
こちらシリコンバレーではあいかわらず毎日誰もがAIの話をしたがっています。スタートアップもAIの文字を投資家に対するプレゼンテーションに入れておかないと投資が取れないって言われたりしています。最近日本の方たちともよく話す機会があるのですが、どうやら日本も同じようです。AIじゃなくてもAIって言わないとプロジェクトの予算が取れないって話を聞いたりするくらいです。
ということで、なんだか急にAI革命ともいうべきものが始まったかのようですが、歴史を紐解くと実は何もAIというのは最近始まったものではないんですね。実は、第二次世界大戦中にイギリスのアラン・チューリングという人がドイツのエニグマというマシーンの暗号を解読するために取り入れたコンセプトがAIの始まりだったりします。(この辺は、映画の”イミテーション・ゲーム/エニグマと天才数学者の秘密”に詳しく描かれていたりするので、もしまだの人はエンターテイメントとして見てみるのをおすすめします。)

第1の波:アルゴリズムの商品化
実際、かれこれ20年近く前まで遡りますが私が大学を出て仕事としてデータ分析の世界に足を踏み入れた頃、当時はSAS, SPSS, IBM, Oracleと言ったエンタープライズ・ソフトウェアのベンダーがこういったいわゆるAIのためのアルゴリズムを提供していたものでした。当時はあえてAIとは呼んでいなかったように思いますが、今日いわゆるAIアプリケーションなどと言われてるものに使われているアルゴリズムと基本的には一緒だと思っていただいていいと思います。
ただ、こういったアルゴリズムというのはとても値段が高くて使うのも難解でしたので、ちゃんとプロとして教育された統計学者でさらにそういった何千万、何億円とするものすごく高いライセンスを払える人たちにしか実際は使うことができないというものでした。しかしこうやって高いお金を払う必要はあったものの、実はこうしたパッケージを買えばそういったアルゴリズムがすぐに使えるということ自体は革命的なことでした。何と言ってもそれぞれの組織は自分たちでそういったアルゴリズムを作らなくて良くなったわけですから。この革命を私たちは、アルゴリズムの商品化と呼んでいます。
ところが時代も変わったもので、今日AI、機械学習、もしくはデータサイエンスなどというと、そういった昔ながらのエンタープライズ・ソフトウェアのベンダーの名前を聞くことはまるで無くなりました。その代わりに、オープンソースのライブラリーやアルゴリズム、もしくはそういったものを作っているシリコンバレーの先進企業であるGoogle、Facebook、Airbnbなどを思い浮かべる人も多いのではないでしょうか。
第2の波:アルゴリズムのコモディティ化
現在、AIもしくは機械学習のアルゴリズムはオープンソースであるがゆえに無料で誰にでも使えるということで以前に比べると様々な場面ではるかに多くの人たちに使われています。
さらにオープンソースであるということでコミュニティ参加型の開発によるスピードがとても速く、イノベーションがとてもダイナミックであるということも多くの人たちに使われてる理由の一つでしょう。実は今日データサイエンティストの人たちがこういったオープンソースのアルゴリズムを昔ながらのエンタープライズ・ソフトウェアのベンダーから提供されるものよりも好んで使うというのは、ただ単純に安いということだけではなく、そのクオリティの高さ、さらには今日の、インターネット、クラウド、モバイル、さらにはIoT等によってもたらされた、ものすごくサイズが大きく様々な形態をしたデータ(いわゆるビッグデータ)に特有の問題を解決するのに適しているという実用的な理由が大きかったりします。
オープンソースのAI/機械学習アルゴリズム
それでは、そういった最先端のAIもしくは機械学習のアルゴリズムというのは一体どういったものなのでしょうか? 具体的にシリコンバレーではどういったものがどう実際のビジネスの現場で使われているのかをさらっと見てみましょう。
2014年の9月にGoogleはCausal Impactという名のパッケージをオープンソースとして公開しています。これは時系列のデータに対する因果分析にベイジアン・アプローチを用いた仕様のアルゴリズムです。ちょっと話が硬くなってしまいましたが、実際にはGoogleのデータサイエンティストたちはこれを使ってある広告キャンペーンがウェブサイトへのトラフィックもしくはそのページ上のリンクのクリック数などにどれくらい影響したのかを理解し、ROIをより正確に計算するのに使っていたりします。
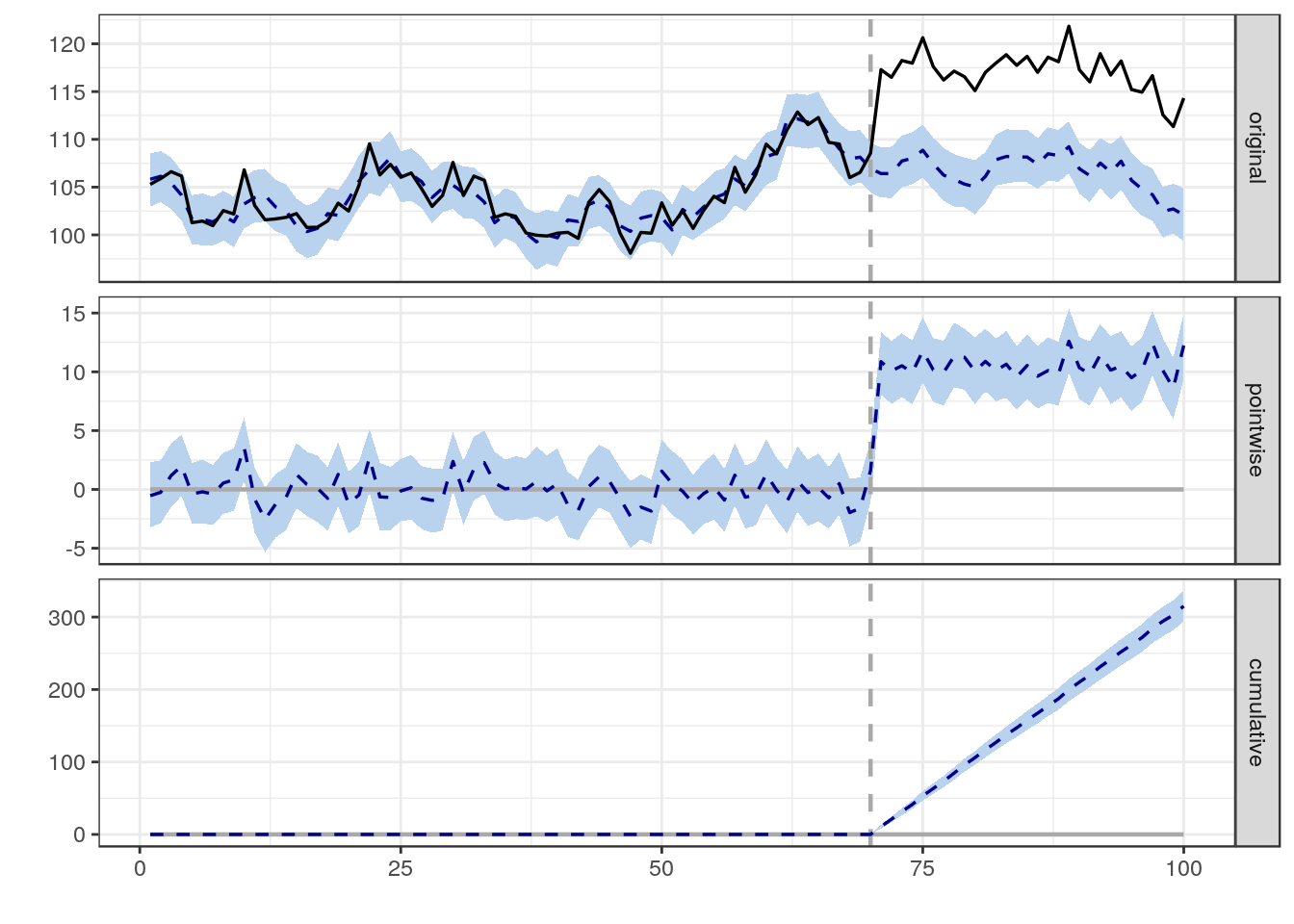
2015年の1月には、TwitterがAnomaly Detectionという名のパッケージをオープンソースとして公開しています。こちらは季節的な傾向を考慮に入れながら時系列のデータに対して異常値を検出するというアルゴリズムです。Twitterのデータサイエンティストたちはこれを使って彼らのサイトに来る想定以上のトラフィックを検出しそこからさらに何がトレンドであるかを理解するのに役立てたりしています。
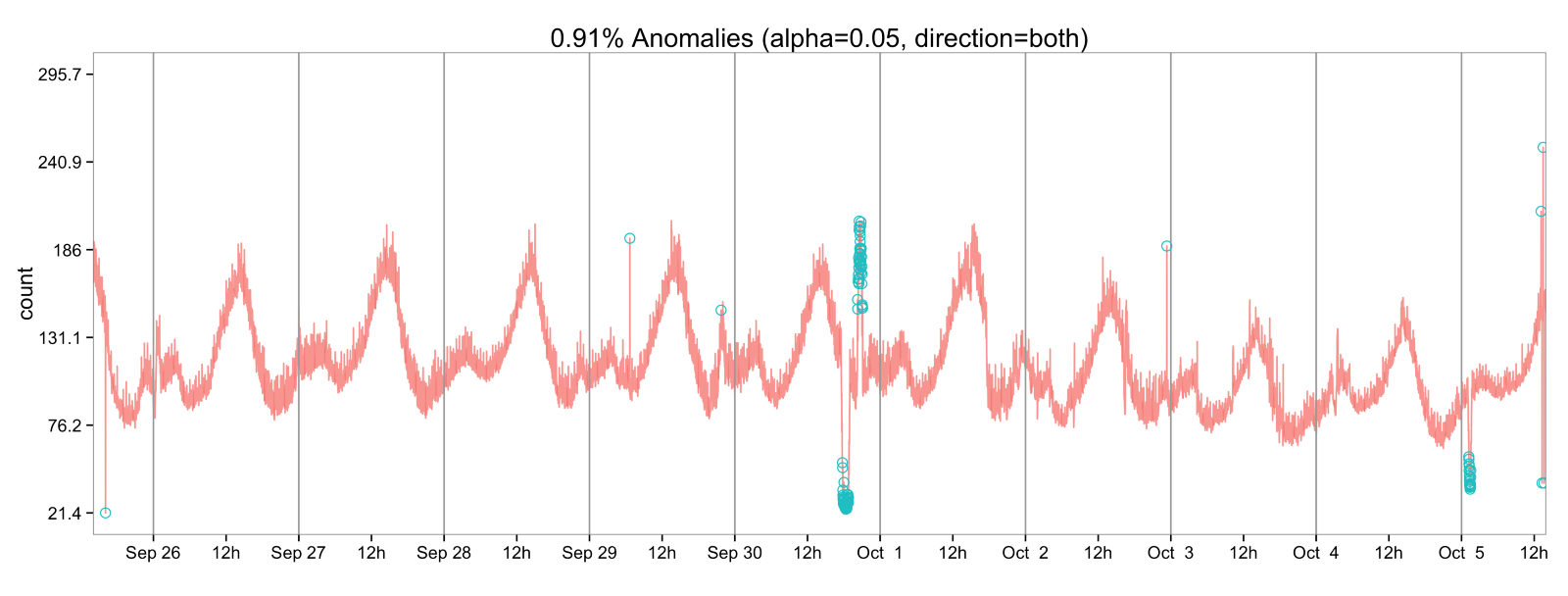
同じ2015年の6月には、AirbnbがAerosolveという名の機械学習のフレームワークをオープンソースとして公開しています。Airbnbのデータサイエンティストたちはこれを使ってホテルの値段設定の最適化、需要の予測やシミュレーションなどをしています。
さらに同じ2015年、11月にはGoogleがTensor Flowというニューラルネットワークのアルゴリズムを使ったモデルを作るための深層学習のライブラリーをオープンソースします。彼らはこれを使って、Search Signal, Email auto-responder, Photo Search, Voice, Translate等の製品を作っています。
2017年の2月にはFacebookがProphetという時系列データを予測するためのアルゴリズムをオープンソースとして公開しています。こちらは内部で統計モデリングのためのプログラミング言語であるスタンというフレームワークを使った新しいタイプの予測アルゴリズムであり、今まで一般に使われてきた多くの予測アルゴリズムよりも格段に使いやすく、さらに時系列の予測といった分野の素人でも簡単に高いクオリティの結果を出すことができるということで大きな注目が集まっています。Facebookのデータサイエンティストたちはこれを使って彼らのウェブサービスへの需要を予測し必要なリソースの準備、割り当ての最適化に使っています。
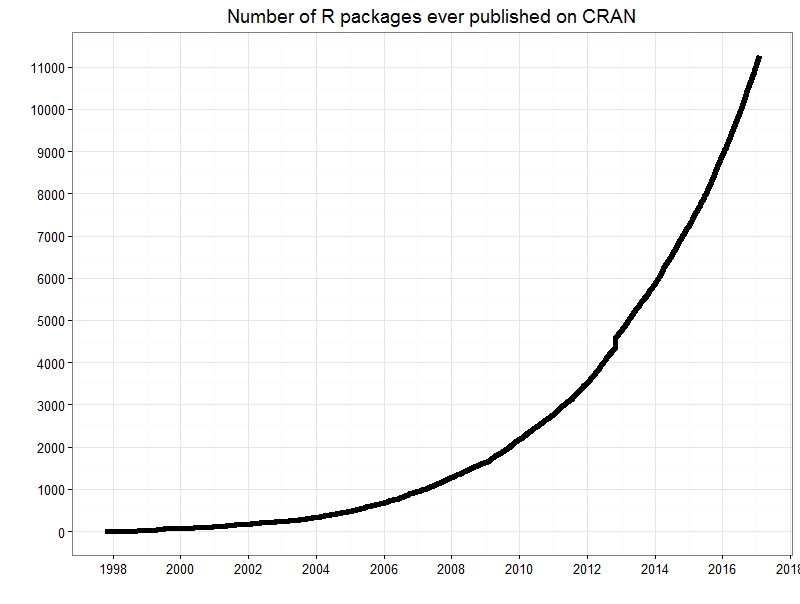
幾つかの例を走り書きしましたが、こういった例は氷山の一角に過ぎません。実はこうした名の知れたシリコンバレーのテクノロジー企業がオープンソースとして公開するアルゴリズムの何百倍もの数のアルゴリズムが情熱的な世界中の個人、または学校なども含めた様々な組織によって日々開発され、オープンソースとして公開されています。こちらに代表的なデータサイエンスのプログラミング言語であるR言語のエコシステムに、過去20年ほどでどれだけ多くのパッケージが追加されていっているのかを示したチャートを載せておきます。
こうしたことからもわかるように、実は現代のデータサイエンティストたちにとっての最大のチャレンジは、どうやって既存のアルゴリズムを最大限に活用するかではなく、どうやって毎日のように出てくる最先端のアルゴリズムの情報を絶えず仕入れ正しく理解した上で、その時々の課題を解決するのに最適なものを選んで使うかということになります。
このAI、機械学習の世界で起きている破壊的な革命のことを、アルゴリズムのコモディティ化と呼んでいます。こうしたクオリティーの高いアルゴリズムを使うことにかかるコストはほとんどゼロになったことで、突然ものすごい数の最先端のアルゴリズムに世界中の誰でも簡単にアクセスすることができるようになったのです。
プログラマーはAI、ノンプログラマーはBIでいいのか?
しかし一つ大きな問題が残りました。それはこうしたアルゴリズムは実はいわゆるデータサイエンス言語として代表的なR言語やPython言語を使ってプログラミングをすることによって初めて使うことができます。当然、急にみんながプログラミングできるようになるわけではありませんので多くの会社はデータサイエンティストという、そうしたデータサイエンス言語を使ってプログラミングしながらオープンソースのアルゴリズムを使い、データから深い洞察を効率的に得ることができる人たちを雇うことになります。しかし、全ての人がそういったコストが非常にかかるデータサイエンティストを雇えるというわけではありません。さらにまだデータサイエンス自体が世間一般に理解されていないという今日のような状況では実はそうしたデータサイエンティストを雇うというのは簡単にはいきません。

結局、データを実際に持っていてそれを実際のビジネスにおける課題を解決するために使うニーズのある多くの人たちは、もしプログラミングができたらすぐに使うことができたであろう先進のアルゴリズムの恩恵にあずかることができないばかりか、エクセルやTableauと言った昔ながらの単純な集計の計算をするのに適したBIツールを使い続けるという歪んだ状況になっているというのが現状です。
しかし、そういったプログラミングが必要という前提条件なしに、誰もが上の方で紹介したようなデータ先進企業が最先端のAIや機械学習のアルゴリズムを使って行っているような分析の手法を普段のデータ分析の一環として使うことができたら素晴らしいと思いませんか?
第3の波 :アルゴリズムの民主化
そうしたわけで、最近ではUIベースでそうしたオープンソースのアルゴリズムをプログラミングなしでデータ分析の一環として使うことができるというのが売りのビジネスユーザー向けのデータサイエンス・ツールがちらほらと出てき始めました。私どもがシリコンバレーでやっているExploratoryであったり、フランスのDataikuといったものがそういったツールの例ですが、そうしたツールは、アルゴリズムのコモディティ化という第2の波に乗ることのできなかった人たちにそうしたアルゴリズムへの簡単なアクセスを提供しています。
例えばいわゆるR言語のUIとして業界では広く認識されているExploratory はそのユーザーの多くがデータサイエンティストと言うよりも、マーケティング、金融、生産管理、物流、教育などといった実際のビジネスもしくは業務に関する深い経験と知識のあるビジネス・アナリストもしくはコンサルタントの方達です。こうした人たちが上の方に紹介したようなAIや機械学習の最先端のアルゴリズムを使って様々なビジネスの課題を効率的に毎日解決しています。
データ分析の世界では、一般にR言語、並びにPython言語のユーザー数が世界中に4万人いると言われています。しかしそれは600万人を超えると言われている世界中のエクセルユーザーの数に比べるとたったの
0.6%
でしかありません。そうしたデータをもっと深いレベルで理解するという潜在的なニーズのある残りの99%以上の人たちにとって、オープンソースで高いクオリティを誇るアルゴリズムに簡単にアクセスすることを可能にするこうした次世代のUIをベースにしたツールに求められる期待は日々高まっています。こうしたデータ分析の世界で次に起きるであろう破壊的な革命を私たちは第3の波として捉え、アルゴリズムの民主化と呼んでいます。
ここで今まで出てきたそうしたAIや機械学習の革命の歴史をわかりやすく一つのチャートにしてみると以下のようになるかと思います。

まとめ
この20年でインターネット、クラウド、モバイル、さらにはIoTなどの出現と浸透によってデータの世界はものすごい変化を遂げました。データを収集するのは以前よりもっと簡単になり、その量は飛躍的に増えていくばかりですし、そのデータが蓄積されていくスピードは加速度的に増える一方です。こうした、ともすると宝の持ち腐れになってしまう可能性のあるいわゆるビッグデータと言われるデータの山をいかに効率的に活用していくかというのは、日々様々なビジネスで起こる課題を的確に素早く解決していくことを求められている現代のビジネスパーソンにとって最も必須なスキルだと言われています。実際こちらシリコンバレーでは、データに対するリテラシーのない人材はCレベル以上(CEO, COO, CMO, CHRO, CIO, etc.) には進めないと言われています。
シリコンバレーのデータ先進企業がますますグローバルに競争力を高めている中で早急に答える必要のある質問とは、彼らが日々ビジネスの現場でデータを効率よく分析しそこから得た洞察を活用していくというデータサイエンスの手法を自分たちのビジネスにも応用する必要があるかないかではなく、それをいつどのように始めるかということではないでしょうか。
アルゴリズムの民主化というフェーズはまだ始まったばかりです。これからの数年でもっとたくさんのイノベーションがその約束を実現するために生まれてくることでしょう。既存ビジネスにおける競争力の強化、さらには新しいビジネス機会の創造はもちろんのこと、個人の成長、キャリアの形成にとってもとてつもなく大きなインパクトを与えることになるこうした革命的な機会の波を逃さず、実際に乗りこなすことができる人たちが日本にもたくさん増えることを願うばかりです。
第3の波に一緒に乗りませんか?
そしてそういった変化を起こす、もしくは実行することを非力ではありますがExploratoryとして側面から支援することができれば幸いです。その一環として、まずは日本で最初の、データサイエンス・ブートキャンプ・トレーニングをこの6月に予定しております。こちらシリコンバレーのデータ先進企業でデータサイエンティストが毎日ビジネスの現場で行っているデータサイエンスの手法を基礎から体系的に、プログラミングをすることなしに一気に学び、日常の業務で使いこなすことができるレベルまで手を実際に動かしながら習得してもらおうとするものです。詳しくはこちらの方にありますので、よろしければぜひご覧くださいませ。
私自身もトレーニングのインストラクターとしてフルタイムで関わりますので、興味のある方は当日お目にかかれるのを楽しみにしております。
何かこの記事に関して、もしくはトレーニング・プログラムに関してなど質問や感想などありましたら是非お聞かせください。メールの方はこちらになります。kan@exploratory.io