きっかけ
仕事で「関連するライブラリのバージョン一覧」を定期的に調べる必要があって最初はgithubをちまちま手動でアクセスして確認してたんですが、対象が15個以上あるとこれがもう途中で切れそうになる…
そういうときこそ自動化だ!ということで最初はRubyで、そしてJavaScript(+node.js)で、そして調子に乗ってgo言語で書いてみたのがこいつです。
(2015 12/08追記)
↓コメント欄を。mattnさんがAPIを使ってスクレイピングいらずの方法を教えてくださいました!
参考にした記事
HTML解析
goqueryでお手軽スクレイピング!
Go言語で jQuery ライクな操作が出来る goquery を試した。
Go routine
やったこと
まずはWeb Scrapingから
goqueryを使うと割と簡単、というか他の既存HTML解析ライブラリ(RubyのnokogiriとかmechanizeとかJavaScriptのcheerio-httpcliとか)と似た感じで扱えるのでこれを使います。とはいえ、例によってちょっとずつ言語ごとの実装による癖に苦労するのは同じですが。
先にgo getしてgoqueryを拾ってきておいてください。
$ go get github.com/PuerkitoBio/goquery
package main
import (
"fmt"
"github.com/PuerkitoBio/goquery"
"strings"
"time"
)
var ShortTimeFormat = "2006/01/02"
var LocationName = "Asia/Tokyo"
func GetTitleVerAndRelDate1(url string) {
defer func() {
err := recover()
if err != nil {
fmt.Println("Error on processing " + url)
}
}()
doc, _ := goquery.NewDocument(url)
// Title
fmt.Println("title = " + doc.Find(".container").Find("strong").First().Text())
// Version
fmt.Println("version = " + doc.Find(".tag-name").First().Text())
// Release Date
var st = doc.Find("span[class=date]").Children().Nodes[0]
var loc, _ = time.LoadLocation(LocationName)
var tm, _ = time.Parse(time.RFC3339, st.Attr[0].Val)
tm = tm.In(loc) // change location
fmt.Println("Release Date = " + strings.Replace(tm.Format(ShortTimeFormat), "/", ".", -1))
}
func GetTitleVerAndRelDate2(url string) {
defer func() {
err := recover()
if err != nil {
fmt.Println("Error on processing " + url)
}
}()
doc, _ := goquery.NewDocument(url)
// Title
fmt.Println("title = " + doc.Find(".js-current-repository").First().Text())
// Version
fmt.Println("version = " + doc.Find("span[class=css-truncate-target]").First().Text())
// Release Date
var st = doc.Find("time").Nodes[0]
var loc, _ = time.LoadLocation(LocationName)
var tm, _ = time.Parse(time.RFC3339, st.Attr[0].Val)
tm = tm.In(loc) // change location
fmt.Println("Release Date = " + strings.Replace(tm.Format(ShortTimeFormat), "/", ".", -1))
}
func main() {
GetTitleVerAndRelDate1("https://github.com/rust-lang/rust/releases")
GetTitleVerAndRelDate2("https://github.com/atom/atom/releases")
}
Web Scrapingなので力技です。それっぽいタグ名を当てにして必要な値を引っこ抜いてきています。
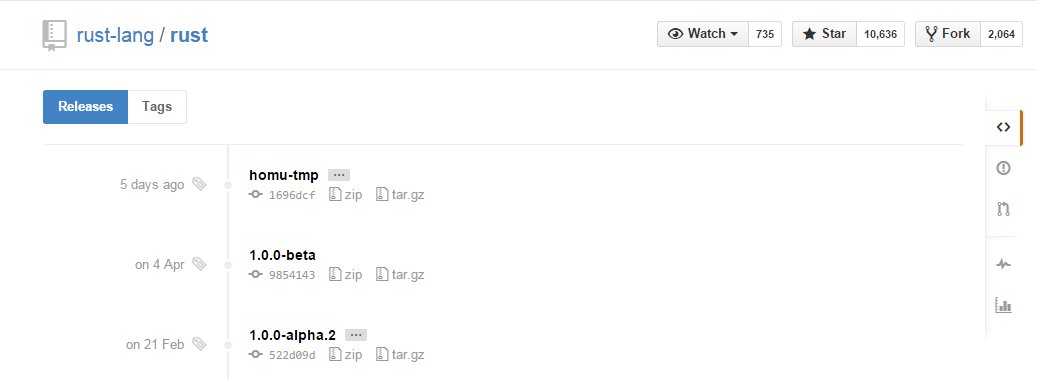
調べた範囲ではGitHubのリリースページには2通りの構成があり
- 地味なやつ(Type1とする)
- ちょっと派手なやつ(Type2とする)
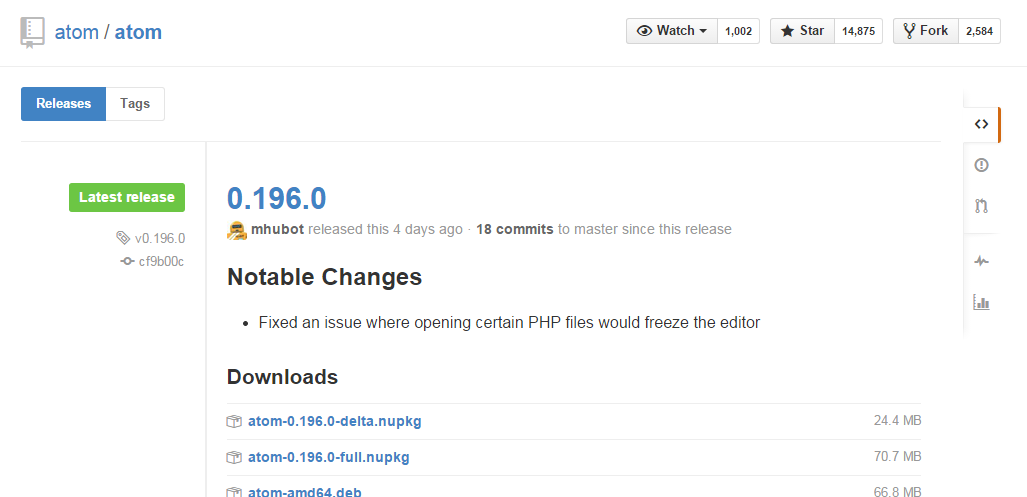
タイプによって必要なタグが違うのでそこだけ人力で初回チェックしてプログラムに反映するようにしています(プログラムで両方試せば良かった気もしますが)。
リリース日時についてはGitHubの日付がUTCなんでlocaleに合わせて修正しています。ここで書いてて面白かったのはGoの時刻の扱いです。必ず"2006年1月2日15時4分5秒"という「固定の時刻」をフォーマット用に使うという(上記ソースでいうと var ShortTimeFormat = "2006/01/02"のところ)。一般的な%YY%MMみたいなのに慣れてたもんで最初ちょっと混乱しました。何かの思い出の日付なのだろうか。
このまま対象となるGitHubのURLをずるずる書いていってもいいんですがそうなると各ページ逐次アクセスなんでかなり遅くなります。上の方で少し書きましたがJavaScript版は非同期プログラミングでQのPromiseを使って爆速で結果が取得できるようにしたのでGo版も似たようなことができないかと考えました。goroutineでできますね。
goroutineで非同期的にアクセス
goroutineの使い方は簡単で非常に大雑把に言うと関数の呼び出しの前にキーワードgoをつけるだけでいいです。
f()
go f()
とはいえ大抵の場合こう投げっぱなしでは役に立たなくて
- 引数をどう渡すか
- 結果をどう受け取るか
- どうやって最終的に処理を同期させるか
などはちゃんと考えないといけません。どうも調べてみるとgoのidiom的なものがいろいろある(例えばsyncモジュールを使う)んですが今回はこんな感じにしました。ループの中で無名関数としてgo routineを呼び出しチャネルで値を受け取ることで処理を同期させます。
func main() {
//...
// 結果受け取り用のチャネルを作成
// RetValは必要な値をまとめた構造体
// UrlListは文字列(Urlと上記の"タイプ"のペア)の構造体の配列
// RetValは必要な値をまとめた構造体
ch1 := make(chan RetVal, len(UrlList))
Results := make([]RetVal, len(UrlList))
for i, u := range UrlList {
go func(url string, tp string, index int) {
switch tp {
case "1":
ch1 <- GetTitleVerAndRelDate1(url, index)
case "2":
ch1 <- GetTitleVerAndRelDate2(url, index)
}
}(u.Url, u.Type, i)
// i(インデックス)は結果をUrlList順に並べるために使う
}
// 結果の取得と並べ替え
for i := 0; i < len(UrlList); i++ {
var r RetVal
r = <-ch1
Results[r.Index] = r
}
//...
}
これでかなり高速化できます。
13個の対象をアクセスした場合、非同期処理なしだと
real 0m6.315s user 0m1.977s sys 0m0.242s
非同期処理ありだと
real 0m2.751s user 0m1.867s sys 0m0.207s
とだいぶ速いですね。
(シングルコアCPUの場合なんでマルチコアだともっと差が出るかな)
雑感
Goをいじってみて感じたのはその移植性の高さです。今回LinuxとMacOSXでそれぞれ動かしてみましたが一回Goの環境が正しくセッティングされていれば全く変更なしで動作しました。
Windowsでも同じはず…なんですがWindows環境にGo設定するのに環境変数のところで力尽きたのでそこはまだ試してないです。→Windowsでも全然問題なしでした。えらいぞGo。
あと社内環境で動かす場合を考えると「普通にproxyを環境変数で設定しておけばプログラム固有の設定をする必要がなかった」のも地味にうれしい。Javaのproxy設定なんかクッソめんどくさいですし…。
そうそう、上で書いた実行速度評価結果はBeagle Bone Black
上のubuntuでのものです。BBBでvim+go開発サポート環境で十分実用的にプログラミングできた(さすがにビルドは普通のPCよりはちょっともっさりですが)というのも意外でした。
なんかGoは中国で大人気らしいんですがそのあたり(あまり速くないPCでも十分実用になる)も原因かもしれないですね。
フルソースはGitHubに上げておきました
追記
JavaScript版は現在QのPromiseを使って並列化してますがgeneratorで書き直したらそのうち公開予定っす。