John Bohnさんのブログ記事 Elixir Process Architecture or: How I Learned to Stop Worrying and Love to Crashの翻訳です。
Elixir(とそのベースになっているErlang)のプロセスは生成のためのコストが小さいため「下手にエラー処理するコードを書いてプロセスを維持するよりはさっさとクラッシュさせて、それに続く処理の中で対策して再起動したほうがよい」という思想があります。それを実際に適用してみたという話です。なお説明を簡単にするために多少端折ってるとのこと。
ところでこのタイトルは某古典的スラップスティックSF映画のアレですね…

"クラッシュさせちまえ"
それは私が聞かされ続けてきたことだ。正直言ってそのセリフの意味するところを理解するまで少々時間が必要だった。その考え方がピーンと来るにはProcessベースの構造に焦点をあてたいくつかのシステムを設計して実装するまでかかった。今ではそれは私の考え方のコアになっているし、そのおかげで耐障害性の高いよく考えられたシステムを、ずっと少ないコード量で書くことができる。
クラッシュさせちまうことについて学ぶ
実用的な例を見てみよう。最近作業していたことだが、私はあるHTTP APIを書いた。個人名と会社名を与えるとシステムは個人のメールアドレスを見つけて返す。このシステムはその機能を実現するためににいくつかのサードパーティAPI(例えばZoomInfoやJigsaw)を、そのAPIがユーザのメールアドレスを知っていた場合に利用していた。
複数の実際に動作しているサードパーティAPIを使ってみるとうまくいかないことがいろいろあった。サービスのうちのひとつがサービス停止になる、APIが変更される、サービスがタイムアウトするようになる、などありとあらゆることがうまくいかなかった。それら全部についてあなたならどうにかして対応できたと言うのか?最近こんなシステムに出くわした。そいつはXMLフォーマットで表現されたJavaのエラーを有効なJSON戻り値のケツにくっつけてきやがったんだ。しかもアクセスした回数のうち25%ぐらいで。そんな特殊な状況を想定してプログラムが書けたと思うか?無理だね。たとえあなたなら何にでも対処できた、としても私のコードのうち、75%がエラー処理、残りのたった25%が実際に意味のあるコードという有り様になったろう。
これを踏まえて私は新しいシステムをElixirで記述することを選んだ。それにはふたつのはっきりした理由がある。
第一に、詳細はこれから述べるが、"クラッシュさせちまえ"アプローチはずっと短いコードで書ける。一般的に短いコードは長いコードより理解しやすいんだ。第二に、外部APIの呼び出しは独立して行うことができるはずでそれは並行動作でうまくいくと思ったからだ。
アーキテクチャ
このシステムのこの部分の基本アーキテクチャは「早い者勝ち」だ。メールアドレスを求めるリクエストが入ってくるとそのリクエストをPerson構造体に変換する。ここから、複数の並行動作のサードパーティサービス呼び出しを行いたい。最初にメールアドレスを返してきたいずれかのサービスが勝ちで、そのアドレスが利用される。もしその後から他のサービスがメールアドレスを返してきたとしてもそれは無視される。もしどのサービスもメールアドレスを見つけられなかった場合は単に'null'メールアドレスを返す。
基本データ構造
深いところに入る前に2つの主なデータ型に関するデータ構造を決めるために構造体を定義したい。
defmodule Person do
defstruct name: nil, email: nil, company: nil
end
defmodule Name do
defstruct given_name: nil, family_name: nil
end
要求が来たとき、NameとPersonを持っている情報とくっつける。具体的には個人名と会社名である。我々のAPIはPersonのJSON表現を返す。もしメールアドレスを見つけることができたらその中身を埋めて返し、そうでなければnullを返す。例えば:
{
"name": {
"given_name":"John",
"family_name":"Bohn"
},
"email":"john.bohn@alphasights.com",
"company":"Alphasights"
}
注記として。私は全てのデータ型に対して構造体を作りたくはない。多くの場合、MapやKeywordで十分だ。しかしこのケースではこれらの構造体はシステム全体の重要なコア部分であるし、ちょいちょい受け渡しもされる。なので明確に定義した。
プロセス
ハイレベルなプロセス間のやりとり
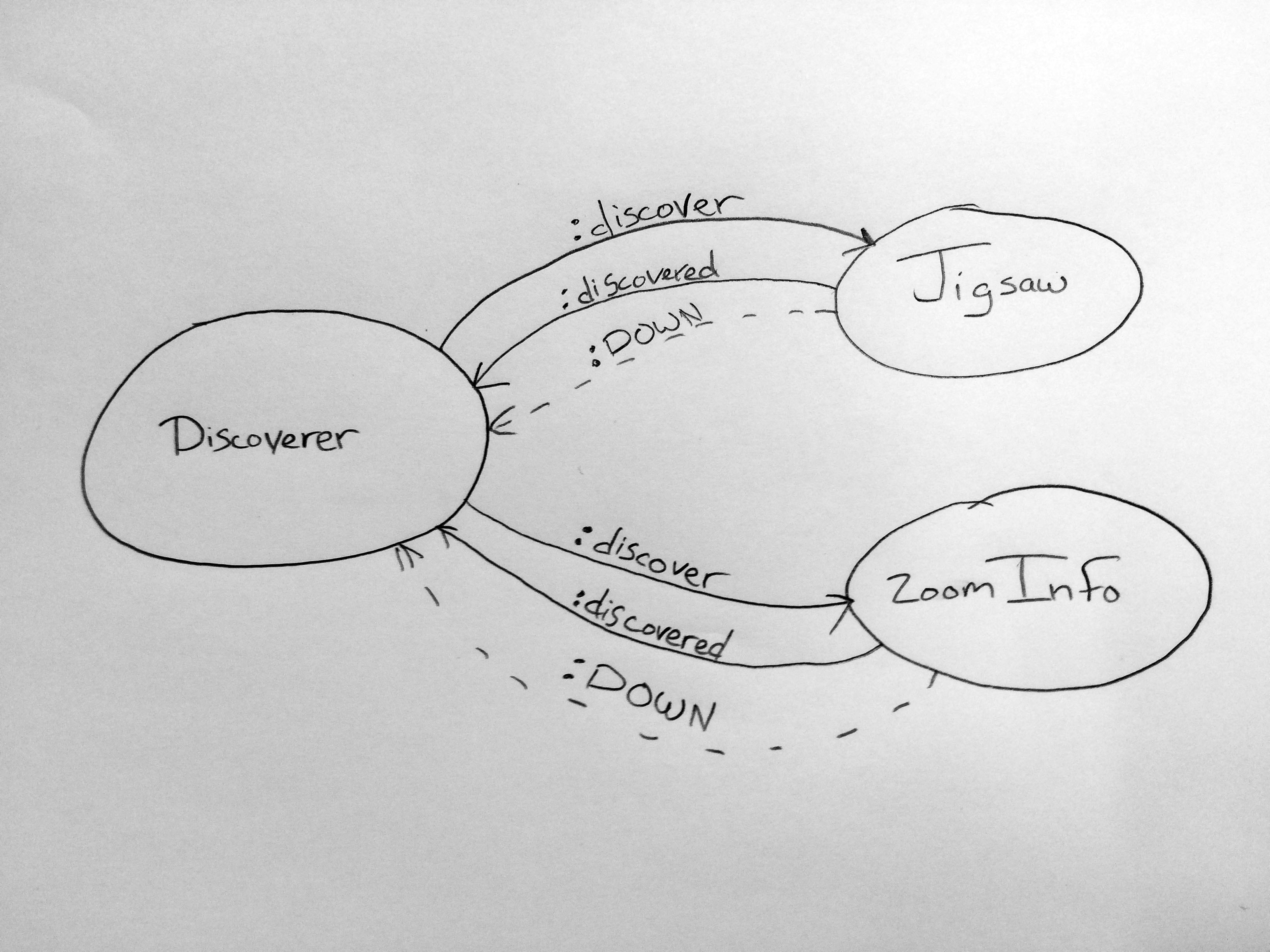
コンセプトとしては3つのプロセスが起動される。まず各APIのためのプロセス(JigsawとZoomInfo)。これらのプロセスはAPIの呼び出し及びメールアドレスが見つかった場合Person構造体のメールアドレス属性にその情報を追加することを受け持つ。
次にこれらの探索プロセスを統括する何かが必要だ。受け持ち範囲は探索プロセスの生成と監視、及びメールアドレスが見つかった場合にメールアドレスを含むPersonを返すことだ。ここで言う「監視」は非常に重要だ。なぜならそれこそ"クラッシュさせちまう"能力の核となる部分だからだ。これを元にして先に進もう。
その他に、各APIを呼び出すたびに新しくDiscoverer(およびそれに紐付けられたJigsawとZoomInfoプロセス)を生成する。作業が完了したらそれらを全部消す。パフォーマンスの差は微々たるものなのでプロセスのプールまではいらない。(少なくとも)10万個やそこらのプロセスは使い捨てにしてもかまわないのでどんどん使うことにしよう。もっともアプリによって事情は異なるのであなたのアプリでは適切な方法を選んで欲しい。
プロセスのタイプを選ぶ
ハイレベル視点からプロセスがどうやりとりするかを決めたので今度は具体的に必要なプロセスのタイプを選ぼう。Elixirにはいくつかの標準的な選択肢がある: GenServer, Task そして Agentだ。GenServerは振る舞いモジュールでErlang OTP由来だ。TaskとAgentはElixir特有の新しいプロセスについての抽象化だ。
Elixirのドキュメントはこれら様々なProcess抽象化についてとてもうまく説明している。以下に引用する。
GenServer
クライアント-サーバー関係のサーバーを実装するための振る舞いモジュール。
GenServerは他のElixirのプロセスと同様のプロセスで、状態を保存したりコードを非同期的に実行したりできる。このモジュールを使って実装したジェネリック・サーバー・プロセス(=GenServer)を利用するとトレースやエラーレポート機能を含む標準的なインターフェース機能が使える点がメリットである。スーパーバイザによる監視ツリーにも組み込むことができる。
Task
生成後、何らかの作業を待ち受けるのに適している。
Taskはそのライフサイクルを通じて特定の一つの動作だけを実行することになるプロセスだ。他のプロセスとほとんどもしくは全く通信しないこともある。Taskが一番よく使われるのは非同期的に値を計算する場合だ。
Agent
Agentは状態についてのシンプルな抽象化だ。
Elixirではときどき、他のプロセスから、もしくはそのプロセス自身の異なる複数の時点からアクセス可能な「状態」を共有したり保存したりする必要がある。
AgentモジュールはシンプルなAPIを使って状態を取得または更新する事が可能な基本的なサーバー実装を提供する。
このアプリではTaskとGenServerの両方を使う。Discovererは何らかの状態を保持する必要があるし標準的なインターフェースを持たせたいからGenServerとする。特に実行中のメールアドレス発見のサービスタスクの一覧リストを保持する必要がある。本当ならAgentでも事足りるかもしれないがGenServerの提供する標準的なインターフェースが使いたかったのだ。JigsawとZoomInfoプロセスはTaskで行こう。GenServerでも書けるがこれらのプロセスは生存期間が短いし状態を持たないのでTaskを選ぶのがいいだろう。Taskはプロセスのラッパーだと考えたい。Taskは任意のコードをProcessにしてくれる。
最初のサービスを書く
まずJigsawのAPIを使う何らかのコードから始めてDiscovererに管理させてみるとしよう。最初にこのサービスのための基本設定を拾ってくるモジュールを作る。
defmodule Jigsaw.Settings do
def api_base_url do
"https://www.jigsaw.com/rest/searchContact.json?"
end
def api_token do
Application.get_env(:jigsaw, :api_token)
end
def username do
Application.get_env(:jigsaw, :username)
end
def password do
Application.get_env(:jigsaw, :password)
end
end
超そのまんまのコードだ。単にいくつかの保護された情報をMixの設定から引っ張ってくるだけだ。メタプログラミングを使って重複を避けることもできたと思うがこれはすごくシンプルなのでそこまでする価値を見いだせなかった。次にJigsawとやりとりするコードを書く。
defmodule Jigsaw do
import Jigsaw.Settings
def discover_email(%Person{name: name, company: company}) do
query = %{token: api_token,
firstname: name.given_name,
lastname: name.family_name,
companyName: company}
url = api_base_url <> URI.encode_query(query)
HTTPotion.get(url, timeout: Application.get_env(:jigsaw, :timeout))
|> process_response
end
defp process_response(%{status_code: 200, body: body}) do
body
|> to_string
|> Poison.decode!
|> extract_email
end
defp extract_email(%{"contacts" => [%{"email" => email} | _]}), do: email
end
先のJigsaw.Settingモジュールを最初にインポートしているのでその設定機能が使える。次にパブリックにアクセスできる唯一の関数discover_email/1を定義する。(Jigsaw.Settingからの)設定とPersonを引数にとってHTTPリクエストをJigsawに送る。
process_response/1。はい、ここからいろいろ面白くなりますよ。パターンマッチによってステータスコード200のレスポンスだけ対応するように宣言的に記述する。それ以外のものが来たらFunctionClauseError例外が飛ぶだろう。このやり方はとても強力だ。よいプロセス指向アーキテクチャと組み合わせれば、私に言わせればElixirとErlangのエラー処理機構を独特のものにしている何か、の肝の部分を作ることができる。「うまく行く道筋(というか少なくとも我々が何を処理させたいかはっきりわかっている道筋)」を宣言的に記述することによって、クラッシュを起こすのはあれとこれで…それらに対しては何か準備しないといけない、ということを表明することになる。
最後に同じテクニックをextract_email/1でも、レスポンスのボディがcontactsというキーバリューペアを持っていることを保証するために使う。contactsの値はListだ。そのListには少なくとも一つ以上の要素があり、その先頭要素がemailのキーバリューペアだ。これで全てだ。if文は使われていない。その代わりに何か真でない物が来たらこのプロセスをクラッシュさせてFunctionClauseError例外を飛ばすようにしているだけだ。
Discoverer
では全ての連携を処理する関数をDiscovererモジュールの中に作っていこう。この関数はいくつかのコード例からつくり上げるがまずGenServerの「クライアント側の」関数から始めよう。
クライアント側
defmodule Discoverer do
use GenServer
def start_link(discovery_services \\ [Jigsaw]) do
GenServer.start_link(__MODULE__, [discovery_services: discovery_services, tasks: []])
end
def discover(pid, person) do
discovery_timeout = Application.get_env(:email_discovery, :discovery_timeout)
GenServer.call(pid, {:discover, person}, discovery_timeout)
end
end
ごく標準的な内容だ。start_link/1関数は新しいGenServerを空のListと共に開始する。そのListを使ってこれから生成するメールアドレス発見用タスクを見失わないようにする。この関数にはアドレス発見用のモジュールを導入することもできるし、問題のないデフォルト値1が設定されていることに注意。これによって柔軟性が高くなるしモック実装を使わなくてもテストがより簡単になる。実際のアプリには全てにテストが実装されているがこの記事では簡潔にするために省いてある。
全ての発見用プロセスを起動する公開インターフェースdiscover/2も作った。ここには設定ファイルから持ってきたタイムアウト値が設定される。このGenServer呼び出しのタイムアウトはメールアドレス発見タスクのHTTPリクエストのタイムアウトより優先されないといけないので、もし発見タスクがタイムアウトする場合はDiscovererのGenServer呼び出しより前にタイムアウトする。
サーバー側
次に{:discover, person}メッセージとともに呼び出されて発見プロセスを生成するハンドラーを作ろう。
def handle_call({:discover, person}, _from, state) do
%{discovery_services: discovery_services} = state
state = %{state | tasks: spawn_discovery(person, discovery_services)}
handle_discovery(person, state)
end
defp spawn_discovery(person, discovery_services) do
_spawn_discovery(person, discovery_services, [])
end
defp _spawn_discovery(_person, [], tasks), do: tasks
defp _spawn_discovery(person, [service | rest], tasks) do
{:ok, pid} = Task.start(service, :discover_email, [person, self])
task = %Task{pid: pid, ref: Process.monitor(pid)}
_spawn_discovery(person, rest, tasks ++ [task])
end
そして、引数{:discover, person}をとるhandle_call/3は関数spawn_discovery/2を呼び出す。spawn_discovery/2は発見サービスモジュール全てについて再帰的になめていく。引き渡される発見サービスモジュールのリストはGenServerが起動したときにサービスモジュールごとに対応して生成されたTaskのリストである。そのリストが返されて現在の状態に集約される。これからPersonと現在の状態からすぐに定義されるhandle_discovery/2を呼び出す。
もしあなたがTaskに慣れていたらどうしてProcess.monitor/1を呼んでくれるTask.async/3を使わずにTask.start/3を使ったのか戸惑うかもしれない。理由はTask.start/3は親プロセスにリンクを作ってしまうからだ。ここでの親プロセスはタスクを起動するDiscovererだ。ということはTaskがもしもクラッシュしてしまったら(そのように設計してあるんだが)、Discovererもクラッシュしてしまう。そういうの以外の方法でクラッシュを取り扱いたいので道連れでクラッシュされるのはまずい。つまりリンクを作らないTask.start/1しか使えない。プロセスは我々の方でモニターすることにする。
さて、プロセスを立ち上げた後、そのレスポンスを処理しなければならない。それはhandle_discovery/2で行われる。
def handle_discovery(person, %{tasks: [], discovery_services: discovery_services}) do
{:reply, person, %{discovery_services: discovery_services}}
end
def handle_discovery(person, state) do
receive do
{:discovered, person} ->
{:reply, person, state}
{:DOWN, ref, _, _, _} ->
remaining_tasks = Enum.reject(state[:tasks], &(&1.ref == ref))
handle_discovery(person, %{state | tasks: remaining_tasks})
end
end
handle_discovery/2にマッチする節が2つある。1つはタスクが空であるという値に対応するものでもう片方はそれ以外の全てをキャッチする。まず後の方から始めよう。この関数節に来た、ということはまだ何かレスポンスを返してきていないタスクがあるということだ。なぜなら(前の方の関数節でタスクが空なものは引っ掛けられるから)タスクリストが空ではないことはわかっているから。これを踏まえて即座にメッセージ受信を実施し、メールアドレス発見サービスのどれかからレスポンスが返ってくるのを待ち受ける。期待値は次の2通りのメッセージだ。もし{:discovered, person}を受信したら発見サービスはメールアドレスを見つけてPersonの中に書き込んでいる。もし{:DOWN, ref, ...}を受け取ったら発見サービスはクラッシュしているわけだからタスクリストからそれを削除しhandle_discovery/2を再帰的に呼び出す。もし{:discovered, person}メッセージがずっと来なかったらタスクリストが空になるまでこの再帰呼び出しを続け、最初に受け取ったpersonと同じpersonを(空のメールアドレス値とともに)返すことになる。
以上をまとめると、最終的にモジュールはこんな感じになる。
defmodule Discoverer do
use GenServer
def start(discovery_services \\ [Jigsaw]) do
GenServer.start(__MODULE__, %{discovery_services: discovery_services,
tasks: []})
end
def discover(pid, person) do
discovery_timeout = Application.get_env(:email_discovery, :discovery_timeout)
GenServer.call(pid, {:discover, person}, discovery_timeout)
end
def discovery_services(pid) do
GenServer.call(pid, :discovery_services)
end
def handle_call(:discovery_services, _, state) do
{:reply, state[:discovery_services], state}
end
def handle_call({:discover, person}, _from, state) do
%{discovery_services: discovery_services} = state
state = %{state | tasks: spawn_discovery(person, discovery_services)}
handle_discovery(person, state)
end
def handle_discovery(person, %{tasks: [], discovery_services: discovery_services}) do
{:reply, person, %{discovery_services: discovery_services}}
end
def handle_discovery(person, state) do
receive do
{:discovered, person} ->
{:reply, person, state}
{:DOWN, ref, _, _, _} ->
remaining_tasks = Enum.reject(state[:tasks], &(&1.ref == ref))
handle_discovery(person, %{state | tasks: remaining_tasks})
end
end
defp spawn_discovery(person, discovery_services) do
_spawn_discovery(person, discovery_services, [])
end
defp _spawn_discovery(_person, [], tasks), do: tasks
defp _spawn_discovery(person, [service | rest], tasks) do
{:ok, pid} = Task.start(service, :discover_email, [person, self])
task = %Task{pid: pid, ref: Process.monitor(pid)}
_spawn_discovery(person, rest, tasks ++ [task])
end
end
よし、いい感じ。残ってるのはZoomInfoモジュールの作成とそれをDiscoverer.start/2のデフォルト値に追加するだけだ。
defmodule ZoomInfo do
import ZoomInfo.Settings
def discover_email(%Person{name: name, company: company}) do
query = %{api_token: api_token,
firstName: name.given_name,
lastName: name.family_name,
companyName: company}
url = api_base_url <> URI.encode_query(query)
HTTPotion.get(url, timeout: Application.get_env(:zoominfo, :timeout))
|> process_response
end
defp process_response(%{status_code: 200, body: body}) do
body
|> to_string
|> Poison.decode!
|> extract_email
end
defp extract_email(%{"PeopleSearchRequest" => %{"PeopleSearchResults" => %{"PersonRecord" => records}}}) do
_extract_email(records)
end
defp _extract_email([record | _]), do: _extract_email(record)
defp _extract_email(%{"Email" => email}), do: email
end
Jigsawとかなり似てるということに気づくだろう。リクエストのフェーズでの違いはクエリの中にキーの名前が入っていることだけだ。両者が違ってくるのはメール関連部分の取り出し方のところからだ。ZoomInfo APIにはPersonRecordキーがありその値は単一のレコードまたはレコードのリストになっている。両方を扱うために私はまた再帰的パターンマッチングで双方のケースにおいてどういう処理をするか宣言している。
ではDiscovery.start/2をちょっと書き換えてZoomInfoもデフォルトの発見モジュールとして使うようにする。そして完成!
def start(discovery_services \\ [Zoominfo, Jigsaw]) do
GenServer.start(__MODULE__, %{discovery_services: discovery_services, tasks: [])
end
宿題
- パターンマッチングを使ってあなたの「うまくいく(または扱える)道筋」を宣言してみよう。
- 潜在的なエラーについて率直に考えてみよう(マッチしなかった事柄のことである)
- 全てのケースについて考えることはできないのだから一般的な方法でエラーを処理しよう(クラッシュさせちまってね)
- モニタリングを介してプロセスのクラッシュを優しく取り扱おう。
-
ここでは[Jigsaw]。引数discovery_services(サービスのリスト)がない場合は[Jigsaw]が使われる。 ↩