この記事はDeep Learning FrameworkのCaffeに関する中身どうなってんのか、どういう仕組みなの?的なことを調べていた時のメモです。インストールして実行してみようみたいな記事は素晴らしいものがいくつもあるのでそちらを参考にしてください。
まだ、始めたばかりなので随時更新していきます。
## 概要
- CaffeはConvolutional Architecture for Fast Feature Embeddingの略
- 前身は DeCAF (Deep Convolutional Activation Feature)
- Open SourceのDeepLearning Frameworkの一つ
- UC BerkeleyのBerkeley Vision Learning Centerを中心に開発されている
## 特徴
#### 画像認識が得意
OpenCVなどの依存ライブラリなどもあり、画像認識に特化している
自前の学習モデルを定義するに当たって、データベース作成用の簡単なスクリプトが用意されていることで画像認識において使いやすい
#### C++実装、GPUをシームレスに使い分けて高速な実行
後述しますが、Caffeのネットワークを流れるデータはBlobクラスとして定義されており、このBlobクラスのdataのパラメータがSyncedMemory class objectであり、このSyncedMemory class objectによってGPU、CPU間の通信を必要に応じてよおし何やってくれる仕組みになっている
#### PythonとMatlabからも使える
OptionalですがPythonやMatLabのインターフェースでCaffeを動かすためのパッケージが用意されています、 pycaffeとか調べると出てきますが、setupに当たっての参考記事も最後に一応載せておきました
#### Configrationファイルだけで動かせる
ビルドしてCaffeバイナリを作り、そのバイナリコマンドを用いて、Network定義ファイルや、モデルの損失を小さくし、最適化を行うためのモデルをどのように学習するのか設定するSolverファイルをオプションで指定することで、Caffeを動かすことができます
#### Model Zoo
多くの学習済みネットワーク、研究結果がModel Zooで公開されており、GitHub Gistでダウンロードできる(Caffe内のダウンロード専用のスクリプトを使う)
https://github.com/BVLC/caffe/wiki/Model-Zoo
## 他のフレームワークとの比較
| Framework名 | Caffe | Torch | TensorFlow | Theano | Chainer |
|---|---|---|---|---|---|
| インターフェース | C++/Python/MatLab | Lua | C++/Python | Python | Python |
| 開発元 | BVLC | Montreal Univ. | PFI/PFN | ||
| 特徴 | 画像認識向き 転移学習 配布モデル RNNは面倒 新しいレイヤーの開発は手間 |
深層学習だけじゃない スケーラブル、ただし小規模では遅め Kerasなどラッパー |
計算グラフの元祖 RNNも容易 Keras, Lasagneなどのラッパー |
深層学習だけじゃない スケーラブル、ただし小規模では遅め Kerasなどラッパー |
使いやすいPythonコード 動作は遅め ユーザーはほぼ日本 |
- cite
- https://www.slideshare.net/KotaYamaguchi1/caffe-71288204
- refer
- http://qiita.com/jintaka1989/items/bfcf9cc9b0c2f597d419
## 動作原理
#### Prototxt
プロトテキスト(prototxt)とは、ニューラルネットの構造を記述するためのCaffe独自のテキスト形式です。 また、prototxt自体、Googleが開発したデータ構造を記述するためのテキスト形式の一種であるProtobufの文法に基づいたもので、例えばPyCaffeには、このprototxtをPython上から自動生成する機能が備わっている。
- cite
- http://li.nu/blog/2016/03/handwritten-number-classification-with-caffe-part3.html
Caffeでは
.prototxt形式(plaintext protocol buffer schema)の書式に従って各レイヤーの設定やパラメター(学習したWeightなど)記述している。これにより、テキストによる設定ファイルの読み書き、学習したパラメタの保存・転送などのをすべてprotocol bufferにまかせている。さらに protocol bufferは自動で設定項目に対してインターフェースを備えたクラスを生成(Java, Python, C++)をし、プログラムから扱いやすいようになっているらしい。
protobufの定義はすべてsrc/caffe/proto/caffe.protoに定義されている。 各レイヤーの設定だけではなく、BlobやDatumなどファイルに書き出したいようなものはすべてprotobufとして定義してある。
要は、このprototxtでネットワーク構成とかオプションとかいろいろ書くと、プログラムで読み込んでもらえていい感じに反映される
// DEPRECATED: use LayerParameter.
message V1LayerParameter {
repeated string bottom = 2;
//省略
enum LayerType {
//省略
CONTRASTIVE_LOSS = 37;
CONVOLUTION = 4;
//省略
IM2COL = 11;
IMAGE_DATA = 12;
//省略
POOLING = 17;
//省略
RELU = 18;
//省略
}
//省略
このParameterプロトコルなどはParameterのblobは含まれないので別途レイヤーのクラスでハンドリングしている。
- cite
- http://tnarihi.github.io/machine%20learning/2014/12/10/CAFFE-Layer/
#### Net
Caffeのネットワークは以下の図に示すblobとlayerの二種類から成り立っている。blobはCNNのデータを格納するデータ構造であり、layerは畳み込みやpooling,全結合などの単位ごとの操作単位の事。
Netはlayer同士を並べてつなぐことで、ニューラルネットワークを定義している。このつなぎ方において、直列につなぐのみならず、blobを用いることで一部並列につなげることなども可能になっており、有向非循環グラフ(DAG)として構成する。これによってGoogleNetのような複雑なフラフを表現できるが、RNNなどの循環をもつものはNetとしては表現せず、RNNの循環部分をLayerとして記述する(らしい)
template <typename Dtype>
Net<Dtype>::Net(const string& param_file, Phase phase,
const int level, const vector<string>* stages) {
NetParameter param;
ReadNetParamsFromTextFileOrDie(param_file, ¶m);
// Set phase, stages and level
param.mutable_state()->set_phase(phase);
if (stages != NULL) {
for (int i = 0; i < stages->size(); i++) {
param.mutable_state()->add_stage((*stages)[i]);
}
}
param.mutable_state()->set_level(level);
Init(param); // <- Networkの初期化関数
}
net.cppのコンストラクタ内部で呼ばれるInit()でネットワークの初期化を行ってるぽい。初期化は主として以下のことを行なう。
- blobとlayerを作成して全体のDAGをスキャフォールディング(足場材料を組み立て)し(Netはblobとlayerの所有権を保持する)、layerの
SetUp()関数を呼び出す - ネットワークアーキテクチャ全体の正当性の検証など
- 最後あたりで
ShareWeights()とかいうのをしていてparameterのdata及びdiffのshareをする
#### Layer
ネットワークにおける基本単位。Networkの一層分の処理を一つのLayerが担当する。このLayerをつなげていくことでNetworkを構築する。Layer::SetUp()関数の中身は以下のようになっている
void SetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
CheckBlobCounts(bottom, top); //bottomおよびtopのblobの数が正しいことをチェック
LayerSetUp(bottom, top); //個々のレイヤータイプに対して特別なレイヤー設定を行う
Reshape(bottom, top); //top blobと内部バッファのサイズを設定
SetLossWeights(top); //損失ウェイトを各レイヤーのtopに対して設定
}
Layerは以下の図のように後述するblobを受け取り、この入力を用いてLayer内部での処理を行った後、処理結果としてblobを出力する。入力するblobをbottom、出力するblobをtopとして定義する。
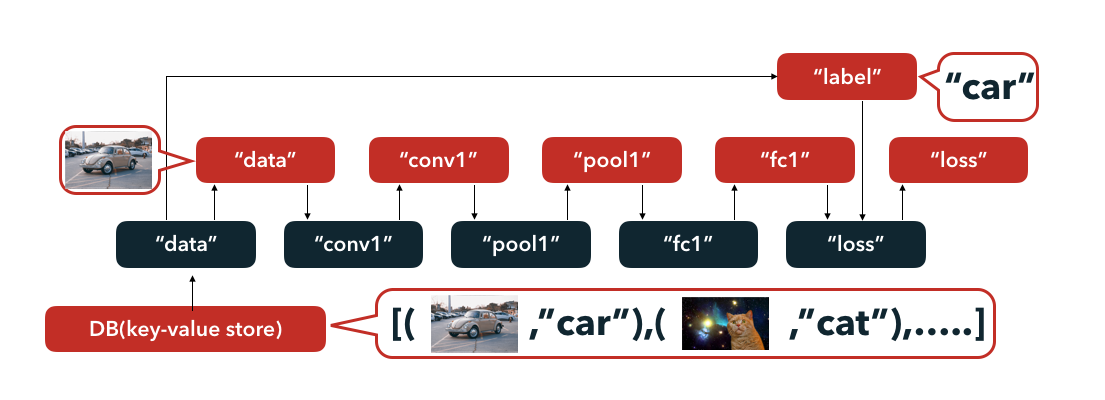
例えば、conv1 Layerでは"data"がbottomのblobであり、"conv1"がtopのblobである。
このLayerには様々な種類があり、独自に定義することも可能(その場合かなり大変)
LayerParameterというmessageがあり、すべてのLayerの設定を記述できる形になっている。変数にCONVOLUTION=4, POOLING=17,などすべての設定を持っている。
コンストラクタで基本的にprototxtで定義したパラメータとかを読み取る。
レイヤーで重要な処理は主に以下の三つである
- Setup : 層とその接続をモデル初期化時に一度だけ初期化
- Forward : bottomから入力、何らかのを演算してtopに出力
- backward : topの出力に関する勾配が与えられたら、入力に対する勾配を計算してbottomに送信、パラメータを持つ層はそのパラメータに関する勾配を計算してそれを内部的に保持する
- refer
- http://caffe.berkeleyvision.org/tutorial/net_layer_blob.html
https://github.com/BVLC/caffe/blob/536851c00e44d545649648b372503f52a89c0499/include/caffe/layer.hpp
を読むと、このlayer.hppで宣言されている仮想関数Forward_cpu()やForward_gpu()がレイヤーの順伝搬処理を担当しており、以下のような宣言になっている
/** @brief Using the CPU device, compute the layer output. */
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) = 0;
/**
* @brief Using the GPU device, compute the layer output.
* Fall back to Forward_cpu() if unavailable.
*/
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// LOG(WARNING) << "Using CPU code as backup.";
return Forward_cpu(bottom, top);
}
これらを、それぞれのレイヤーでオーバーライドして、順伝搬処理を定義している。
例えば、conv_layer.cppでは以下のようにオーバーライドされている。
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data(); // 重みを取得
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data(); // bottomのblobからデータをもらう(変更しない)
Dtype* top_data = top[i]->mutable_cpu_data(); // topのblobから参照をもらう(データの更新を行う)
for (int n = 0; n < this->num_; ++n) {
// forward_cpu_gemm(const Dtype* input, const Dtype* weights, Dtype* output, bool skip_im2col = false)
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight, top_data + n * this->top_dim_); // 畳み込み計算の本体
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data(); //biasを取得
this->forward_cpu_bias(top_data + n * this->top_dim_, bias); //bisaの足し算
}
}
}
}
同様に逆伝搬時の処理(Backward_cpu()、Backward_gpu())は以下のように宣言されている。
/**
* @brief Using the CPU device, compute the gradients for any parameters and
* for the bottom blobs if propagate_down is true.
*/
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) = 0;
/**
* @brief Using the GPU device, compute the gradients for any parameters and
* for the bottom blobs if propagate_down is true.
* Fall back to Backward_cpu() if unavailable.
*/
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
// LOG(WARNING) << "Using CPU code as backup.";
Backward_cpu(top, propagate_down, bottom);
}
これらの仮想関数を、それぞれのレイヤーでオーバーライドすることで逆伝搬を処理している。
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* weight = this->blobs_[0]->cpu_data(); // 重み取得(更新しない)
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff(); // 重み勾配を参照(更新可能)
for (int i = 0; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff(); // topのblobから_diffを取得(更新しない)
const Dtype* bottom_data = bottom[i]->cpu_data(); // bottomのblobから_dataを取得(更新しない)
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff(); // bottomのblobから_diffを取得(更新可能)
/*
@param bias_term : (\b optional, default true). Whether to have a bias.
@param param_propagate_down_ : indicating whether to compute the diff of each param blob
*/
if (this->bias_term_ && this->param_propagate_down_[1]) {
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff(); // bias勾配を参照(更新可能)
for (int n = 0; n < this->num_; ++n) {
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_); // bias勾配を更新
}
}
/*
@param propagate_down : 各インデックスは、エラー勾配を対応するインデックスのbottomのblobまで伝搬するかどうかを示す
*/
if (this->param_propagate_down_[0] || propagate_down[i]) {
for (int n = 0; n < this->num_; ++n) {
// gradient w.r.t. weight. Note that we will accumulate diffs.
if (this->param_propagate_down_[0]) { // 重み勾配の計算
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,top_diff + n * this->top_dim_, weight_diff);
}
// gradient w.r.t. bottom data, if necessary.
if (propagate_down[i]) { // bottomのデータの勾配計算
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight, bottom_diff + n * this->bottom_dim_);
}
}
}
}
}
#### Blob
Caffeではblobという一つのクラスで、多層ニューラルネットワークで用いられる、様々な種類のデータをラップしている。Caffeではこのblobを使用してデータをストアして通信しており、blobはデータ(画像、モデル・パラメータ、勾配など)を保持する統一されたメモリ・インターフェイスを提供している。実装としてはblobのデータはm次元構造となっており、データはmalloc関数で動的にメモリ上に確保される(Row-major)仕組みになっている。
昔はblobが4次元構造としての仕様だったため、4次元として使われることも多く、次元は以下の図のようになっている場合が多いらしい。
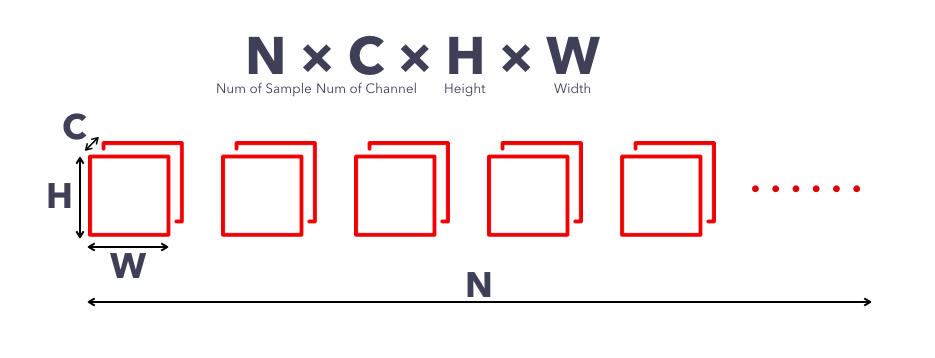
N : データのバッチサイズ、画像の枚数(畳み込み層の内部パラメータにおいてはカーネルの数)
C : 特徴次元の大きさ、RGBなら3、グレースケールなら1という感じ(畳み込み層の内部パラメータにおいてはカーネルのチャンネル数)
H : 画像やカーネルの高さ
W : 画像やカーネルの幅
blobではSyncedMemoryという、Caffeの独自のクラスを用いてCPU/GPUのデータのやり取りを任せている。この機構によって効率的なデータのやりとりが行われるように設計されている。SyncedMemoryではCPUとGPUのメモリ空間上のデータがどのような状態か保持するべく、syncedmemに示すステータスをメンバ変数に持っている。以下にそれぞれのステータスを示す
| status | description |
|---|---|
| UNINITILIZED | まだメモリが書庫化されていない状態 |
| HEAD_AT_CPU | CPU上のデータを更新した状態 |
| HEAD_AT_GPU | GPU上のデータを更新した状態 |
| SYNCED | CPUとGPUにおいて同期が行われたのちの状態 |
- data_ はニューラルネットワークのそうの内部のパラメータの値を保持する
- diff_ はBackpropagation(誤差逆伝搬法を用いて学習する)時に、各ユニットの勾配情報を保持する
このレイヤの処理をy=f(x; h) (xは入力、yは出力, hはパラメタ)とするときに、
x, y, hはdata_に格納され、(L(x, …, ; h, …)を損失関数とする場合に)Backpropagationされてきた値、dL/dx, dL/dy, dL/dhはそれぞれdiff_に格納されるように使われる
- cite
- http://tnarihi.github.io/machine%20learning/2014/12/10/CAFFE-Layer/
ちなみにblobメモリのレイアウトはrow-majorなので(Cと一緒というかC++)、最右端の次元は最も速く変更される。上記の図のにおいて、インデックス(n, c, h, w)の値は物理的にはインデックス
((n * C + c) * H + h) * W + w
に位置になります。
#### Solver
solverはモデル損失を小さくし、最適化していくもので、solver定義ファイルは、そのモデルをどのように学習させるかを設定するためのもの。solver定義ファイルも.prototxt形式(plaintext protocol buffer schema)の書式に従って、利用するネットワーク定義ファイルの設定や、学習率の計算方法、損失関数の正規化項の重みパラメータなどを記述している。以下のファイルに細かく書いてあります。
// NOTE
// Update the next available ID when you add a new SolverParameter field.
// SolverParameter next available ID: 42 (last added: per_parameter_reduce)
message SolverParameter {
// 略
// Proto filename for the train net, possibly combined with one or more
// test nets.
optional string net = 24;
// 略
// The number of iterations for each test net.
repeated int32 test_iter = 3;
// 略
optional int32 max_iter = 7; // the maximum number of iterations
// 略
enum SolverMode {
CPU = 0;
GPU = 1;
}
optional SolverMode solver_mode = 17 [default = GPU];
// 略
// DEPRECATED: old solver enum types, use string instead
enum SolverType {
SGD = 0;
NESTEROV = 1;
ADAGRAD = 2;
RMSPROP = 3;
ADADELTA = 4;
ADAM = 5;
}
// DEPRECATED: use type instead of solver_type
optional SolverType solver_type = 30 [default = SGD];
// 略
ちなみにcaffe::Solver::solve()は学習を実行する関数ですが、コメントを読むと、入力データがなかったりする場合はDummyDataを流すよみたいなことが書いていありました(これがCaffe Timeでデータソース指定しない時に流れているのかな)
template <typename Dtype, typename Mtype>
void Solver<Dtype,Mtype>::Solve(const char* resume_file) {
CHECK(Caffe::root_solver());
LOG(INFO) << "Solving " << net_->name();
LOG(INFO) << "Learning Rate Policy: " << param_.lr_policy();
// Initialize to false every time we start solving.
requested_early_exit_ = false;
if (resume_file) {
LOG(INFO) << "Restoring previous solver status from " << resume_file;
Restore(resume_file);
}
// For a network that is trained by the solver, no bottom or top vecs
// should be given, and we will just provide dummy vecs.
Step(param_.max_iter() - iter_);
## TrainingとTest
Caffeにおける順伝搬(Forwarding)はlayerのbottomにblobを入力し、topから処理結果のblobを得ることであり、全体としてはニューラルネットワークに入力データを与え、入力層から一層ずつ前述の操作を行うことに値します。
逆伝搬(Backforward)に関しては、Layerのtopのblobからbottomのblobの勾配情報を計算することが該当する。
networkの定義において
layer {
name: "hoge"
//略
include {
phase: TRAIN
}
とか書いておくと、このレイヤーhogeはTRAIN時にしか使われないようになっている、TEST時も同様の記述で実現できる。
caffe/tools/caffe.cppを見てみると、順伝搬処理はcaffe::Net::Forward()にて行っており、caffe/src/caffe/net.cpp内部でForward()を、さらに内部的に、ForwardFromTo()とかが呼ばれて行って、Layerごとの処理が行われている。
ちゃんと読めてないから検証する必要があるが、Forward時、すべてのLayerでlossを図って最後にたしこんでいるっぽい!?
逆伝搬はBackward()が呼ばれたのち内部でBackwardFromTo()とかが呼ばれて、_dataとか_diffとか集計している。
また、Net::update()にてパラメータ更新を行っているっぽい。
template <typename Dtype>
void Net<Dtype>::Update() {
for (int i = 0; i < learnable_params_.size(); ++i) {
learnable_params_[i]->Update();
}
}
実行などに関する使い方の詳細な説明は、実行コマンドのセクションに書いています。
## ソースコード
## サポート環境
下記リンクが公式なのでこちらを参照
http://caffe.berkeleyvision.org/installation.html
・Docker setup out-of-the-box brewing
・Ubuntu installation the standard platform
・Debian installation install caffe with a single command
・OS X installation
・RHEL / CentOS / Fedora installation
・Windows see the Windows branch led by Guillaume Dumont
・OpenCL see the OpenCL branch led by Fabian Tschopp
・AWS AMI pre-configured for AWS
みたいなことが書いてある。
## 依存ライブラリのインストール
下記リンクが公式なのでこちらを参照(さっきと同じリンク)
http://caffe.berkeleyvision.org/installation.html
Prerequisitesに関して、以下のものをCaffeのInstall前にInstallする必要がある。
#### CUDA
NVIDIAのGPUを使うためのSDKで、Caffeでの処理を高速化するため、CUDAを用いることでGPUを利用し、高速な並列計算(畳み込み計算とかの行列計算など)を行う。一応なくても動くが、学習がめっちゃ遅くなるので推奨しない視されていないはず。
#### BLAS
Basic Linear Algebra Subprograms(BLAS)は、ベクトルと行列に関する基本線型代数操作を実行するライブラリAPIの基礎的なもの。さらに特異値分解できたりもっと機能が備わったものにLAPACKがある。CaffeではこのBLASとして、ATLAS、OpenBLAS、MKLの三種類が対応しており、Makefile.configで切り替えることが可能になっている。
以前書いた記事でも少し紹介しました
- 低ランク近似のためのHLIBpro,MAGMA入門 # BLAS routines
http://qiita.com/Hiroki11x/items/c751869e934d26a6b5af#-blas-routines
#### OpenCV
ComputerVisionライブラリ、Caffeでは画像の入出力周りや、画像の一部切り抜きなどに使っており、version 2.4以降がサポートされている?3.xを使う場合はMakefile.configを書き換える必要あり(実験してない)
#### Boost
C++ライブラリ、Caffeのこの機能をみたいなspecificなものじゃなくて全体的に広くいろんな機能が使われていそうな感じがする
#### glog
ログに関するC++ライブラリ、先頭のgはGoogleのg
#### gflags
コマンドラインオプションC++ライブラリ、これの先頭のgもGoogleのgかな
- refer
- Open Source gflags library
- https://github.com/gflags
#### Protobuf
データの効率的なシリアライズ機能を提供するこれまたGoogle製ライブラリ。
.protoのファイルを、各データをメンバ変数として扱うクラスを自動生成したりするらしい、それらはC++やPythonインターフェースから扱える。
#### LevelDB
Key-Value StoreのDB、アクセスされやすいデータごとに階層的に分けていて、アクセス効率がいいらしい。Caffeでは画像のLabelとその画像のpathをkey-valueとしてもつDBを用意してからそれらのデータを扱う。
ただ、LevelDBは一つののプロセスからアクセスされると他のプロセスはアクセスできないロックがかかる仕様なのでそれが嫌ならLMDBを使う。
研究室とか複数人で同じデータセット使ってたりするとこれは結構シビア。
#### snappy
データの圧縮解凍系のライブラリ、LevelDBでデータ保存の時に使われているらしい
LevelDBとSnappyに関しては以下の記事がとてもわかりやすかったです
- refer
- LevelDB入門 (基本編)
- http://yosuke-furukawa.hatenablog.com/entry/2014/05/05/095207
#### LMDB
LevelDBと同じ感じ、ただ、LMDBではLevelDBとは違い、ロックがかからず複数プロセスで同じデータセットを使うことができる。mdb_statコマンドで詳細を見ることができる。LMDBに関する詳細な記事は以下がとても参考になりました。
$ mdb_stat ilsvrc12_val_lmdb
Status of Main DB
Tree depth: 3
Branch pages: 10
Leaf pages: 705
Overflow pages: 2450000
Entries: 50000 #50000個のレコード
$ mdb_stat ilsvrc12_train_lmdb
Status of Main DB
Tree depth: 4
Branch pages: 224
Leaf pages: 18256
Overflow pages: 62777183
Entries: 1281167 #1281167個のレコード
- refer
- The LMDB file format
- https://blog.separateconcerns.com/2016-04-03-lmdb-format.html
- https://lmdb.readthedocs.io/en/release/
#### hdf5
HDF5はHierarchical Data Format 5の略で、その名前の通り階層化されたデータ群を取り扱うファイル形式。Caffeとしての使われ方は、DBだけでなく、HDF5形式のファイルを入力や出力そして扱える。
#### Python(optional)
sudo が使えなくてもpyenvとかを導入して、新しめのバージョンにしておくとpip install とかが使えるのでだいたいできます。
- refer
- pyenvを使ってPython環境を構築
- http://keisanbutsuriya.hateblo.jp/entry/2015/01/26/224127
に、sudo使えなくてもできるpyenvの環境構築法とpyenvを使ってpip installするまでの流れがまとまっているので参考になります。
- refer
- Ubuntu 14.04にCaffeをインストール(GPU編)
- http://qiita.com/TD72/items/bcb243ee02760ea1d8bb
とかを参考にすると、
sudo pip install -r ~/caffe/python/requirements.txt
make pycaffe -j4 #(jはパラレルmakeのオプション)
とかして上手くいけば
import caffe
ができるようになれここまでできれば大丈夫です。
#### Matlab(optional)
matcaffeとかいうのをmakeするっぽい
http://caffe.berkeleyvision.org/tutorial/interfaces.html
# マルチGPUに関して
- refer
- https://github.com/BVLC/caffe/blob/master/docs/multigpu.md
#### マルチGPUの使用
現在、マルチGPUはC/C++パスを介してのみサポートされており、___トレーニングのためにのみ___使用されています。
トレーニングに使用するGPUは、コマンドラインの "-gpu"フラグを使って 'caffe'ツールに設定できます。 たとえば、 build/tools/cafe train --solver=models/bvlc_alexnet/solver.prototxt --gpu=0,1はGPU0と1でトレーニングを行います。
注:各GPUはtrain_val.prototxtで指定されたバッチサイズを実行します。 つまり、1GPUから2GPUにすると、効果的なバッチサイズが倍増します。train_val.prototxtで、256のバッチサイズを指定した場合は、2つのGPUを実行すると、あなたの効果的なバッチサイズは512となります。そのため、複数のGPUを実行するときにバッチサイズを調整および、また具体的には学習率などのparamsを調整する必要があります。
#### ハードウェア構成の前提
現在の実装では、tree reduction strategyと呼ばれる方針に基づきなされています。4GPUで学習を行う場合、まずGPU0と1で、GPU2と3で勾配の交換が行われます。その後、GPU0と2で交換を行い(ツリーの最上部)、0が更新を計算します。その後GPU0->2へ、GPU0->1,GPU2->3と行った通信が行われます。
最高のパフォーマンスを実現するために、デバイス間のP2P DMAアクセスが必要とされています。P2Pアクセスせずに、のPCIeのルートコンプレックス(以下の図を参照)を横断すると、データはホストを通じてコピーされ、効果的な交換帯域幅が大幅に低減されます。

- refer
- http://www.cqpub.co.jp/dwm/contents/0121/dwm012100230.pdf>
現在の実装では、使用中のデバイスが均質である「ソフト」の仮定を持っています。実際には、同じ一般的クラスのいずれかのデバイスは、一緒に動作するはずですが、パフォーマンスおよび全体のサイズは、使用されるGPUの中で最小のGPUによって制限されます。例えば、TitanXとGTX980を組み合わせた場合、GTX980によって性能は制限されます。
非常に異なるレベルの性能のボードの混在を許容しますが、例えばKepler世代やFermi世代のGPUは、サポートされていません。
nvidia-smi topo -m は接続マトリックスを表示します。 PCIeブリッジを介してP2Pを実行できますが、現時点ではソケットレベルのリンクを経由することはできません。CPUソケットはマルチソケットのマザーボード上を横断することになります。
#### スケーリングパフォーマンス
パフォーマンスは、大きくシステムのPCIeのトポロジ、訓練されたニューラルネットワークの構成、および各層の速度に依存します。 DIGITS DevBoxようなシステムは、最適化されたPCIeトポロジ(X99-E WSチップセット)を持っています。
一般的に、2つのGPU上でスケーリングするAlexNet、CaffeNet、VGG、GoogleNetようなネットワークのスピードは平均〜1.8倍になる傾向があります。
4 GPUのスケーリングからは減衰が始まります。 一般に、GPUの数によってバッチサイズが増加する「弱いスケーリング」では、3.5倍のスケーリングになる傾向があります。 「強いスケーリング」により、システムは通信が制限(速さの上限)になり、特にcuDNNv3のレイヤーのようなレイヤーのパフォーマンスの最適化を行うと、パフォーマンスが中規模の2.xスケールに近づく可能性が高くなります。 パラメータの数と比較して計算量が多いネットワークは、スケーリング性能が最も優れている傾向があります。
## ビルド
#### Makefile
公式にそのまま書いてあるが
cp Makefile.config.example Makefile.config
# Adjust Makefile.config (for example, if using Anaconda Python, or if cuDNN is desired)
make all
make test
make runtest
で終了、基本的にMakefileは触らず、細かな設定はMakefile.configで行う。
Makefile.configは元々存在せず、Makefile.config.exampleがあるのでそれをコピーして作る。
これで上手くいってない場合、依存するライブラリのバージョンやPath、使っているOSなど何かがおかしくてCaffeが悪いわけではない(ほとんどの場合そのはず)
#### Makefile.config
ここで細かな設定を行う。cuDNNを使いますかとか、BLASとしてOpenBLAS使うのかMKL使うのかとか、ここもコメントに丁寧にいろいろ書いているのでMakefile.config.exampleを見本にして適宜変えればよさそう、Python使う場合でAnaconda使ってるとはまりましたみたいな記事はよく見た。
#### CMake
これも公式ページに書いてるまんまだが、
CMake versionが 2.8.7. 以上であることに注意して
mkdir build
cd build
cmake ..
make all
make install
make runtest
でできる
上手くいくと
~省略~
[ RUN ] PoolingLayerTest/0.TestSetupPadded
[ OK ] PoolingLayerTest/0.TestSetupPadded (0 ms)
[ RUN ] PoolingLayerTest/0.TestForwardMaxPadded
[ OK ] PoolingLayerTest/0.TestForwardMaxPadded (0 ms)
[----------] 11 tests from PoolingLayerTest/0 (1805 ms total)
[----------] Global test environment tear-down
[==========] 2101 tests from 277 test cases ran. (456331 ms total)
[ PASSED ] 2101 tests.
みたいなのがめっちゃ出て終わる。テストはランダムに選ばれるっぽいので表示がこの限りとは限らないが、最後にPASSEDと出ればOK
## 実行コマンド
#### Training
caffe trainは、モデルをゼロから学習し、保存されたスナップショットから学習を再開し、モデルを新しいデータやタスクに微調整する役割を持ちます。また、すべてのトレーニングでは、 -solver hoge_solver.prototxtなどの引数を使用してソルバーの設定が必要です。
BVLCのCaffeに標準で含まれているサンプルのcaffe/examples/mnist/train_lenet.shを見ると以下のコマンドが実行されることになっています。
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
ここで、どのように学習をするかを定めるexamples/mnist/lenet_solver.prototxtは以下のように定義されています。
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: GPU
trainingを実行すると以下のような画面が始まり、maxiterまで学習し始めます
$ ./examples/mnist/train_lenet.sh
I0507 14:05:58.821902 11965 caffe.cpp:218] Using GPUs 0
I0507 14:05:58.957305 11965 caffe.cpp:223] GPU 0: GeForce GTX 1080
I0507 14:06:00.079802 11965 solver.cpp:44] Initializing solver from parameters:
test_iter: 100
test_interval: 500
base_lr: 0.01
display: 100
max_iter: 10000
lr_policy: "inv"
gamma: 0.0001
power: 0.75
momentum: 0.9
weight_decay: 0.0005
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
solver_mode: GPU
device_id: 0
net: "examples/mnist/lenet_train_test.prototxt"
train_state {
level: 0
stage: ""
}
# 略
#### Test
caffe testはでは、用いるネットワーク及び、学習済みの重み、何回繰り返すかなどをオプションで添えて実行します。
テストフェーズでモデルを実行してスコア(認識精度/precision)を出力してくれます。
caffe test -model examples/mnist/lenet_train_test.prototxt -weights examples/mnist/lenet_iter_10000.caffemodel -gpu 0 -iterations 100
- refer
- http://caffe.berkeleyvision.org/tutorial/interfaces.html
#### Time
caffe timeはベンチマークとして使うことができる超便利なコマンドです。レイヤーごとにかかった時間、またそのiterationでの平均値などを算出してくれます。
caffe time -model examples/mnist/lenet_train_test.prototxt -iterations 10
- refer
- http://caffe.berkeleyvision.org/tutorial/interfaces.html
また、model/xxx/deploy.prototxtというのがCaffeに標準でついてくる。これについてベンチマークを行うと。
./build/tools/caffe time --model=./models/bvlc_alexnet/deploy.prototxt --iterations=10 --gpu 0
name: "AlexNet"
state {
phase: TRAIN
level: 0
stage: ""
}
layer {
name: "data"
type: "Input"
top: "data"
input_param {
shape {
dim: 10
dim: 3
dim: 227
dim: 227
}
}
}
//省略
I0510 10:47:12.677161 16946 layer_factory.hpp:77] Creating layer data
I0510 10:47:12.677193 16946 net.cpp:84] Creating Layer data
I0510 10:47:12.677209 16946 net.cpp:380] data -> data
I0510 10:47:12.697302 16946 net.cpp:122] Setting up data
I0510 10:47:12.697355 16946 net.cpp:129] Top shape: 10 3 227 227 (1545870)
I0510 10:47:12.697399 16946 net.cpp:137] Memory required for data: 6183480
//省略
I0510 10:47:14.125509 16946 caffe.cpp:409] relu7 forward: 0.020848 ms.
I0510 10:47:14.125519 16946 caffe.cpp:412] relu7 backward: 0.0026336 ms.
I0510 10:47:14.125530 16946 caffe.cpp:409] drop7 forward: 0.0311904 ms.
I0510 10:47:14.125545 16946 caffe.cpp:412] drop7 backward: 0.002704 ms.
I0510 10:47:14.125561 16946 caffe.cpp:409] fc8 forward: 0.15697 ms.
I0510 10:47:14.125577 16946 caffe.cpp:412] fc8 backward: 0.283552 ms.
I0510 10:47:14.125589 16946 caffe.cpp:409] prob forward: 0.024816 ms.
I0510 10:47:14.125603 16946 caffe.cpp:412] prob backward: 0.0026976 ms.
I0510 10:47:14.125624 16946 caffe.cpp:417] Average Forward pass: 4.94375 ms.
I0510 10:47:14.125636 16946 caffe.cpp:419] Average Backward pass: 7.22178 ms.
I0510 10:47:14.125654 16946 caffe.cpp:421] Average Forward-Backward: 12.3081 ms.
I0510 10:47:14.125671 16946 caffe.cpp:423] Total Time: 123.081 ms.
I0510 10:47:14.125682 16946 caffe.cpp:424] *** Benchmark ends ***
のような感じで、各レイヤーでどれだけ時間がかかるのかみたいなのが出力されてとても便利。
だが、これデータソースはどうなってるのか調べた結果、models/bvlc_alexnet/deploy.prototxtに記述がある
layer {
name: "data"
type: "Input"
top: "data"
input_param {
shape {
dim: 10 #バッチサイズ
dim: 3 #入力画像のチャンネル数
dim: 227 #入力画像の幅
dim: 227 #入力画像の高さ
}
}
}
において、データレイヤーがtype: "Input"となっている、この場合データ入力がなければ
指定された寸法(shape内のもの)を持つ入力データとしてZeroのBlobを使用するらしい。
英語ですが、以下のAndres Rodriguezさんのブログにデータレイヤーのことがとてもわかりやすくまとまっていました。
- refer
- http://rodriguezandres.github.io/2016/04/28/caffe/#data-layer
ちなみに、train_val.prototxtとかを timeコマンド時にmodelに設定すると、batchsizeとかはTRAIN Phaseのものが使われる。
${CAFFE_HOME}/build/tools/caffe time \
-model=${CAFFE_HOME}/models/bvlc_alexnet/train_val.prototxt \
-weights=${CAFFE_HOME}/models/bvlc_alexnet/bvlc_alexnet_train_iter_100000.caffemodel \
-iterations=10 \
-gpu 0
とか実行すると
I0517 03:44:53.520543 3399 caffe.cpp:302] Use GPU with device ID 0
I0517 03:44:54.126338 3399 net.cpp:339] The NetState phase (0) differed from the phase (1) specified by a rule in layer data
I0517 03:44:54.126389 3399 net.cpp:339] The NetState phase (0) differed from the phase (1) specified by a rule in layer top-1
I0517 03:44:54.126395 3399 net.cpp:339] The NetState phase (0) differed from the phase (1) specified by a rule in layer top-5
I0517 03:44:54.126405 3399 net.cpp:50] Initializing net from parameters:
name: "AlexNet"
state {
phase: TRAIN
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "/path_to_ILSVRC2012/imagenet_mean.binaryproto"
}
data_param {
source: "/path_to_ILSVRC2012/ilsvrc12_train_lmdb"
batch_size: 600
backend: LMDB
}
}
のようにTrainが読み込まれるので注意。これは
caffe/tools/caffe.cppを読むと
// Time: benchmark the execution time of a model.
int time() {
CHECK_GT(FLAGS_model.size(), 0) << "Need a model definition to time.";
// 略
// Instantiate the caffe net.
Net<float,float> caffe_net(FLAGS_model, caffe::TRAIN);
となる実装になっているためである。
# トレーニングの可視化
caffeコマンドで(pythonとかinterfaceは関係ない)trainを実行すると、以下のようなグラフを表示することができます。それまでの手順について説明します。
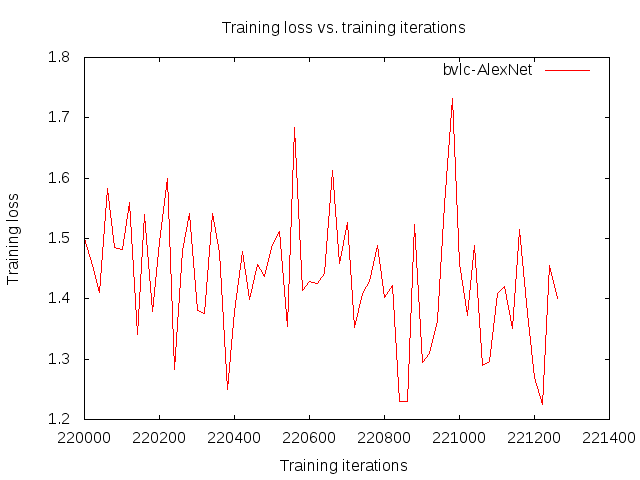
例えば、以下のようなコマンドを実行します。
$CAFFE_HOME/build/tools/caffe train \
-solver=$CAFFE_HOME/models/bvlc_alexnet/solver.prototxt -gpu 0 \
-snapshot=$CAFFE_HOME/models/bvlc_alexnet/caffe_alexnet_train_iter_220000.solverstate
すると、私の試した環境(RHEL/Ubuntu)では/tmpディレクトリ以下に
caffe.server01.hiroki11x.log.INFO.20170519-164456.15294みたいなログがはかれていました、中身を見たところconsoleに標準出力されるものと同じなので、自前でlogを別の場所に用意しておいてもいいかもしれません。参照記事によると、この命名規則は以下のようになっているそうです。
/tmp/<program name>.<hostname>.<user name>.log.<severity level>.<date>.<time>.<pid>
次に、$CAFFE_HOME/tools/extraに移動します。
parse_log.shという、先ほどのlogファイルをいい感じに整形してくれるshellscriptがあるので
./parse_log.sh /tmp/caffe.server01.hiroki11x.log.INFO.20170519-164456.15294
のような感じで実行します。すると、$CAFFE_HOME/tools/extra配下のように .testファイルと .trainファイルが生成されます。
.
├── caffe.server01.hiroki11x.log.INFO.20170519-164456.15294
├── caffe.server01.hiroki11x.log.INFO.20170519-164456.15294.test
├── caffe.server01.hiroki11x.log.INFO.20170519-164456.15294.train
├── extract_seconds.py
├── launch_resize_and_crop_images.sh
├── parse_log.py
├── parse_log.sh
├── plot_log.gnuplot.example
├── plot_training_log.py.example
└── resize_and_crop_images.py
次に、plot_training_log.py.exampleを編集します。
# README的な説明がめっちゃある
reset
set terminal png
set output "your_chart_name.png"
set style data lines
set key right
###### Fields in the data file your_log_name.log.train are
###### Iters Seconds TrainingLoss LearningRate
# Training loss vs. training iterations
set title "Training loss vs. training iterations"
set xlabel "Training iterations"
set ylabel "Training loss"
plot "caffe.server01.hiroki11x.log.INFO.20170519-164456.15294.train" using 1:3 title "bvlc-AlexNet"
plotの引数に、先ほど生成された.trainファイルを渡し、またタイトルや、set output "your_chart_name.png"の出力画像名なども適宜変えてください。
編集後
gnuplot plot_training_log.py.example
を実行することで先ほどの学習ログ画像が得られます。
- refer
- http://iamrobotandproud.hatenablog.com/entry/2015/03/16/105746
- https://groups.google.com/forum/#!msg/caffe-users/CqejrkmTOx0/3wqz7wnwCLkJ
ちなみに、caffe.server01.hiroki11x.log.INFO.20170519-164456.15294.trainの中身は以下のようになっています。
#Iters Seconds TrainingLoss LearningRate
220000 83.258757 1.50026 0.0001
220020 90.916095 1.45554 0.0001
220040 101.814559 1.41036 0.0001
220060 112.590374 1.58227 0.0001
220080 123.438262 1.48549 0.0001
220100 134.286942 1.48155 0.0001
#-----------------------------------
#省略
#-----------------------------------
221180 796.455915 1.37593 0.0001
221200 808.120826 1.27018 0.0001
221220 819.830181 1.2249 0.0001
221240 831.609373 1.45591 0.0001
221260 844.317303 1.39981 0.0001
# エラーあるある
-
*** Aborted at XXXXXXXXX (unix time) try "date -d @XXXXXXXXX" if you are using GNU date ***みたいなやつ
http://reiji1020.hatenablog.com/entry/2015/10/30/145147
# ベンチマーク
よくベンチマークとして用いられるネットワークとその特徴に関して引用
- GoogleNet
ILSVRC2014において、最も高い画像認識率を示したニューラルネットワークモデル。22層の畳み込み層からなり、全結合層を持たないという特徴的な構成をしています。このことからcuDNNの性能がよく表れるモデルのため、ベンチマークでよく用いられます。画像認識で、よく用いられるモデルです。
- AlexNet
ILSVRC2012において、前年の優勝データを大きく上回る画像認識率を示し、Deep Learningの火付け役となったニューラルネットワークモデル。5層の畳み込み層と、3層の全結合層の8層からなります。現在でも、画像認識に関わらず、多くの分野で、このモデルと同じようなモデルをよく目にします。
- cite
- http://www.hpc.co.jp/benchmark20160610.html
参考

#メモ
CaffeNetの場合 Batchsize 256
#image_netのtraining
./build/tools/caffe train -solver=models/bvlc_reference_caffenet/solver.prototxt -gpu 0 --logtostderr=1 2>&1 | tee train_result-FP16/train_caffenet.log
#image_netのtest
./build/tools/caffe test -model=models/bvlc_reference_caffenet/train_val.prototxt -weights=models/bvlc_reference_caffenet/caffenet_train_iter_6485.caffemodel -iterations=1000 -gpu 0
--logtostderr=1 2>&1 | tee test_result-FP16/output_alexnet.log
I0510 04:12:53.384995 102042 caffe.cpp:274] Loss: 1.64443
I0510 04:12:53.385035 102042 caffe.cpp:286] accuracy = 0.657996
I0510 04:12:53.385061 102042 caffe.cpp:286] loss = 1.64443 (* 1 = 1.64443 loss)
./build/tools/caffe_fp16 test -model=models/bvlc_reference_caffenet/train_val.prototxt -weights=models/bvlc_reference_caffenet/caffenet_train_iter_6485.caffemodel -iterations=1000 -gpu 0
--logtostderr=1 2>&1 | tee test_result-FP16/output_alexnet.log
I0510 04:15:47.524904 102208 caffe_fp16.cpp:206] Loss: 1.64453
I0510 04:15:47.524945 102208 caffe_fp16.cpp:218] accuracy = 0.658154
I0510 04:15:47.524963 102208 caffe_fp16.cpp:218] loss = 1.64453 (* 1 = 1.64453 loss)
#image_netのtime
./build/tools/caffe time -model=models/bvlc_reference_caffenet/train_val.prototxt -weights=models/bvlc_reference_caffenet/caffenet_train_iter_6485.caffemodel -iterations=1000 -gpu 0
./build/tools/caffe_fp16 time -model=models/bvlc_reference_caffenet/train_val.prototxt -weights=models/bvlc_reference_caffenet/caffenet_train_iter_6485.caffemodel -iterations=1000 -gpu 0