みなさんは退屈なことをPythonにやらせましたか?
私はやらせていませんでした
このC-3POみたいなロボットが芝をかっている表紙の書籍

Pythonの良書として有名で、読んだ人も多いのではないでしょうか?
ではこの本を読んで実際に退屈なことをPythonにやらせた人はいますか?
結構少ないのではないでしょうか?読んで満足する人が多いかと思います。
私もその一人でした。1年ほど前に一度読んだだけ。。。でした
AI研修はじめました
最近はAIがおバズりになられておりますね。いろいろな会社でAIの導入を始めているそうな。
私の勤めている会社も例外ではなく、AI研修というものを導入始めました。
その研修の中で自分で機械学習モデルを作成して、手書き文字の予測を行うという課題がありました。
※Kaggleのdigit recognizerとほとんど一緒です。
課題の流れ
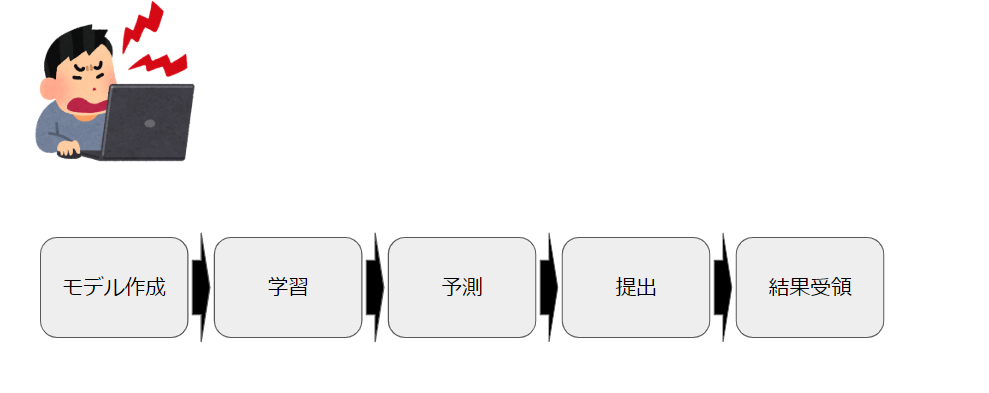
1. モデル作成
ディープラーニングのモデルを定義します。
ここでディープラーニングの層をいくつにするか、各層のノードをいくつにするか?
といったようなモデルの全体的な構成と細かいチューニングを行います。
2. 学習
正解のラベルと手書き文字の画像が対になったデータ(訓練データ)を渡して、モデルを学習させます。
ここで、学習データの一部を検証用データ(3.予測を参照)に見立てて、仮の予測結果を測定することができます。仮の予測結果が高いモデルを以降の作業に使用します。
3. 予測:
手書き文字の画像だけのデータ(検証データ)を渡して、手書き文字の予測を行います。
予測はCSVファイルとして出力されます。
4. 提出:
予測CSVファイルを研修会社が用意したWebサーバにブラウザ経由でアップロードします。
5. 結果受領:
webサーバ上にて予測結果の精度が表示されます。
上記1-5を繰り返して、合格点の精度を取得せよというのが課題でした。
作業ゲー
何回か繰り返していて、これルーチンワークだなと思うようになりました。
モデルの大枠が決まればあとはモデルのパラメータをチューニングして、学習->予測→提出を繰り返しているだけなんですよ。しかも待ち時間がすごく長い!!
これって自動化できないかなと考えるようになりました。
Let's automation with python
では退屈なことをPythonにやらせていきましょう。
もう一度課題の流れを整理
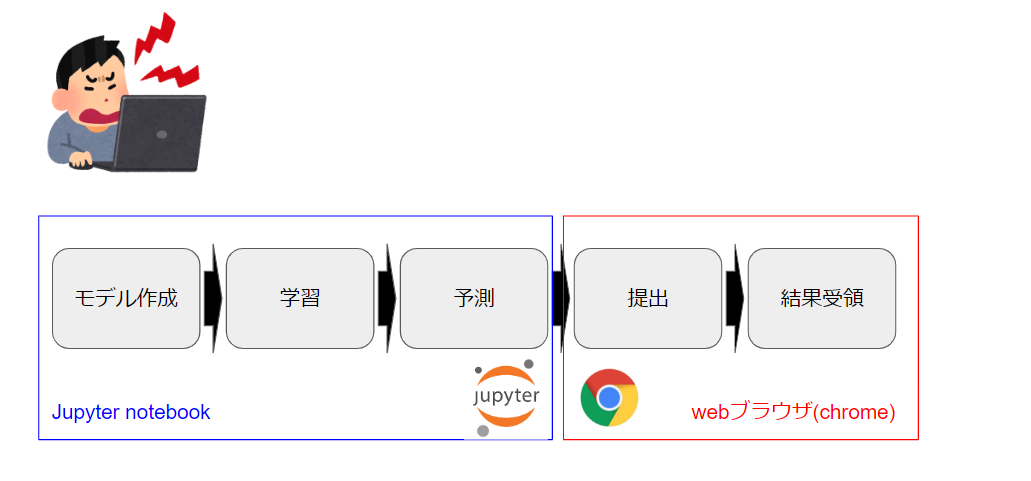
モデル作成/学習/予測
Jupyter notebookという対話型のpython実行環境で行います。
Jupyter notebookで書いたコードをpythonのクラス/関数にして、それにチューニングに使用するパラメータを引数として渡すことで自動化を実現できると考えました。
jupyternotebookのコードをpythonファイルに変換する方法について
https://qiita.com/abts/items/25bb611b6d83e646abdd
提出結果/結果受領
予測にて出力されるCSVファイルをgoogle chrome経由でアップロード用のサイトにアップロードします。
WebブラウザはSeleniumというPythonのライブラリを使用することで自動化することができそうです。
Seleniumについて
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738a
制約 : 一日5ファイルしかアップロードできない
予測CSVファイルは一日5ファイルまでしかアップロードできないという制限がありました。
これがなければ上記の処理をループでひたすら回すということができて楽だったのですが。。。
ここは工夫する必要がありそうです。
自動化の流れ
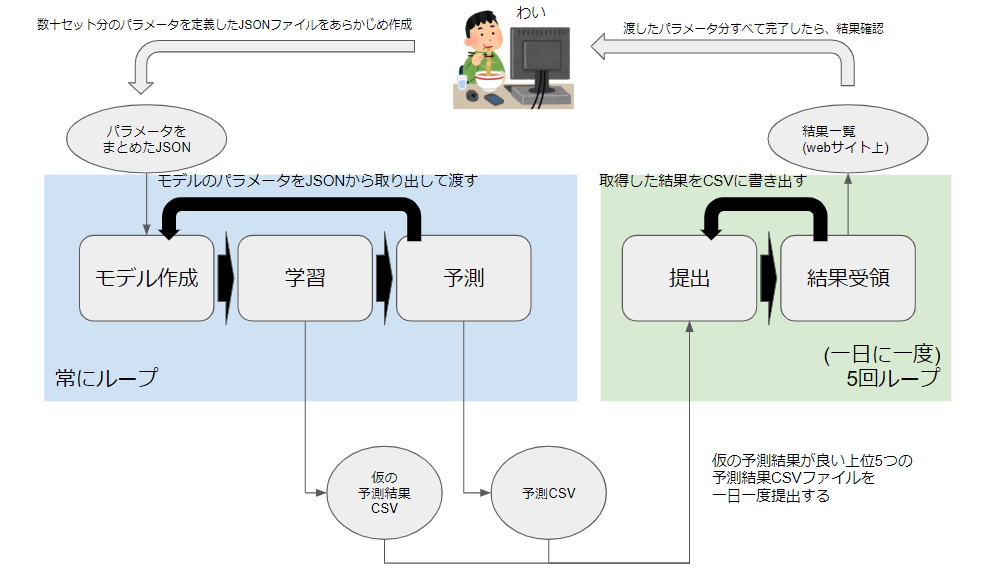
人間のやること
- JSONファイルにモデルに渡すパラメータを事前に数十/数百セット定義しておきます。
- 渡したパラメータ分すべて処理が終了するまで漫画とかyoutubeを見ます。
- すべて完了した後は結果を確認して、目標を達成していたら終了、結果をもとに次のパラメータを考える
Python君のやること
モデル作成/学習/予測
ここはひたすらループ処理になります。
- JSONファイルからモデルに使用するパラメータを取得
- モデル作成
- 学習(この時に算出される仮の予測精度をCSVに格納していく)
- 予測(1ループごとに1つの結果CSVが作成されます)
提出/結果受領
一日一回、深夜12時を超えたタイミングに5回だけループします。
5回というのは、一日の提出上限回数です。
- まず仮の予測結果が格納されているCSVを確認して、上位5つの予測CSVを抽出する
- 抽出したCSVを1ループずつ提出する
- アップロードに表示される予測結果を取得してCSVに書き込む
実装(コーディング)
その前に
さすがに研修会社さんのアップロードサイトについては公開することができないので、今回は代わりにkaggleのdigit recognizerを使用します。基本的な流れは変わりません。
またkaggleにはアップロード用のAPIがありますが、今回それについてはツッコまないように (-_-)
あくまでこれは再現としてみていただけると幸いです。
では実際に使用したコードについて簡単に説明します。
コード
機械学習クラス
from itertools import product
import os
import pandas as pd
import numpy as np
np.random.seed(2)
from keras.utils.np_utils import to_categorical # convert to one-hot-encoding
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from keras.optimizers import RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ReduceLROnPlateau
from sklearn.model_selection import train_test_split
class MnistModel(object):
def __init__(self, train_data_name='train.csv', test_data_csv='test.csv'):
input_dir = self.get_dir_path('input')
train_data_path = os.path.join(input_dir, train_data_name)
test_data_path = os.path.join(input_dir, test_data_csv)
#Load the data
self.train = pd.read_csv(train_data_path)
self.test = pd.read_csv(test_data_path)
def get_dir_path(self, dir_name):
""" Function to directory path
Params:
dir_name(str): The name of directory
Return:
str: The directory path
"""
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
data_directory = os.path.join(base_dir, dir_name)
return data_directory
def learning_and_predict(self, csv_file_path, config):
label = self.train["label"]
train = self.train.drop(labels=["label"], axis=1)
# Normalize the data
train = train / 255.0
test = self.test / 255.0
# Reshape image in 3 dimensions (height = 28px, width = 28px , canal = 1)
train = train.values.reshape(-1, 28, 28, 1)
test = test.values.reshape(-1, 28, 28, 1)
# Encode labels to one hot vectors (ex : 2 -> [0,0,1,0,0,0,0,0,0,0])
label = to_categorical(label, num_classes=10)
# Set the random seed
random_seed = 2
# Split the train and the validation set for the fitting
X_train, X_val, Y_train, Y_val = train_test_split(train, label, test_size=0.1, random_state=random_seed)
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same',
activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(filters=32, kernel_size=(5, 5), padding='Same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same',
activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='Same',
activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(10, activation="softmax"))
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=config['ROTATION_RANGE'], # randomly rotate images in the range (degrees, 0 to 180)
zoom_range=config['ZOOM_RANGE'], # Randomly zoom image
width_shift_range=config['WIDTH_SHIFT_RANGE'], # randomly shift images horizontally (fraction of total width)
height_shift_range=config['HEIGHT_SHIFT_RANGE'], # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
learning_rate_reduction = ReduceLROnPlateau(
monitor='val_acc',
patience=3,
verbose=1,
factor=0.5,
min_lr=0.00001
)
epochs = 1
batch_size = 86
history = model.fit_generator(
datagen.flow(
X_train,
Y_train,
batch_size=batch_size
),
epochs=epochs,
validation_data=(
X_val,
Y_val
),
verbose=2,
steps_per_epoch=X_train.shape[0] // batch_size,
callbacks=[learning_rate_reduction])
results = model.predict(test)
results = np.argmax(results, axis=1)
results = pd.Series(results, name="Label")
submission = pd.concat([pd.Series(range(1, 28001), name="ImageId"), results], axis=1)
submission.to_csv(csv_file_path, index=False)
return history.history['val_acc'][0]
今回の機械学習のモデルは以下を参考(丸パクリ)して作成しました。
https://www.kaggle.com/yassineghouzam/introduction-to-cnn-keras-0-997-top-6
learning_and_predictメソッドにてモデル作成/学習/予測をすべて行います。
configがパラメータを格納したリストになります。
datagen = ImageDataGenerator(
....
rotation_range=config['ROTATION_RANGE'], # randomly rotate images in the range (degrees, 0 to 180)
zoom_range=config['ZOOM_RANGE'], # Randomly zoom image
width_shift_range=config['WIDTH_SHIFT_RANGE'], # randomly shift images horizontally (fraction of total width)
height_shift_range=config['HEIGHT_SHIFT_RANGE'], # randomly shift images vertically (fraction of total height)
....
datagen.fit(X_train)
今回はImageDataGenerator(画像拡張)のパラメータをチューニングの対象にしています。
※なんのことかわからない人は、とりあえず機械学習モデルのパラメータの一つなんだと思っておいてください。
パラメータ定義JSON
{
"CONFIG": [
{
"ROTATION_RANGE": 10,
"ZOOM_RANGE": 0.1,
"WIDTH_SHIFT_RANGE": 0.1,
"HEIGHT_SHIFT_RANGE": 0.1
},
{
"ROTATION_RANGE": 10,
"ZOOM_RANGE": 0.1,
"WIDTH_SHIFT_RANGE": 0.1,
"HEIGHT_SHIFT_RANGE": 0.2
},
{
"ROTATION_RANGE": 10,
"ZOOM_RANGE": 0.1,
"WIDTH_SHIFT_RANGE": 0.1,
"HEIGHT_SHIFT_RANGE": 0.3
},
{
"ROTATION_RANGE": 10,
"ZOOM_RANGE": 0.1,
"WIDTH_SHIFT_RANGE": 0.1,
"HEIGHT_SHIFT_RANGE": 0.4
}
]
}
webアップロード用クラス
予測CSVをwebサイトにアップロードするためのクラスになります。
主にseleniumにて実装されています。
import os
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
DRIVER_FILE_PATH = 'C:\Drivers\chromedriver_win32\chromedriver.exe'
DRIVER_FILE_NAME = 'chromedriver'
TIMEOUT = 30
class BaseBrowserOperator(object):
""" Base model of browser operator """
def __init__(self, headless = False):
driver_path = os.path.join(os.path.dirname(DRIVER_FILE_PATH), DRIVER_FILE_NAME)
if headless == True:
options = webdriver.ChromeOptions()
options.add_argument('--headless')
self.browser = webdriver.Chrome(driver_path, options=options)
else:
self.browser = webdriver.Chrome(driver_path)
def __del__(self):
self.browser.close()
class BrowserOperator(BaseBrowserOperator):
""" The browser operator model """
def go_to_page(self, url):
""" Function to go to a page
Params:
url(str): The url of page
"""
self.browser.get(url)
def click(self, element_xpath, wait=True):
""" Function to click the page's element
TODO:
implement finding element method other than xpath
Params:
element_xpath(str): The xpath of element be clicked
wait(boolean): If disable waiting, please give False.
"""
if wait:
self.wait_element(element_xpath)
self.browser.find_element_by_xpath(element_xpath).click()
def input_value(self, element_xpath, value, wait=True):
""" Function to input value to page's element
TODO:
implement finding element method other than xpath
Params:
element_xpath(str): The xpath of element be clicked
value(str): The value be inputed
wait(boolean): If disable waiting, please give False.
"""
if wait:
self.wait_element(element_xpath)
self.browser.find_element_by_xpath(element_xpath).send_keys(value)
def get_value(self, element_xpath, wait=True):
""" Function to get value from page's element
Params:
element_xpath(str): The xpath of element be clicked
wait(boolean): If disable waiting, please give False.
Returns:
str: Value from page's element
"""
if wait:
self.wait_element(element_xpath)
return self.browser.find_element_by_xpath(element_xpath).text
def import_cookies(self):
""" Function to import cookie informations """
cookies = self.browser.get_cookies()
for cookie in cookies:
self.browser.add_cookie({
'name': cookie['name'],
'value': cookie['value'],
'domain': cookie['domain'],
})
def wait_element(self, element_xpath):
""" Function to wait to appear element on page
TODO:
implement finding element method other than xpath
Params:
element_xpath(str): The xpath of element be used to wait
"""
WebDriverWait(self.browser, TIMEOUT).until(EC.element_to_be_clickable((By.XPATH, element_xpath)))
def wait_value(self, element_xpath, value, timeout=300):
""" Function to wait until element's value equal the specific value
Params:
element_xpath(str): The xpath of element be used for wait
value(str): The used value for wait
timeout(int): The waiting timeout(sec)
"""
state = ''
sec = 0
while not state == value:
state = self.browser.find_element_by_xpath(element_xpath).text
time.sleep(1)
if sec > timeout:
raise TimeoutError("Timeout!! The value wasn't available")
sec += 1
各メソッドは以下のように使用します。
- go_to_page
- 指定のURLに遷移するためのメソッドです。
- click
- webページの要素をクリックするためのメソッドです。
- waitを使用することで、要素がクリックできる状態になるまで待機することができます
- input_value
- webページの入力欄に、文字を入力するためのメソッドです。
- waitを使用することで、要素がクリックできる状態になるまで待機することができます
- get_value
- webページの要素から値を取得するメソッドです。
- waitを使用することで、要素がクリックできる状態になるまで待機することができます
- import_cookies
- cookieをインポートします
kaggleにて予測CSVファイルのアップロードは以下のコードで実現できます。
def upload_csv_to_kaggle(self, file_path):
""" Function to upload csv file to kaggle
Params:
file_path(str): The path of csv file uploaded
"""
uploader = BrowserOperator()
# kaggleのページに遷移
uploader.go_to_page(
'https://www.kaggle.com/c/digit-recognizer'
)
# Sign inボタンをクリック
uploader.click(
'/html/body/main/div[1]/div/div[1]/div[2]/div[2]/div[1]/a/div/button'
)
# Sign in with google をクリック
uploader.click(
'/html/body/main/div/div[1]/div/form/div[2]/div/div[1]/a/li/span'
)
# メールアドレスを入力
uploader.input_value(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div/div[1]/div/div[1]/input',
GOOGLE_MAILADDRESS
)
uploader.click(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div'
)
# パスワードを入力
uploader.input_value(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div[1]/div/div/div/div/div[1]/div/div[1]/input',
GOOGLE_PASSWORD
)
uploader.click(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/span/span'
)
time.sleep(10) # sleepいれないとうまくいかんなかった
# クッキーをインポート
uploader.import_cookies()
# digit recognizerのCSV提出画面に遷移
uploader.go_to_page('https://www.kaggle.com/c/digit-recognizer/submit')
time.sleep(30) # sleepいれないとうまくいかんなかった
# ファイルアップロード
uploader.input_value(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/div/input',
file_path,
wait=False
)
# コメントの入力
uploader.input_value(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[2]/div[2]/div/div/div/div[2]/div/div/textarea',
'test'
)
uploader.wait_element(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/ul/li/div/span[1]')
uploader.click('/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[3]/div[2]/div/a')
uploader.wait_value(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[2]/div[2]/div/div[3]/div[1]/div[1]/span',
'Complete'
)
課題実行用クラス
import csv
import datetime
import json
import os
import time
import retrying
from mnist_auto.models.operator import BrowserOperator
from mnist_auto.models.ai import MnistModel
DEFAULT_DAILY_SCORES_DIR = 'daily_scores'
DEFAULT_CSVS_DIR = 'results'
DEFAULT_UPLOADED_SCORE_FILE_NAME = 'uploaded_score.csv'
DEFAULT_KAGGLE_DAILY_LIMIT = 5
COLUMN_DATETIME = 'DATETIME'
COLUMN_SCORE = 'SCORE'
GOOGLE_MAILADDRESS = 'xxxx@google.com'
GOOGLE_PASSWORD = 'password'
class BaseHomeworker(object):
""" Base model of homeworker """
def __init__(self, daily_score_dir_name, csvs_dir_name):
self.daily_score_dir_path = self.get_dir_path(daily_score_dir_name)
self.csvs_dir_path = self.get_dir_path(csvs_dir_name)
def get_dir_path(self, dir_name):
""" Function to get directory path
if direcotry doen't exist, The direcotry will be made
Params:
dir_name(str): The directory name
Returns:
str: The directory path
"""
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
dir_path = os.path.join(base_dir, dir_name)
if not os.path.exists(dir_path):
os.mkdir(dir_path)
return dir_path
class Homeworker(BaseHomeworker):
""" The homeworker model """
def __init__(self):
super().__init__(daily_score_dir_name=DEFAULT_DAILY_SCORES_DIR, csvs_dir_name=DEFAULT_CSVS_DIR)
self.uploaded_scores = []
self.config = self.get_confing()
self.mnist_model = MnistModel()
def get_confing(self, config_file_name='config.json'):
""" Function to get configuration with json format
Params:
config_file_name(str): The name of config file
Return:
dict: The dict including config
"""
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
config_file_path = os.path.join(base_dir, config_file_name)
json_file = open(config_file_path, 'r')
return json.load(json_file)
def write_daily_to_file(self, date_ymd, date_ymdhm, score):
""" Function to write daily data to file
Params:
date_ymd(str): The formatted date (YYYYmmdd)
date_ymdhm(str): The formatted date (YYYYmmddHHMM)
score(int): The score
"""
date_ymd = date_ymd + '.csv'
file_path = os.path.join(self.daily_score_dir_path, date_ymd)
with open(file_path, 'a', newline='') as csv_file:
fieldnames = [COLUMN_DATETIME, COLUMN_SCORE]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writerow({
COLUMN_DATETIME: date_ymdhm,
COLUMN_SCORE: score
})
def upload_csv_files(self, date_ymd, num=DEFAULT_KAGGLE_DAILY_LIMIT):
""" Function to upload designated number csv files
Params:
data_ymd(str): The formatted data
num(int): The number of file that will be uploaded
"""
targets_uploaded = self.get_tops(date_ymd, num)
for target in targets_uploaded:
file_path = os.path.join(self.daily_score_dir_path, target[COLUMN_DATETIME]) + '.csv'
try:
self.upload_csv_to_kaggle(file_path)
except retrying.RetryError:
continue
def get_tops(self, date_ymd, num):
""" Function to get data that have some high score from daily data
Params:
num(int): The number of data that will be gotten
Return:
list: The list that includes some highest data
"""
file_name = date_ymd + '.csv'
file_path = os.path.join(self.daily_score_dir_path, file_name)
scores = []
with open(file_path, 'r') as csv_file:
reader = csv.reader(csv_file)
for row in reader:
scores.append({
COLUMN_DATETIME: row[0],
COLUMN_SCORE: row[1]
})
sorted_list = sorted(scores, key=lambda x: x[COLUMN_SCORE], reverse=True)
if len(sorted_list) < num:
num = len(sorted_list)
return sorted_list[:num]
@retrying.retry(stop_max_attempt_number=3)
def upload_csv_to_kaggle(self, file_path):
""" Function to upload csv file to kaggle
Params:
file_path(str): The path of csv file uploaded
"""
uploader = BrowserOperator()
uploader.go_to_page(
'https://www.kaggle.com/c/digit-recognizer'
)
uploader.click(
'/html/body/main/div[1]/div/div[1]/div[2]/div[2]/div[1]/a/div/button'
)
uploader.click(
'/html/body/main/div/div[1]/div/form/div[2]/div/div[1]/a/li/span'
)
uploader.input_value(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div/div[1]/div/div[1]/input',
GOOGLE_MAILADDRESS
)
uploader.click(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div'
)
uploader.input_value(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[1]/div/form/span/section/div/div/div[1]/div[1]/div/div/div/div/div[1]/div/div[1]/input',
GOOGLE_PASSWORD
)
uploader.click(
'/html/body/div[1]/div[1]/div[2]/div/div[2]/div/div/div[2]/div/div[2]/div/div[1]/div/span/span'
)
time.sleep(10)
uploader.import_cookies()
uploader.go_to_page('https://www.kaggle.com/c/digit-recognizer/submit')
time.sleep(30)
uploader.input_value(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/div/input',
file_path,
wait=False
)
uploader.input_value(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[2]/div[2]/div/div/div/div[2]/div/div/textarea',
'test'
)
uploader.wait_element(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/div[1]/ul/li/div/span[1]')
uploader.click('/html/body/main/div[1]/div/div[5]/div[2]/div/div[3]/div[2]/div[2]/div[3]/div[2]/div/a')
uploader.wait_value(
'/html/body/main/div[1]/div/div[5]/div[2]/div/div[2]/div[2]/div/div[3]/div[1]/div[1]/span',
'Complete'
)
def work(self):
""" Function to run a series of tasks
1. learning and prediction with parameter (It's written on json)
one prediction results is outputed as one csv
2. Writing learning's score (acc) to another csv.
3. Once a day, uploading result csv files to kaggle in high score order
"""
last_upload_time = datetime.datetime.now()
for config in self.config['CONFIG']:
now = datetime.datetime.now()
now_format_ymdhm = '{0:%Y%m%d%H%M}'.format(now)
now_format_ymd = '{0:%Y%m%d}'.format(now)
if (now - last_upload_time).days > 0:
last_upload_time = now
self.upload_csv_files()
csv_file_name = now_format_ymdhm + '.csv'
csv_file_path = os.path.join(self.csvs_dir_path, csv_file_name)
score = self.mnist_model.learning_and_predict(csv_file_path=csv_file_path, config=config)
self.write_daily_to_file(date_ymd=now_format_ymd, date_ymdhm=now_format_ymdhm, score=score)
workメソッドがメインとなる部分です。
結果発表
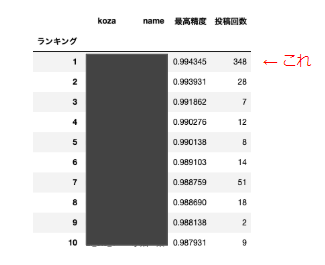
ほとんど寝てるだけで、課題をパスすることができました!
各研修受講生のアップロードした回数が表示されるのですが、私だけ桁違いでしたw
みなさんも退屈なことはPythonにやらせましょう!!では!