最近バーチャルユーチュ-バーが人気ですよね。自分もこの流れに乗って何か作りたいと思い、開発をしました。
モーションキャプチャー等を使って見た目を変えるのは かなり普及しているっぽいので、自分は声を変えられるようにしようと開発しました。
やったこと
キズナアイさんとねこますさんの、それぞれの声を入れ替えられるようにしました。これによって、ねこますさんのしゃべった内容を、キズナアイさんの声でしゃべらせることができます。(逆も)
機械学習手法の一つであるCycleGANを用いて、変換するためのネットワークを学習しました。
パラレルデータ(話者Aと話者Bが、同時に同じ内容を話した音声)が必要ありません 。YouTubeから拾った音声でも変換ができます。
当然ですが、一度学習すれば、利用時には何度でも繰り返し利用できます。
期待できる効果
見た目だけでなく、声まで美少女になれます。やったね。
他にも映画の吹き替えが、本物の役者と同じ声でできるようになったりします。しかも、パラレルデータが必要ないので、頑張って英語を録音する必要はありません。
アニメなんかも声優の声を利用させて貰えば、一人で全てのキャラクターの声を入れられるようになると考えられます。もちろん声優の声ではなく、ボイスロイドなんかの声を変換対象にすることもできると思うので、ギャランティーを押さえることもできる……かもしれません。
結果
GitHubにデモ音声を置きました。
https://github.com/pstuvwx/Deep_VoiceChanger/tree/master/demo
変換元音声の出所はこちら。
【LIVE】今夜はフリートーク♪【 Streaming #02】
LINE公式スタンプ発売なのじゃー!【021】
ソースコードはこちらで公開しています。
環境
機械学習にはChainerを利用しました。
音声の読込・出力にはscipyを、フーリエ変換にはnumpyのfftを利用しました。
学習に使用した音声は
【放送事故もそのまま出すよ!】100万人ありがとう記念LIVE配信!!(4:30~)
【生放送】みんなでアニメ語りしてみた!
バーチャルYoutuberになるには【Live008】
音声はフリーソフトを使って、音質が16kHzかつ音量が89dBのwaveファイルに変換しました。
原理
パラレルデータ
既存手法の多くはパラレルデータというものを使います。これは、AさんとBさんが同時に同じ内容をしゃべった音声を指します。パラレルデータを使い、Aさんの言ったこの部分は、Bさんのこれに該当するよね、という風に変換や学習を行うらしいです。
しかしながら、キズナアイさんとねこますさんが同じ内容を同じタイミングで話してくれるというのは、本人に依頼しない限りほぼ無理でしょう。なので、自分で気軽に音声を入手できない場合には、かなり厳しいものがあると思います。
CycleGAN
機械学習やGANについては、分かりやすくてしっかりした記事がたくさんあるので、それを参考にしてください。ここではCycleGANの概要とパラレルデータが不要であることについて、簡単に述べます。
CycleGANは、二つのデータセットの間の関係を学習し、変換するネットワークを学習してくれるGANの一種です。
ネットワークはGa・Gb・Da・Dbの4つがあります。GaはデータセットAのデータをデータセットBのデータに変換します。GbはデータBをデータAに変換します。Daは、データセットAのデータと、データセットBがGbによってデータAに似せられたデータを識別します。Dbも同様です。
このとき、[ データA -Ga→ 偽データB -Gb→ 偽データA ]という変換をします。そして、変換されたデータAと偽データAが等しくなるように(元に戻るように)学習し、かつ、偽データBがDbを騙せるように要求します。さらにGaにデータBを入力すると、何もせずそのまま出力するように求めます。
Da・DbはGa・Gbが似せたデータを、識別できるように学習します。
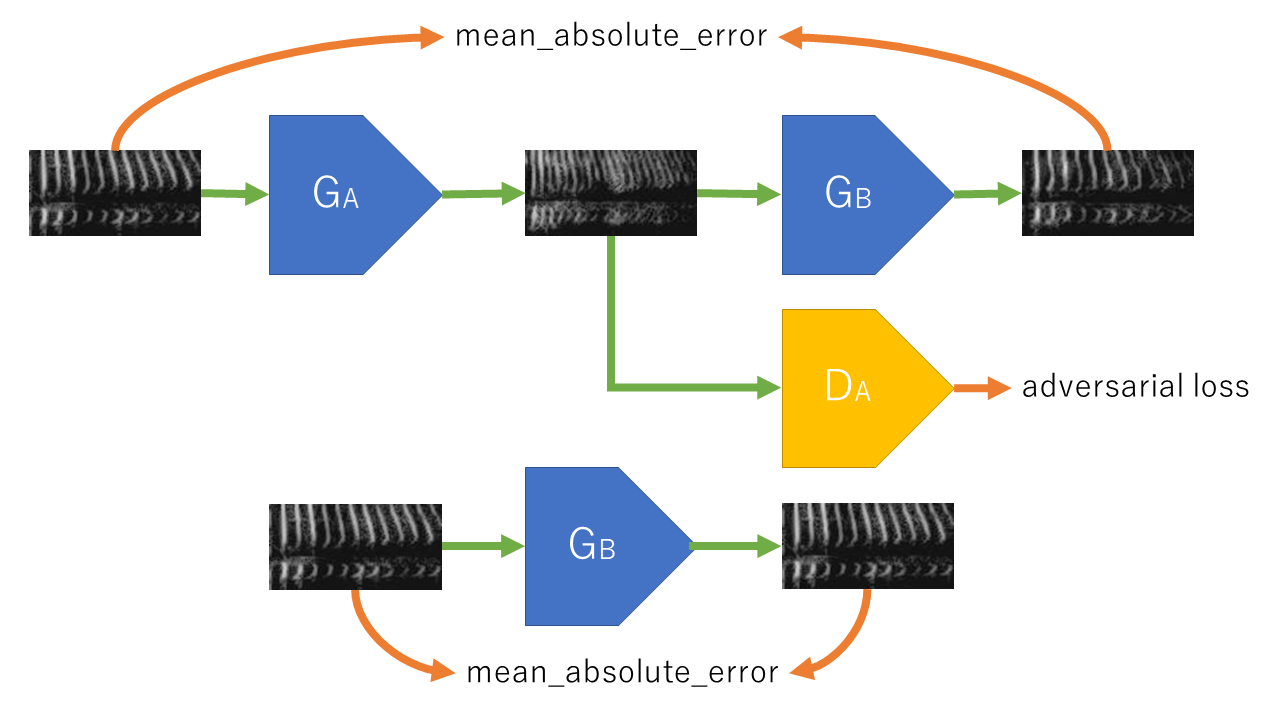
GはDに識別されないように、変換したデータを本物に近づけようと頑張ります。逆にDはGが似せてきたデータを判定できるように頑張ります。DとGが互いに競い合うことで、Gの生成するデータはどんどん本物らしくなります。
また、Ga→Gbによって元に戻るように要求されるので、GはデータセットAとデータセットBの間の関係を探して、対応する変換を学習してくれます。そのためデータのペアは必要ありません。
学習データの用意
変換したい音声を用意します。音声は対象者の声だけが含まれていることが好ましいと思います。適当なエンコーダーで音声を16kHzにします。
音声から5120点を取り出します。16kHzサンプリング音声で0.32秒です。
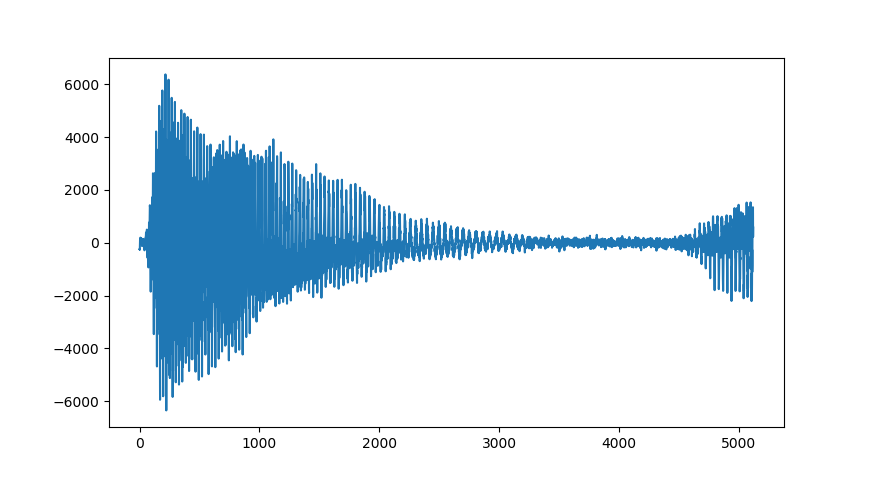
ここからさらに254点ずつに分割します。このとき重なり合う部分ができるように、64点ずつずらしながら80個に分割します。
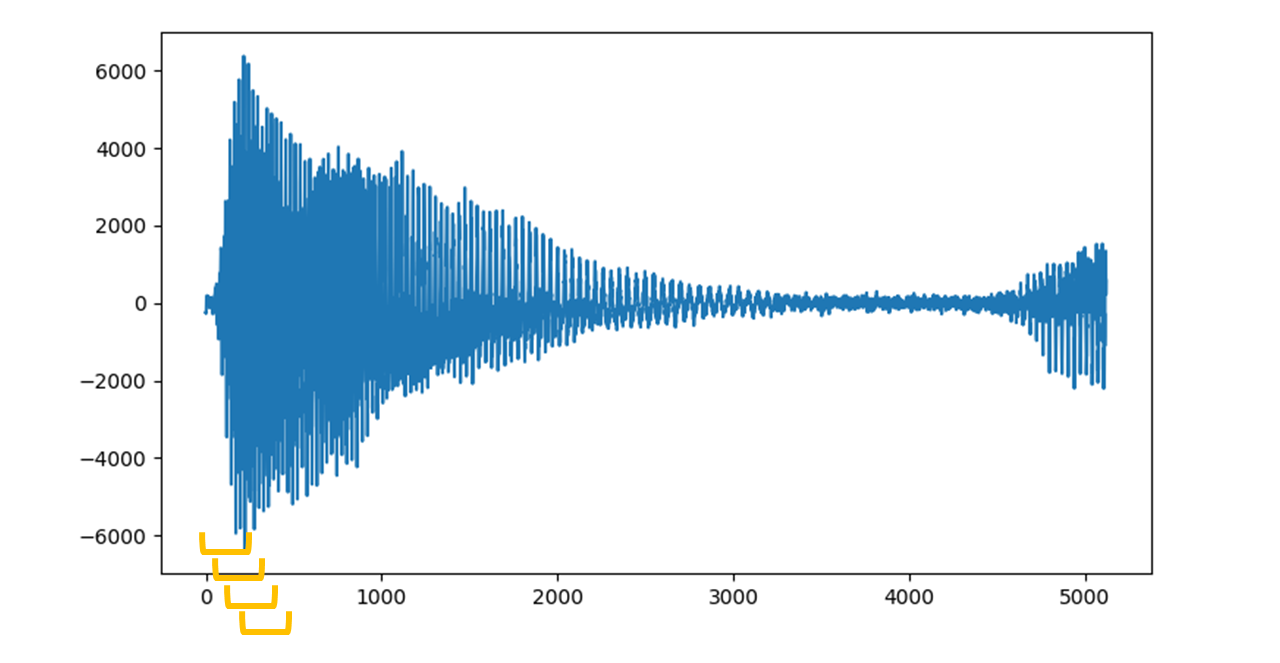
分割した254点の波形に窓関数のhanning窓を掛けて、フーリエ変換します。
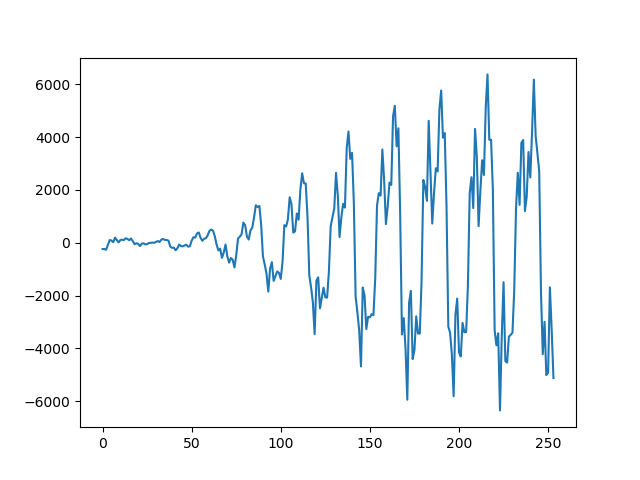
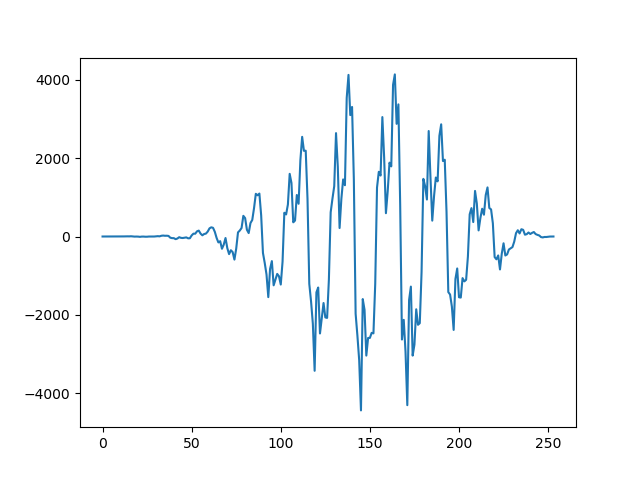
切り出した254点
hanning窓を掛けた後。窓関数を掛けることで頭と尻が0になり、周期関数と見なせる。
フーリエ変換後の実部と虚部
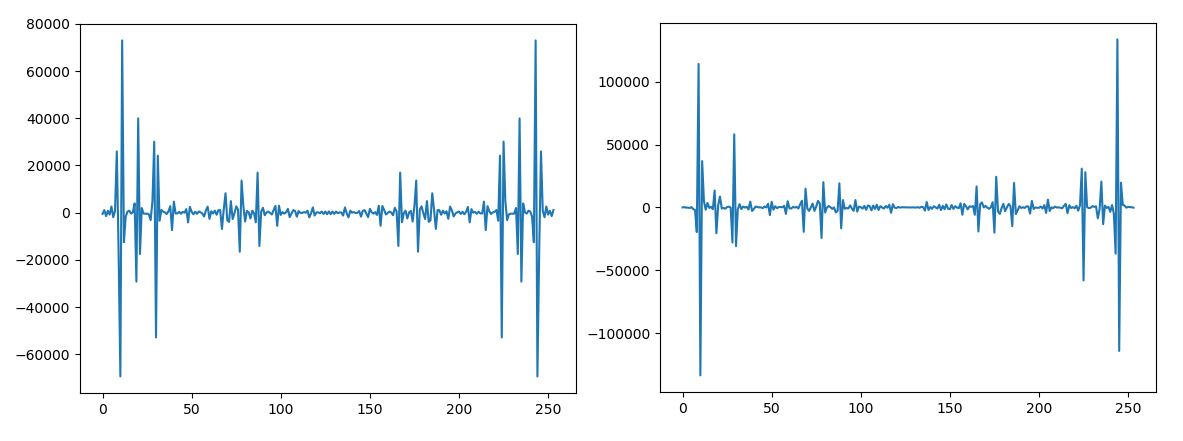
フーリエ変換することにより、情報は実部と虚部に分かれます。一見すると情報量が二倍になったように思いますが、フーリエ変換は真ん中から複素共役の関係にあり左右対称となります。254点にすると126点が共役により無駄な部分となり、必要部分は128点となります。なので0~127番目までを切り出して使用します。
得られたスペクトルの絶対値をとります。小さい音やノイズを無視するため1000以下を1000にクリッピングします。対数スケールにするため自然対数を求めます。0~1に正規化するために6.2を引き9で割ります。
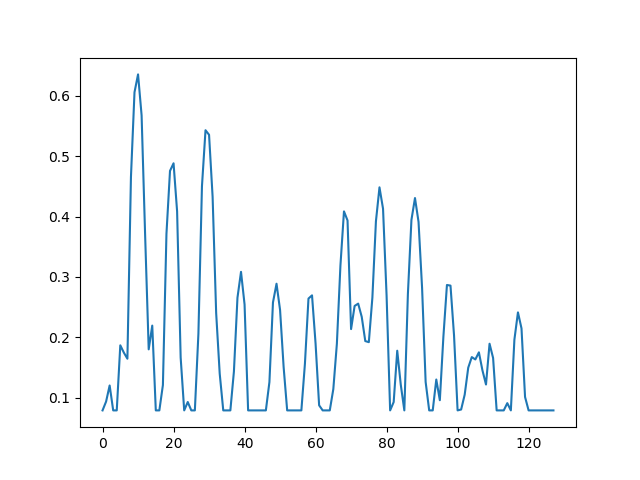
これを80個並べることで、80×128画像のスペクトログラムを得ます。これが入力用のデータです。出力されるデータもこの形になります。

音声への復元
学習に使用したデータはフーリエ変換の絶対値をとっているので、そのまま逆フーリエ変換することはできません。そのため位相推定という処理を行います。
位相推定は、絶対値処理によって失われた位相情報を近似で求める処理です。近似なので正確には復元されません。位相推定はGriffin/Lim Algorithmというものを用いました。
Griffin/Lim Algorithmは、「フーリエ変換として辻褄の合う位相を求める」という処理です。こちらのpdfが非常に参考になりました。
簡単に書くと次のようになります。
スペクトル絶対値Aを適当な位相Nで初期化しXを作る。 ( X = A * N )
① x = IFT(X)
② X = FT(x)
③ X = A * X / |X|
①~③を適当な数(50~100回?)だけ繰り返す。
このとき、FFTは学習データの用意と同じ要領でやりますが、IFFTはオーバーラップアッドという処理をしなければなりません。詳しくは先ほどのリンクを見てほしいのですが、ざっくりと表すと下の画像のような処理です。
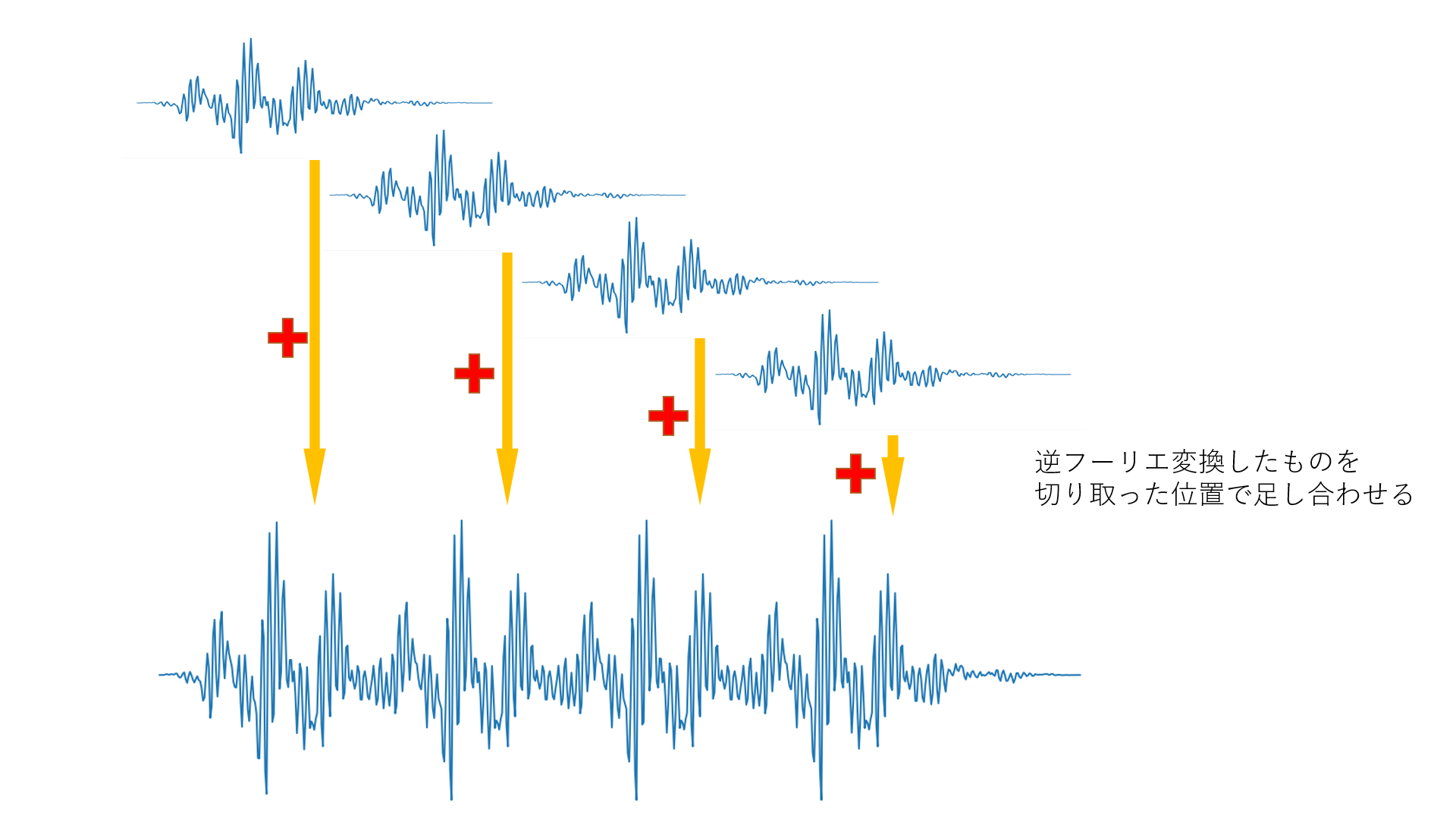
逆フーリエ変換したものを足し合わせるだけです。窓関数ですぼんだ形になった波形を、重なるように足し合わせることで復元します。データ用意のところで、重なるように切り取ったのはこのためです。
さらにリアルタイムで位相推定することを考えて、以下のように処理の流れを実装しました。
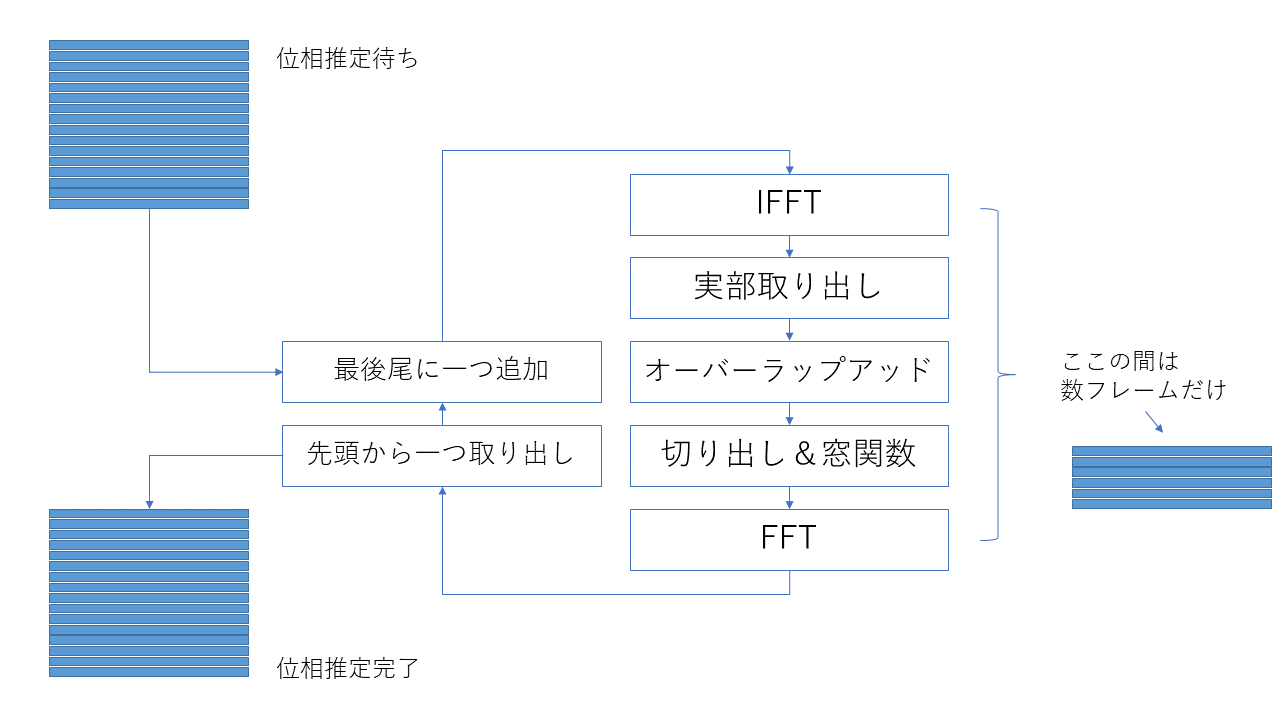
位相推定待ちの行列から一列(254点のスペクトル)を取り出す。
位相推定作業用配列の最後尾に加える。
位相推定作業用配列の先頭から一列(254点のスペクトル)取り出す
位相推定完了行列に加える。
これにより先頭から少しずつ推定することができます。また、推定時間も少し早くなっているはずです。
パラメータ云々
詳しくは、こちらからソースコードを見てください。
モデル構造
現在GitHubに上げているモデルの構造は、音声用にいろいろ変な構造をしています。ここでは、どういう意図で作ったのかざっくり書いていきます。
全結合層
今回扱っているのはスペクトログラムです。スペクトログラムは時間方向と周波数方向の要素があります。ここで多少時間が変化しても、キズナアイさんはキズナアイさんのままです。しかしながら、周波数が変化するとどうでしょうか?音は周波数に大きな意味があります。多少左右にずれただけで、その変化は音に対して顕著に現れます。よって周波数方向を強く意識したモデルが必要となるはずです。
ここで、畳み込み層は位置に依存しないフィルタを用いて、特徴マップを求めます。全結合層は位置に依存し、さらに全ての入力要素を考慮して出力を求めます。そのため、時間方向のために畳み込み層を、周波数方向のために全結合層を並列に導入してみました。
完全に自分の主観ですが、全結合層を導入したことで「本人らしさ」を激増したと思っています。畳み込み層だけの時は、声の高さこそそれっぽくなりましたが、こもった音だったり、本人だとは思いにくい声でした。全結合層を導入したことで、キズナアイさんのクリアな声が手に入ったと思います。
パッディング
声は突然発声できるものではなく、前の声の状態に依存して次の声が出されるはずです。そのため入力データの最初の部分は、その前の状態がわからず変換に手間取るのではないかと考えました。
そこでGenerator入力の時間方向にデータを追加しました。時間方向64、周波数方向128の入力データだったのに、時間方向の先頭と末尾に8行ずつ追加し、80×128のデータを入力としました。
同じものをDiscriminatorに渡してしまっては何の意味もないので、Generator出力の先頭と末尾の8行を削除し、64×128をDiscriminatorの入力としました。
Spectral Normalization
GAN全般に言えることですが、Discriminatorが学習しすぎると誤差がGeneratorにうまく伝播されなくなります。Discriminatorの出力が、本物と偽物の間を緩やかに結んでいれば、その間は勾配があるはずです。その勾配をたどってGeneratorが学習できます。しかしながらDiscriminatorが学習しすぎると、本物と偽物の間の変化は、平たんな部分と一部の崖のような形になります。この平坦な部分では勾配が小さく、誤差が伝播しません。そのためDiscriminatorが学習すればするほど、Generatorは学習しづらくなります。
そこで、リプシッツ連続というものを考えます。入力のxからyへの変化に対する出力F(x)からF(y)への変化の割合の最大値が一定数以下のとき、関数Fはリプシッツ連続となります。
これをDiscriminatorに導入して、Discriminatorの出力を緩やかに変化させようっていうのが最近の基本らしいです。
Spectral Normalizationは、そのリプシッツ連続であることを重要視した正則化方法らしいです。層毎にスペクトルノルムというものをを制限することでDiscriminatorのリプシッツ定数(リプシッツ連続のときの最大変化量)を制御する...とかなんとかですが、詳しいことは他のサイトに任せます。
Spectral Normalizationの実装はこちらのものを利用しました。
https://github.com/pfnet-research/sngan_projection/tree/master/source/links
Minibatch Discrimination
これもGAN全般に言えることですが、Discriminatorはデータ1つに対して判断を下すことしかできません。全く同じ内容の入力しかなくても(例えば全て無音とか)、それが目標データに含まれているものなら識別することはできません。よってGeneratorは一つでも本物らしい出力を得られれば勝利してしまいます。これによりGenerator出力の多様性が無くなり、何を入力しても全く同じ出力を返すようになってしまいます。よくmode collapseなどと言われて、紹介されている現象です。
特に音声の場合は一枚の入力画像で完結するわけではありません。感情など表現するには、淡々と話す時とは違う声色になるはずです。つまり多数の入力画像があって、その分布から個人の声が構成されるはずです。
そのためMinibatch Discriminationというものを導入します。これは入力されたminibatch内での表現の多様性をDiscriminatorに教えるということらしいです。詳しくはこちらでわかりやすく紹介されています。
実装はこちらから利用しました。
https://github.com/pfnet-research/chainer-gan-lib/tree/master/minibatch_discrimination
最後に
※2018/12/8更新
軽い気持ちで公開したこのプロジェクトですが、想像以上に反響をいただきました。GPUの提供や仮想通貨の支援、インターンシップやアルバイトのお誘いなど、たくさんの人が支援していただいたり、関心を持っていただいて、とてもうれしかったです。
しかし様々な人にすごいと言ってもらうにつれて、更新を公開するハードルが上がっていき、なかなか新しいものを公開できずにいました。それでも半年もだんまりはまずいのでは…と思い始め、どこかで折り合いをつけて公開しなくては、という気持ちが強くなってきました。
ひとまず現状をGitHubに上げました。これからはより良い結果ができ次第GitHubのほうで更新します。このプロジェクトに興味を持っていただけた方は、時々のぞいてみてください。
また、現状はネットの海から拾った知識を継ぎ接ぎして作っています。もっといい方法があるよ、というアドバイス等ありましたらご教授いただけると嬉しいです。
GPUをはじめ、仮想通貨やアルバイトお誘いなどご支援ご協力してくださった皆様、本当にありがとうございます。
自分の作ったものはできるだけ公開していくつもりです。何か役に立ちそうだと思っていただけたら、どうぞご利用ください。もちろん自己責任で。