背景
仕事をしているとき、業務に関係ない情報を閲覧していることって誰でもありますよね?
そんなときに背後にボスが忍び寄っていると気まずい思いをします。もちろん急いで画面を切り替えれば良いのですが、そういう動作は逆に怪しまれることになりますし、集中しているときは気がつかないこともあります。そこで怪しまれずに画面を切り替えるために、ボスが近づいてきたことを自動的に認識して画面を隠すシステムを作ってみました。
具体的にはKerasを用いてボスの顔を機械学習し、カメラを用いて近づいてきたことを認識して画面を切り替えています。
ミッション
ミッションはボスが近づいてきたら自動的に画面を切り替えることです。
状況は以下のような感じです。
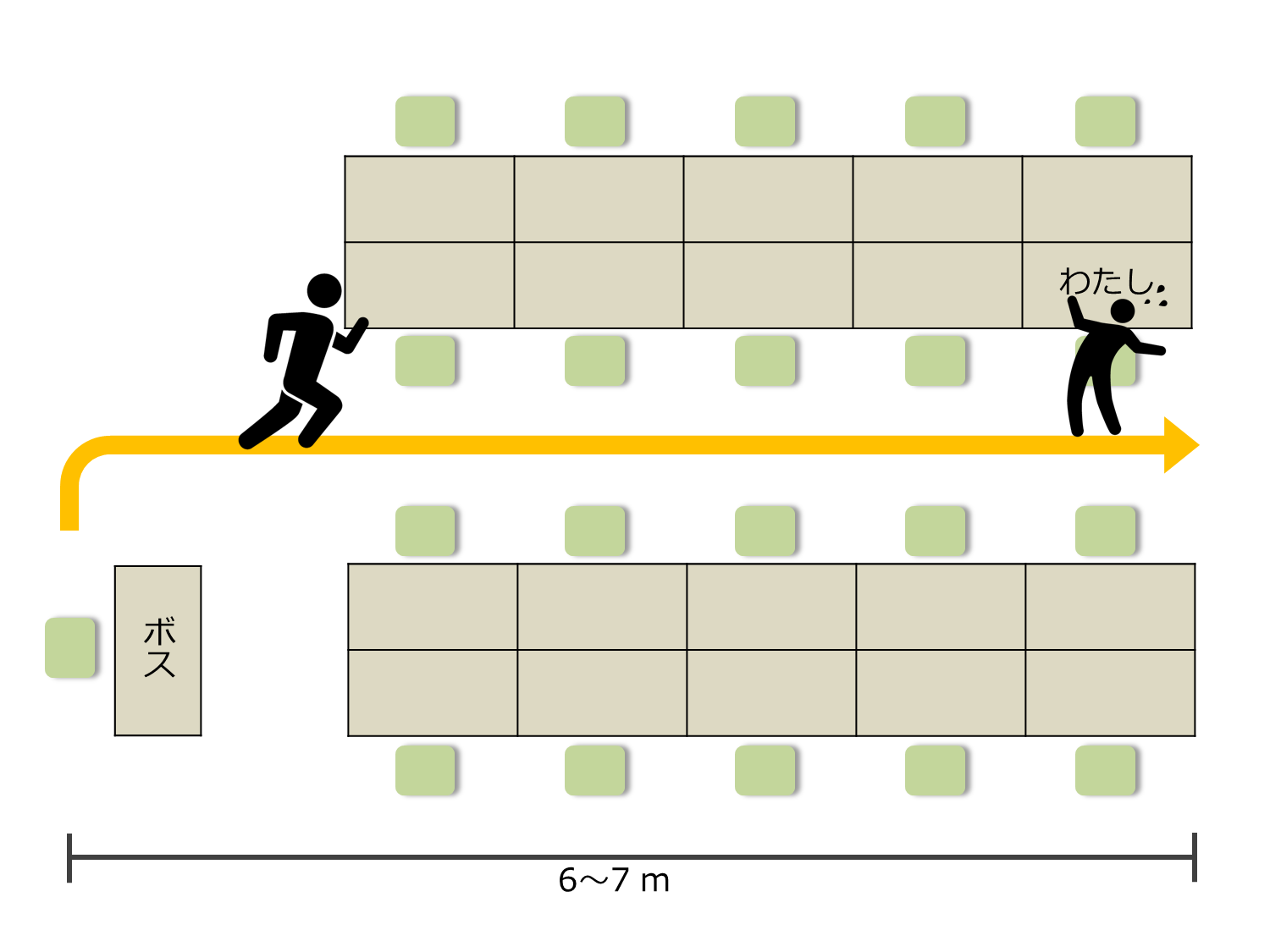
ボスの席から私の席まではだいたい6,7mくらいです。ボスが席をたってから、4,5秒で私の席に到達します。したがって、この間に画面を隠す必要があるわけです。時間的余裕はあまりありません。
戦略 〜如何にして画面を隠すか?〜
さまざまな戦略が考えられると思いますが、私の考えた戦略はこうです。
まず、機械学習を使ってコンピュータにあらかじめボスの顔を学習させておきます。そして、自席にWebカメラを設置し、Webカメラがボスの顔を捉えたら画面を切り替えます。完璧な戦略です。このすばらしいシステムのことを「ボスセンサ」と名付けましょう。
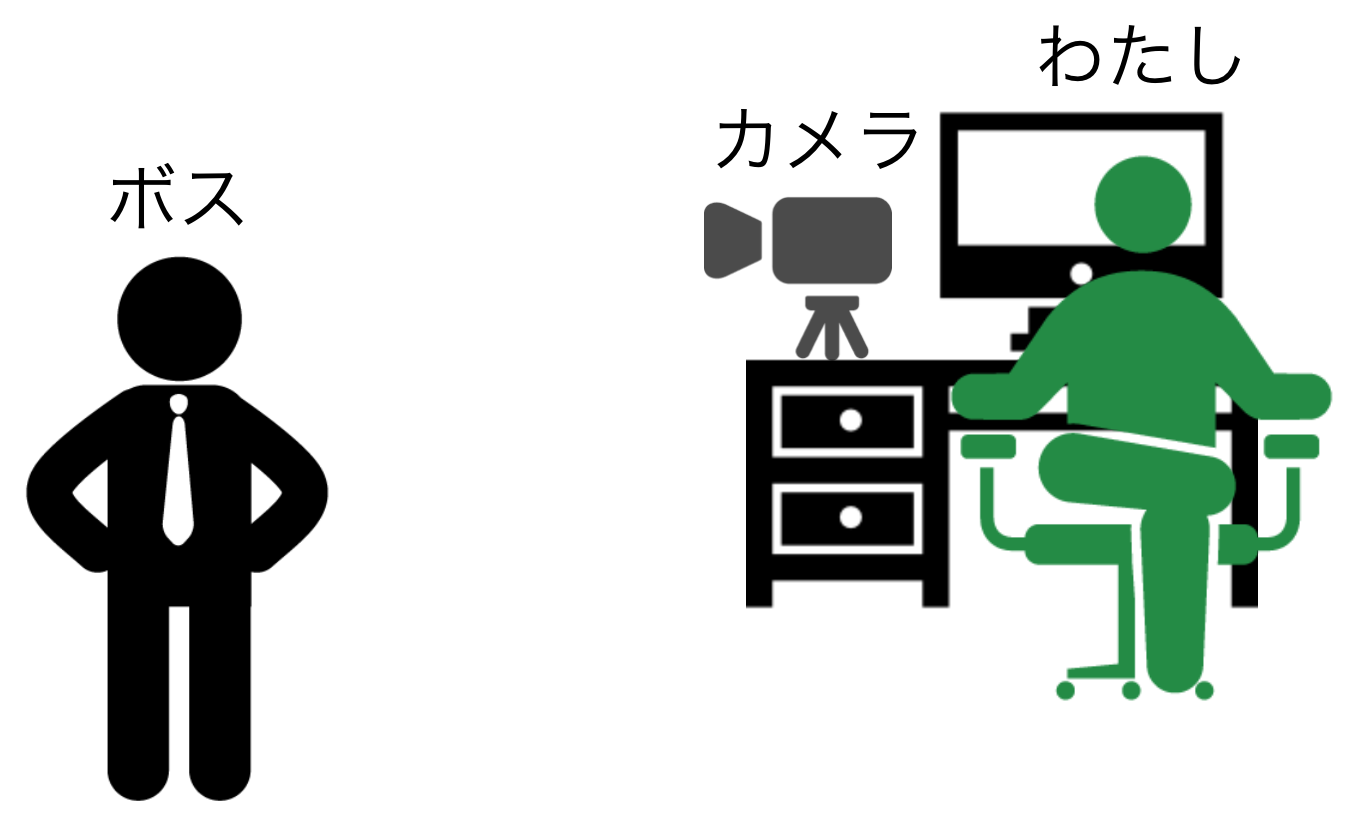
ボスセンサのシステム構成
ボスセンサの超簡単なシステム構成は以下の通りです。
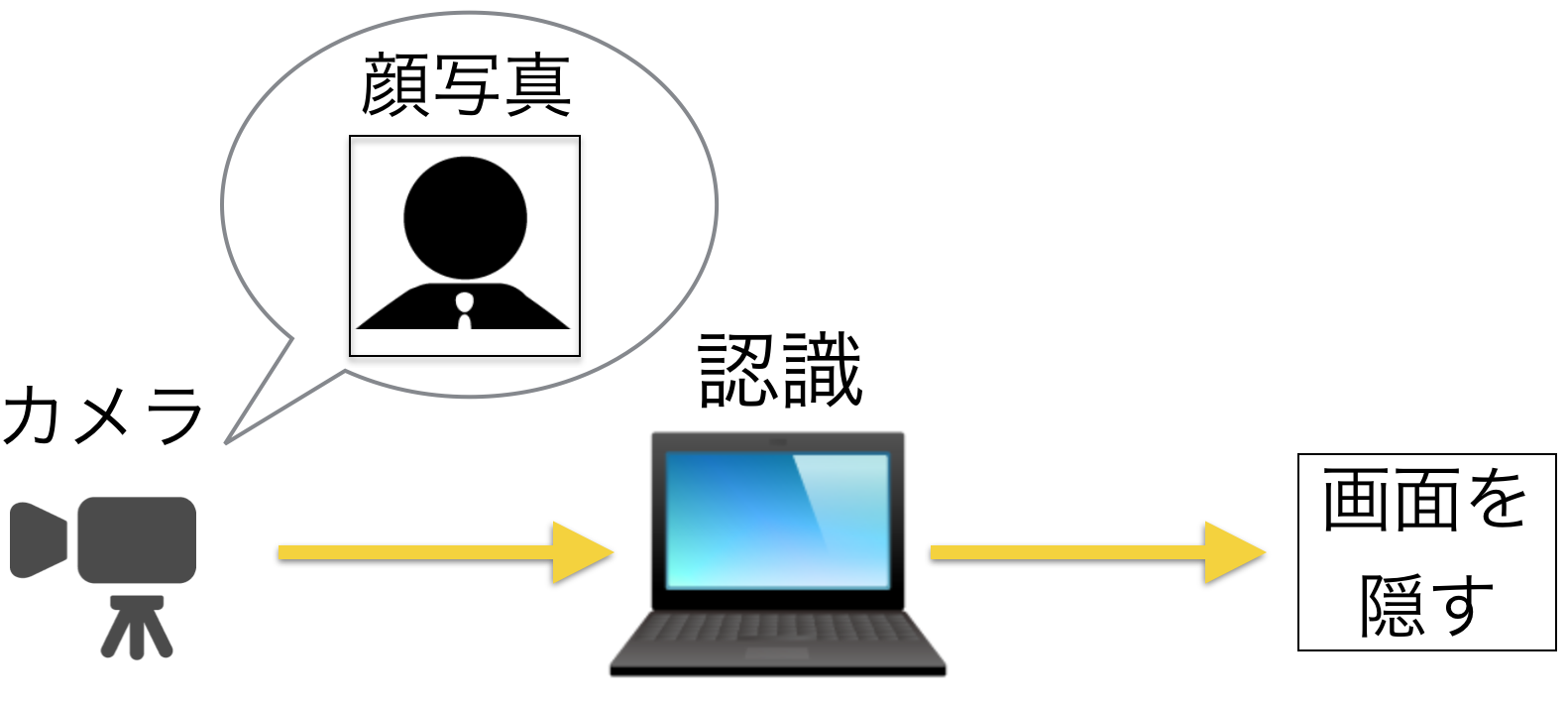
- Webカメラを使ってリアルタイムに画像を取得します。
- 取得した画像に対して学習モデルを用いて顔検知&顔認識を行います。
- 認識結果がボスだったら画面を切り替えます。
これらを行うために以下の技術が必要になります:
- 顔画像の取得
- 顔画像の認識
- 画面の切り替え
それでは一つずつ検証し、最後に統合しましょう。
顔画像の取得
まずはWebカメラから画像を取得します。
今回使用するWebカメラはBUFFALOのBSW20KM11BKです。

Webカメラはある程度の性能があればなんでも良いと思います。
カメラから画像を取得するのは付属のソフトでもできますが、後の処理の事を考えるとプログラムから取得できた方がいいです。また、このあとの処理で顔認識を行うので顔画像だけを切り出す必要があります。というわけで、PythonとOpenCVを使って顔画像を取得することにします。そのためのコードがこちら:
思っていたよりきれいに顔画像を取得することができました。

ボスの顔の学習と認識
次に、機械学習を使ってコンピュータにボスの顔を認識できるようにします。
以下の3点がざっくりとした手順です:
- 画像の収集
- 画像の加工
- 機械学習モデルの構築
これらについても一つずつ見ていきましょう。
画像の収集
まずは、学習用の画像を入手する必要があります。収集方法としては以下のような方法を使いました:
- Google画像検索
- Facebookで画像収集
- カメラで撮影
最初はWeb検索とFacebookから画像を収集したのですが、十分な数の画像が集まりませんでした。そのため、ビデオカメラを使って動画を撮影し、動画を画像に分解するということを行いました。
画像の加工
さて、顔が写った画像は大量に取得できましたが、このままでは学習器にかけられません。顔と関係のない部分が画像のかなりの部分を占めているからです。そこで顔画像だけを切り出してあげます。
切り出しには主にImageMagickを使いました。ImageMagickを使って切り出すことで顔画像だけを手に入れることができます。
こんな感じで大量の顔画像が集まりました:

おそらく私は世界で最も上司の顔画像を所持している人間でしょう。親より持っているに違いない。
これで学習のための準備はできました。
機械学習モデルの構築
学習はKerasで畳み込みニューラルネットワーク(CNN)を構築して行います。KerasのバックエンドにはTensorFlowを使用しています。顔認識するだけなら画像認識のWeb APIを叩いてもできますが、今回はリアルタイム性を考慮して自分で作ることにしました。
ネットワークは以下のような構成にしています。Kerasだと構成を簡単に出力できるので便利です。
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
convolution2d_1 (Convolution2D) (None, 32, 64, 64) 896 convolution2d_input_1[0][0]
____________________________________________________________________________________________________
activation_1 (Activation) (None, 32, 64, 64) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 32, 62, 62) 9248 activation_1[0][0]
____________________________________________________________________________________________________
activation_2 (Activation) (None, 32, 62, 62) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
maxpooling2d_1 (MaxPooling2D) (None, 32, 31, 31) 0 activation_2[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 32, 31, 31) 0 maxpooling2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 64, 31, 31) 18496 dropout_1[0][0]
____________________________________________________________________________________________________
activation_3 (Activation) (None, 64, 31, 31) 0 convolution2d_3[0][0]
____________________________________________________________________________________________________
convolution2d_4 (Convolution2D) (None, 64, 29, 29) 36928 activation_3[0][0]
____________________________________________________________________________________________________
activation_4 (Activation) (None, 64, 29, 29) 0 convolution2d_4[0][0]
____________________________________________________________________________________________________
maxpooling2d_2 (MaxPooling2D) (None, 64, 14, 14) 0 activation_4[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 64, 14, 14) 0 maxpooling2d_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 12544) 0 dropout_2[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 6423040 flatten_1[0][0]
____________________________________________________________________________________________________
activation_5 (Activation) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
dropout_3 (Dropout) (None, 512) 0 activation_5[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 1026 dropout_3[0][0]
____________________________________________________________________________________________________
activation_6 (Activation) (None, 2) 0 dense_2[0][0]
====================================================================================================
Total params: 6489634
そのコードがこちら:
ここまでできるとカメラにボスが映った時にボスだと認識することができます。
画面の切り替え
さて、学習したモデルを使ってボスの顔を認識したら画面を切り替える必要があります。今回はシンプルに、仕事してる風の画像を用意して表示することにしましょう。
私はプログラマなので以下の画像を用意しました。
いかにも仕事をしている風です。あとはこの画像を表示してやるだけです。
画像はフルスクリーンで表示したいので、PyQtを使って表示することにします。そのためのコードがこちら:
さぁ、これですべての準備が整いました。
完成
これまでに検証した技術を統合したら完成です。実際に試してみました。
「ボスが席を立ちました。私の席に近づいてきます。」

「OpenCVが顔検知をしました。画像を学習モデルに投げます。」

「無事、ボスだと認識して画面が切り替わりました。ヽ(‘ ∇‘ )ノ ワーイ」
反省
自戒を込めて。
テストセットの画像に対しては高い精度なのに、Webカメラで取得した画像はなかなか認識できないことがありました。光の当たり具合だとか画像のブレが関係していたようです。きちんと画像の正規化とかしないといけないんだなぁー。
分類がボスか別の人かの2値分類だったが、顔画像以外の画像を入力した時に、ボスに分類されることがあった。どちらかといえばボスだよねーということだったのだろう。2値分類より、ボスである確率を使って認識した方がよかったかもしれない。
画像処理難しい。
ソースコード
以下のリポジトリからソースコードをダウンロードできます。
おわりに
今回はWebカメラからリアルタイムの画像取得とKerasを用いた顔認識を組み合わせることで、上司を認識して画面を隠してみました。
現在はOpenCVで顔検知をしていますが、OpenCVでの顔検知の精度がいまいちな気がするので、Dlib使ったりしてその辺りを改善してみたいと考えています。自分で訓練した顔検出モデルを使ったりしてみたい。
あと仕事している風画像の表示にPyQt使っていたんですが、命令してから表示されるまでに結構時間がかかるので、その辺りの改善が必要になります。
Webカメラから取得した画像の認識精度がいまいちなので、ちょこちょこと改善していきたいと思います。
現実は甘くはなかった