになるのです。
…中略…
テキストの威力
- 透明性が保証される
- さまざまな活用ができる
- テストが容易になる
- diffをとったりpatchを当てやすくなる
大切なのは、後工程でも利用可能なメタ・データやデータを作成するというところです。そして、それを単一、かつ明確な、そして信頼できる表現で記載し、参照できるようにしておきます。
(プレイン・テキストではないですが、MDD(Model-Driven-Development)という手法も存在します。これはクラス図やシーケンス図やステートチャート図をUMLなどの決められた方式で書いたら、その通りのコードが出力されるという手法です。使い方次第ではありますが、個人的には、無駄な図ばっかり増え、メンテンナンスが非常に大変な印象があるのでオススメしません。消極的なコード・ジェネレータとして割り切って使うなら良いとは思います)
ただ、そうなると、結局最終的なプログラミング時に利用できる形式とは一体何かを前もって考える必要が出てきます。
要求定義を行う人がプログラマーではないとなると、かなりややこしい話になります。
やはり少人数のチームでアジャイル手法を用いたほうが断然効率的のような気がします。
結局は、目的を達成するためにどの手法を選ぶか、選んだ中での最適解(人材、環境、文化含めて)は何か、という問題になってしまうので非常に難しいですね。(グダグダですみません・・・)
この考え方は、タイトルにもある「コンカレント・エンジニアリング」に通じるものがあります。
開発工程を全並列化し、開発期間の短縮するためのプロセスです。
コンカレント・エンジニアリングはおそらく製造業向けの手法だと思いますが、ところどころソフトウェア開発にも適用できそうな記述がありましたので、ご紹介します。
Appleもコンカレントエンジニアリングを採用していると言われています。
(「ジョナサン・アイブ」に書かれてました。)
以前書きました。
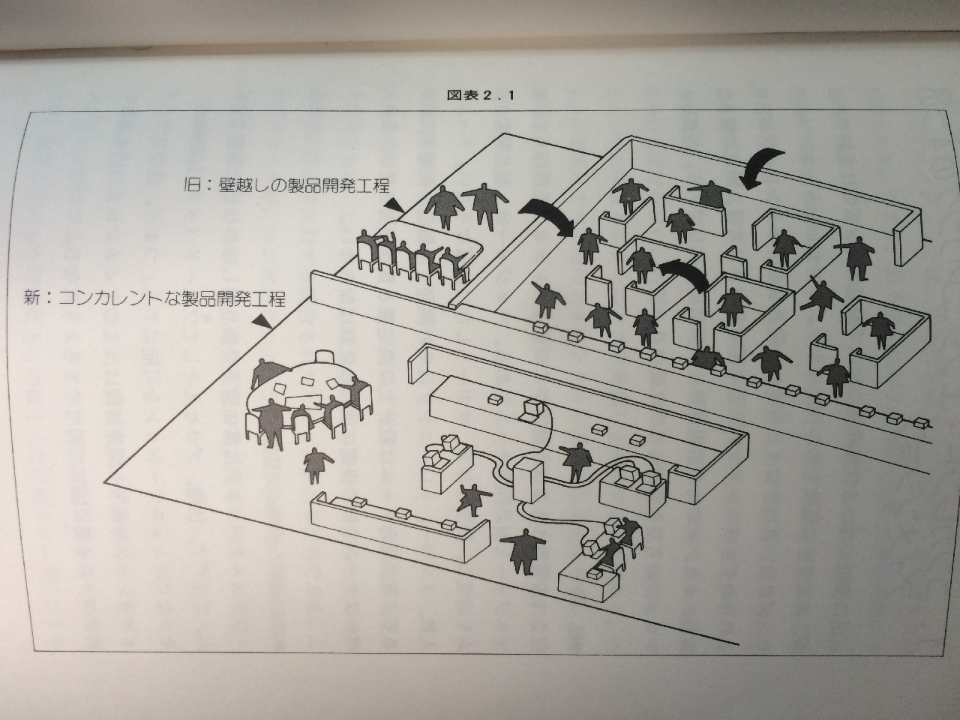
コンカレントエンジニアリングを一枚の絵で表しているのがこちら。わかるようなわからないような(笑
一番重要なのは、「壁」が取り払われていることですね。「組織の壁」。
コンカレントエンジニアリング D.E.カーター/B.S.ベーカー より
アジャイルでは、とにかく人を重視します。
コンカレント・エンジニアリングも同じです。
コンカレント・エンジニアリングでは、以下の5つの要因(5つのT(Technology/Tool/Task/Talent/Time)をいかにして効率的にしていくかを出発点としています。
##テクノロジ(Technology)
現在利用可能なテクノロジをどの程度活用しているか?
市場におけるテクノロジー・リーダーであるか?
製品のインターフェースは業界標準に準拠しているか?
今後使用し開発していくテクノロジの方向を示すための製品に対する長期的な見通しを持っているか?
製品を業界のリーダーとするテクノロジを開発中か?
ツール(Tool)
- 最も使いやすいツールとは?
- 要求される自動化、互換性、統合のレベルは?
- 新しいツールによるインパクトをどう管理しているか?
- ツールのインターフェース標準化のために、他の業界リーダーや団体に積極的に働きかけているか?
- ツールが要求するデータは何で、そのデータの管理のしかたはどうか?
タスク(Task)
- タスクが特に複雑化している時のタスクの定義、分割、効果的な管理の仕方は?
- タスクを実行するプロセスは、品質、生産性のレベルを達成するために継続的に改善されているか?
- タスクの自動化は有効か?
人材(Talent)
- 有能な人材を効果的に用いているか?
- 長期間にわたり有能な人材を確保できているか?
- 継続的にトレーニング、社内教育を行い、やりがいのある仕事を与えているか?
- 経営者は従業員を満足させているか?彼らに権限を委譲しているか?
- 経営者は企業のビジョンをよく理解し、従業員に伝えているか?
時間(Time)
- いかに市場投入時間を短縮するか?
- いかにすばやく製品の改良に着手するか?
- 製品開発サイクル・タイムの改善度の評価法は?
重要なのは、これら5つの力はただ並列に存在するだけでなく、製品開発環境の中で縦横にしっかりと統合されているということである。
-コンカレントエンジニアリング- D.E.カーター/B.S.ベーカー より
アジャイルっぽい感じがすごくしますね。
コンカレント・エンジニアリングの本は、1990年に出版されていますので、もしかしたらアジャイル宣言の元になったのかも知れません。
効率化の追求の手段として、「自動化」があると説いています。
各工程の自動化はツールがやってくれることが多いですが(例えばコンパイラ)、工程全体の自動化にまでは及んでいないため、これを「オートメーションの孤島」と呼んでいます。これはV字モデルのソフトウェア開発プロセスを見事に表現していると思います。
各工程が孤立した島のようで、結局「紙」媒体での伝達しか手段がないと書かれています。各工程の成果物が、「読み物」になっているからです。通常、MS-WordやExcelですね。
電子化はされていますが、「使えないインターフェース」ということです。マクロを駆使する方法もありますが、保守効率が悪いですよね。
読み物は最小限にし後工程で利用できる「データ」を受け渡したほうが全体の効率は上がると考えます。
まとめ
書いていて思ったのですが、本記事はちょっとした問題提起になっているのかも知れません。
アプリケーションのライフサイクル全般にわたって、メタ・データやデータを介して、各工程を半自動化できないか、という問いです。
もちろん、模範解答はありませんが、各現場の効率化の何かのキッカケになれば幸いです。