はじめに
先日 TensorFlow 0.12 がリリースされました。
その機能の一つとして、埋め込み表現の可視化があります。これにより高次元のデータをインタラクティブに分析することが可能になります。
以下は MNIST を可視化したものです。以下の画像は静止画ですが、公式サイトでは3次元でぬるぬる動いているところを見ることができます。

本記事ではWord2vecの可視化を通じて、Embedding Visualization の使い方を試してみました。まずはインストールから行っていきます。
インストール
まずは TensorFlow 0.12 をインストールします。以下のページを参考にインストールしてください。
インストールが終わったら可視化のために学習を行います。
モデルを学習する
まずはリポジトリをクローンした後、以下のコマンドを実行して移動します:
$ git clone https://github.com/tensorflow/tensorflow.git
$ cd tensorflow/models/embedding
学習データと評価データをダウンロードするために以下のコマンドを実行します:
$ wget http://mattmahoney.net/dc/text8.zip -O text8.zip
$ unzip text8.zip
$ wget https://storage.googleapis.com/google-code-archive-source/v2/code.google.com/word2vec/source-archive.zip
$ unzip -p source-archive.zip word2vec/trunk/questions-words.txt > questions-words.txt
$ rm source-archive.zip
データが用意できたので単語ベクトルを学習します。以下のコマンドを実行してください:
$ python word2vec_optimized.py --train_data=text8 --eval_data=questions-words.txt --save_path=/tmp/
学習には1時間くらいかかるのでお待ちください。
TensorBoard で Embedding を表示する
学習が終わったら表示を行います。まずは以下のコマンドを実行して TensorBoard を起動してください:
$ tensorboard --logdir=/tmp/
起動したら、指定されたアドレスにアクセスします。その後 Embedding タブを選択すると可視化されたベクトルが表示されます。
ちなみにWord2vecの可視化を行ったら、ボキャブラリ数が多すぎてわけがわからないことになりました。

Metadataを使うと単語IDではなく単語そのものを表示できるようになるみたいです。
もし何も表示されなかったら
Embedding タブを選択した際にブラウザに何も表示されず、コンソールに以下のようなエラーが出ることがあります。というか出ました。
File "/Users/user_name/venv/lib/python3.4/site-packages/tensorflow/tensorboard/plugins/projector/plugin.py", line 139, in configs
run_path_pairs.append(('.', self.logdir))
AttributeError: 'dict_items' object has no attribute 'append'
その場合、インストールしたTensorFlowのtensorflow/tensorboard/plugins/projector/plugin.pyの139行目を以下のように変更してください。その後、TensorBoard を再実行します。
- run_path_pairs.append(('.', self.logdir))
+ run_path_pairs = [('.', self.logdir)]
いろいろいじってみる
あるノード(単語)を選択した後、「isolate 101 points」を選択したら以下のように表示されました。

これは選択した単語に類似した100単語を表示していることになります。ここで類似度を測るためには、コサイン類似度、ユークリッド距離を使うことができます。また、neighborsを指定することで、表示する単語数を増減させることができます。
可視化のためのアルゴリズムも複数使うことができます。
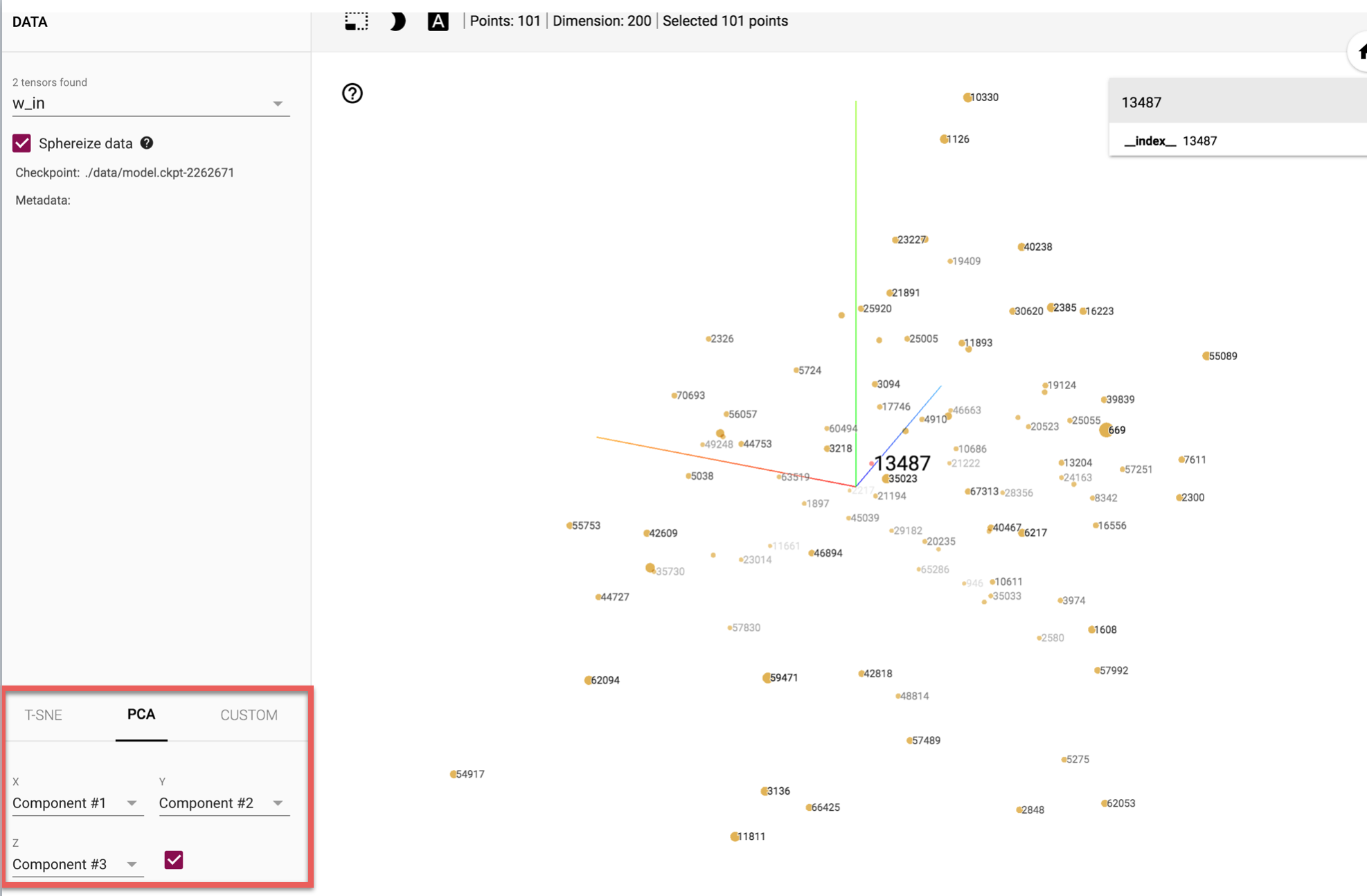
デフォルトではPCAですが、T-SNEやCUSTOMも使うことができます。画像では3次元表示していますが、2次元表示を行うこともできます。
おわりに
ラベルとして単語を割り当てられるともっと面白くなりそうです。今回は取り急ぎこんな感じの紹介に留めておきます。