概要
普段Ruby on RailsでWebアプリの開発をやっているWebエンジニアが機械学習に挑戦した話です。
普通のWebエンジニアがこういった具合で機械学習を学ぶと、このくらいの期間でこのくらいのことができるようになる。
みたいなひとつの例として参考になるかもしれません。
とにかく機械学習楽しくてうっひょーなので仲間を増やしたいという気持ちもあって記事を書くことにしました。
知り合いもほとんどWebエンジニアなんで、機械学習やってる人ってあんまり周りにいないんですお(´・ω・`)
この記事を読んで「これなら自分でもいけそう!」と、挑戦しようと思ってくれる人が一人でもいれば嬉しいです。
機械学習について踏み込んだことは書きません(書けません)。
対象読者
機械学習に興味があるWebエンジニア
筆者のバックグラウンド
仕事:
4年くらいRuby on RailsでWebアプリケーションを開発している。業界歴 ≒ Rails歴
数学:
しんでいる。機械学習挑戦前は中学生レベルの数学力。二次関数でひいひい言うレベル()
TL;DRなのでさきに結末を書いておきます
やりたかったこと
- ツイッターのニュースアカウントから「芸能」「スポーツ」を省いたものをタイムラインに流したい1
もう少し具体的に
- ツイッターのbotアカウントを用意
- Twitter APIでニュースアカウント(@YahooNewsTopics)のツイートを取得
- 機械学習でテキストを分類
- 分類した結果「芸能」「スポーツ」以外であればTwitter APIを叩いてツイート
- リプライに反応して学習
下の画像を見てもらえば一目瞭然だと思います。
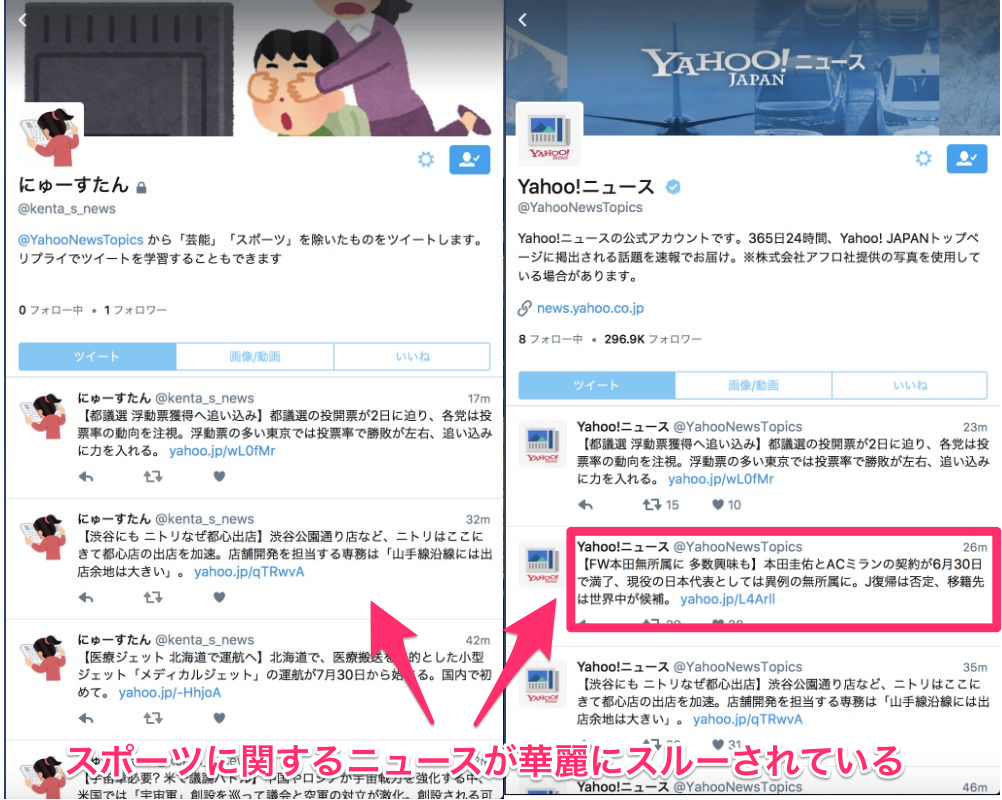
ときどき間違えてツイートしてしまうので、リプライ駆動で自動学習できるようにしてみました↓
なかなかよさそうでしょ??
ずいぶんタイムラインが読みやすくなりました。
現在92%程度の精度で分類できているので十分に実用的なものができたと思います。
まずは機械学習について知る
実は最初まっさきにいきなりChainerのドキュメントを読もうとして失敗しました。
予備知識なしでああいったフレームワークのドキュメントを読んでもちんぷんかんぷんなので、同じ過ちを犯さないようにしてください(汗

最初にすべきは機械学習、とくにニューラルネットについての知識を身につけることです。
Chainerなどのフレームワークのドキュメントを読むのはその後です。 世界が違って見えます
機械学習のまえに数学勉強しなきゃ...><
と思った人、一旦数学のことは考えなくて大丈夫なので、騙されたと思って以下に紹介する書籍を読んでみてください。
1冊目
機械学習入門 ボルツマン機械学習から深層学習まで

「簡単すぎてちょっと...」みたいな意見が多いみたいですが、
自分にとって簡単すぎるどころか、どうにかギリギリついていけるという感じでした。
僕と同じようにこれまで機械学習について全く学んだことがないということであれば文句なしにおすすめです。
数学知識がなくても読めるようになっているので構えず気軽に挑戦してみてください。
誰かが「機械学習入門の入門」だと言っていましたが、まさにそんな感じです。
表紙がちょっとつらいかもしれませんが耐えてください。
2冊目
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

定番らしいので2冊目にはこれを選びました。
この本、表紙の雰囲気からなんとなく難しそうな印象受けるかもしれませんが、
ところがどっこい、入門レベルでもついていけるくらい優しく丁寧です2。
実際に実装するときは普通ChainerやTensorFlowなどのライブラリを使うことになると思いますが、この本ではそういったライブラリを使わずにディープラーニングを自分で実装していきます。
この本で「機械学習でできる基本的なこと」を実現するために最低限必要な知識が身につきます。
余談ですが、これのおかげでだいぶ数学知識が増えました。
3冊目
Chainerによる実践深層学習

2冊目を終えた時点で目標を達成するには十分な知識が身についたという手応えがあって、あとはフレームワークの使い方を知れば実現できるだろう、という読みで3冊目にこれを選びました。
アヤメ(iris)という花の種類を、
- 花びらの長さ
- 花びらの幅
- がく片の長さ
- がく片の幅
の四つのデータから、
- setosa
- versicolor
- virginica
のいずれかに分類するものをChainerを使って実装していくという内容が盛り込まれていて、
偶然にもこれがまさに僕がやりたいことに近くて大変参考になりました。
ちなみにこのIrisデータは機械学習のサンプルデータとしては定番のものらしいです。
この本の「ニューラルネットのおさらい」という章のニューラルネットの説明もわかりやすくて良いですよ。
以下の記事を読んでからずっとChainerを触ってみたいと思っていたので、他のフレームワークは検討しませんでした。
初心者がchainerで線画着色してみた。わりとできた。
もし他に興味を持っているフレームワークがあれば3冊目は好きなものを選んでください。
その場合サンプルコードがあるものをオススメします。
本を読む上での注意点
数学の知識不足が原因で理解できないところに遭遇することもあると思いますが、
意外と求められる数学知識は少ない3ので、ぜひめんどくさがらず数学も都度勉強してください。
ギリシャ文字だらけの一見難しそうな数式も、大半はたいしたことないです。
幸い数学は十分に枯れた技術(?)なので、ググればわりと簡単に正しい情報を見つけられます。
嘘にまみれたプログラミングの情報とは大違いで助かります...バージョン違いとかもないですし(なんの話だ)
あ、偏微分を勉強していたときに見つけたこの記事にはお世話になりました↓感謝です。
微分をおさらいしつつ偏微分をつまみ食い!
もうひとつ。
みなさんにとっては言うまでもないことだと思いますが、
書籍だとDeprecatedな情報もそれなりにあります。
自分で実装するフェーズになると、いくらかそういった知識をアップデートしなければいけません。
書籍はあくまで「機械学習とはなんぞ」を理解するためのツールとして割り切りましょう。
あとは作るだけ
いきなり作れとかどうかんがえても無理だろjk...と思うなかれ。
紹介した三冊の書籍を読み終わった頃には、やりたいことを実現するための道筋は描けるようになっているはず。
まじです。あとは作るだけです。楽しんでください ![]()
本三冊読むくらいでできるんならやってみてもいいかな、と思いませんか。
クローリングしてテキストを取ってくるだとか、API叩くだとか、Cron回すだとか、機械学習以外の技術もいろいろ必要になってきますが、
そのあたりの話は普段からWebやってるみなさんならきっと朝飯前ですね ![]()
![]()
結局勉強開始から完成までどのくらいかかったん
予備知識なしの状態から勉強を始めてモノができるまでどのくらいの時間をぶっこめばいいのか、忙しいみなさんには気になるところだと思うので、
僕の場合どんな感じだったのかツイートとGitHubを掘り起こして調べてみました。
2017/5/23 機械学習の勉強開始
前進計算 とは
— kenta-s (@kenta_s_dev) 2017年5月23日
唐突で意味不明ですがChainerのドキュメントを読みはじめたらしいです。ムチャシヤガッテ...
このあとわりとすぐに無理だと悟って機械学習関連の書籍(この記事で紹介してるやつ)を読み始めました。
2017/6/14 手を動かし始めた
最初にコミットした日がそうだったはず
2017/6/15 機械学習が動いた
ニュースツイットの分類うまくいったっぽい
— kenta-s (@kenta_s_dev) 2017年6月15日
とりあえず動いた。よかったね自分
2017/7/1 bot含めて全部完成
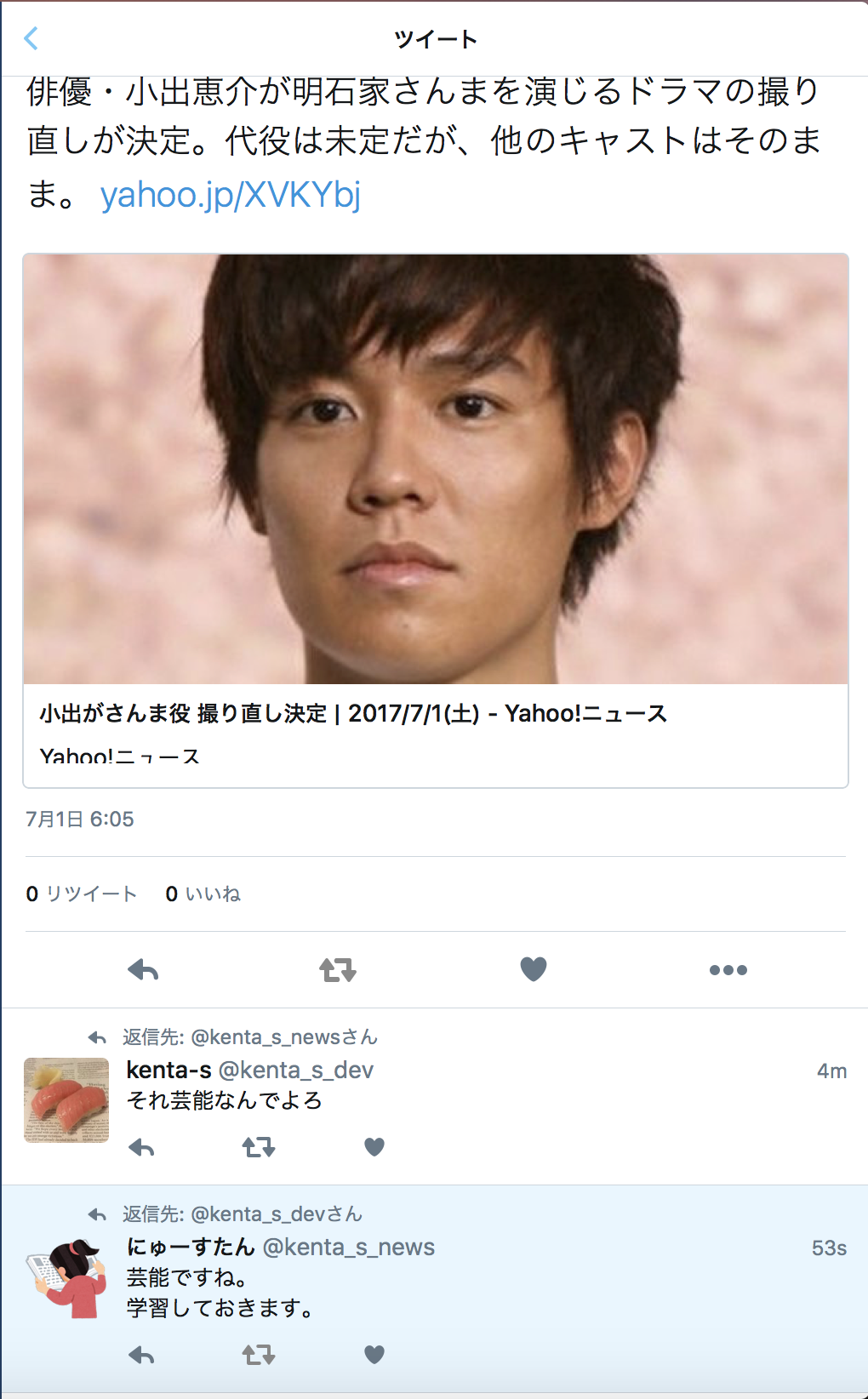
それ芸能なんでよろ
— kenta-s (@kenta_s_dev) 2017年7月1日
botに対するリプライです。
このリプによって、対象のツイートが「芸能」であることが学習されていました。
全部で39日くらい掛かってます。
振り返ってみると結構時間掛かってるなーという感じですが、普通にフルタイムで仕事してますんで...(言い訳ですねはい)
あでも自分の場合数学の勉強にも結構な時間を使ってしまったんですが、
学生時代まじめにやっていた人ならもっと早いのは間違いないと思います。
踏んだ罠
完成までにいくつか罠を踏んだので紹介しておきます
ラベリング作業が心を折ってくる罠
機械学習には、訓練データと呼ばれる大量のデータが必要になります。
今回まずは以下のようなJSONファイルを用意しました。
{
"12345678": {"content": "【中日戦】 阪神が27日の中日戦で敗れ今季ワーストの連敗5", "label": null},
"12345679": {"content": "叶姉妹めっちゃゴージャス", "label": null},
"12345680": {"content": "築地どうなるの", "label": null},
"12345681": {"content": "錦織圭すごい", "label": null},
...
}
※"12345678"などと書いてあるところはtweetのidです。
これをひとつずつ自分自身の目で読んで
芸能なら
"label": "1"
スポーツなら
"label": "2"
その他なら
"label": "0"
のようにラベルを付けていきます。
と簡単に書きましたが、結構な数になってくるのでこの作業がなかなかの心ブレイカーです。
今回2000個くらいツイートを用意していたんですが、途中でつらみが爆発してラベリング用のRailsアプリを自作しました

これ作るのに2日くらい掛かってしまったのと、ラベリングのめんどくささに気持ちが萎えて勢いが落ちてしまったのも完成までに時間が掛かった要因になってます。
自分でラベリングを行うのであれば、少しでも効率的にできる何かを用意しておいたほうが良いです。
Twitter API制限されまくりな罠
当初にゅーすたん(botの名前)は公開アカウントでした。
パクツイは著作権的にアウトなので、引用元を示すべくツイートの最後に「 from @YahooNewsTopics 」という文字列を付与していました4が、
Twitter APIのツイートの自動化に関する規約をよく読むと、「相手の許可なく@付きでツイートしまくるのはダメ」とありました。
考えてみると当たり前な話ですが、これに気づかず2度もAPIの書き込み制限を食らってしまいました。
@YahooNewsTopicsさん、Twitterさんすみませんでした...

※書き込み制限を食らっているにゅーすたん
ツイートから@を外す必要があったんですが、
公開アカウントのままだと著作権的アレがアレなのでにゅーすたんは鍵付きアカウントとなりました。
機械学習結構メモリ食うけど金は用意してるんだろうな罠
はじめはAWSのt2.nanoインスタンス上で動かそうとしていました。メモリ500MBの代物です。
機械学習にはさすがに無理があって、あっけなくプロセスしぼんぬ...
Jun 29 01:01:40 ip-172-31-27-209 kernel: [4522808.542216] Killed process 6047 (python) total-vm:1202856kB, anon-rss:446408kB, file-rss:0kB
Jun 30 01:01:50 ip-172-31-27-209 kernel: [4609218.356072] Killed process 12760 (python) total-vm:1203212kB, anon-rss:446836kB, file-rss:0kB
やむを得ずt2.mediumにしました。
AWS高いお...(´・ω・`)
今回クラウドにこだわっているのはリプライ駆動機械学習をやりたいという理由だけなので、
特別な理由がない限りみなさんはローカルのマシンで学習させればいいと思います。
そのかわりMac捨てて謎のAI半導体メーカー5製GPUを使いたくなるかもしれません。
最後に
