リカレントニューラルネットワーク言語モデル
リカレントニューラルネットワーク言語モデル(ニューラル言語モデル)についてChainerのコードを使って解説してみました。
GPUについて
言語処理はすごく時間がかかるのでGPU設定をおススメしています。
しかし一概に使えば良いということではなく下記のような設定では有効に働きます。
詳細な仕組みの中身を知りたい方は下記をご覧ください。
http://www.kumikomi.net/archives/2008/06/12gpu1.php?page=1
*得意
行列計算
メモリにシーケンシャルにアクセスし、かつ条件分岐の無い計算(演算密度の高い処理)に強い。
*苦手
二分探索
メモリにランダムアクセスし、かつ条件分岐が多い。
GPUドライバ設定
AWSでのGPU設定は下記のサイトを参考に行いました。
apt-get update && apt-get install build-essential
Cudaのインストーラーを取得
wget http://developer.download.nvidia.com/compute/cuda/6_5/rel/installers/cuda_6.5.14_linux_64.run
Cudaのインストーラーのみ取得
chmod +x cuda_6.5.14_linux_64.run
mkdir nvidia_installers
./cuda_6.5.14_linux_64.run -extract=`pwd`/nvidia_installers
image-extractを取得
sudo apt-get install linux-image-extra-virtual
再起動
reboot
ファイルを作成
vi /etc/modprobe.d/blacklist-nouveau.conf
nouveauとlbm-nouveauの起動しないように設定
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
Kernel Nouveauを起動しないように設定
echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
カーネル起動時にあらかじめメモリに展開することでファイルシステムを構成する設定をしてから再起動
update-initramfs -u
reboot
カーネルのソースを取得
apt-get install linux-source
apt-get install linux-headers-3.13.0-37-generic
NVIDIAのドライバをインストール
cd nvidia_installers
./NVIDIA-Linux-x86_64-340.29.run
下記のエラー対応
NVIDIA driver install - Error: Unable to find the kernel source tree
sudo apt-get install linux-headers-`uname -r`
下記のコマンドでドライバがインストールされたかを確認する。
nvidia-smi
Wed Aug 5 07:48:36 2015
+------------------------------------------------------+
| NVIDIA-SMI 340.29 Driver Version: 340.29 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GRID K520 Off | 0000:00:03.0 Off | N/A |
| N/A 54C P0 80W / 125W | 391MiB / 4095MiB | 99% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Compute processes: GPU Memory |
| GPU PID Process name Usage |
|=============================================================================|
| 0 8013 python 378MiB |
+-----------------------------------------------------------------------------+
上記のGPUに振られている番号がGPUのIDである。これは後でChainerを動作させるときに使用する。
Pythonの設定
Python3の設定を行いました。
下記のコマンドを実行して事前に必要なものをインストールしておく
apt-get update
apt-get install gcc gcc++ kmod perl python-dev
sudo reboot
pip導入手順
https://pip.pypa.io/en/stable/installing.html
Pyenv導入手順
https://github.com/yyuu/pyenv
pip install virtualenv
pyenv install 3.4
virtualenv my_env -p = ~/.pyenv/versions/3.4.0/bin/python3.4
requirement.txtの設定を行いました。
numpy
scikit-learn
Mako
six
chainer
scikit-cuda
必要なライブラリをインストール
pip install -r requirement.txt
下記から"install-headers"をダウンロードしてくる。
PyCudaのインストール
wget https://pypi.python.org/packages/source/p/pycuda/pycuda-2015.1.2.tar.gz
tar zxvf pycuda-2015.1.2.tar.gz
cd pycuda-2015.1.2
./configure.py
make
make install
Chainer リカレントニューラル言語モデル サンプルコード
コード構成図
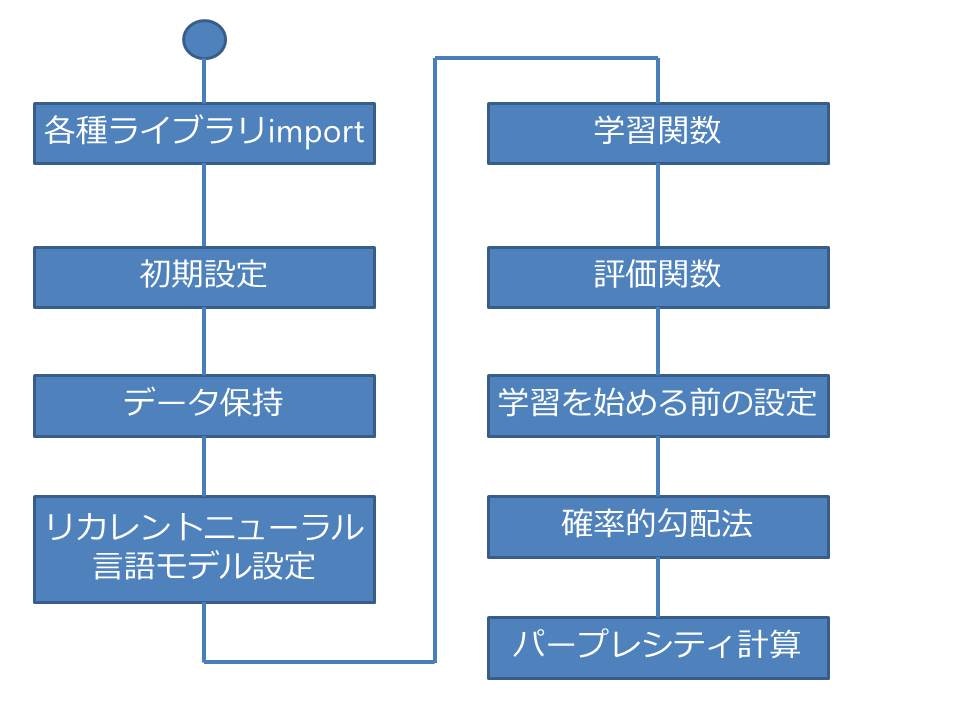
各種ライブラリをインポート
# !/usr/bin/env python
"""Sample script of recurrent neural network language model.
This code is ported from following implementation written in Torch.
https://github.com/tomsercu/lstm
"""
import argparse
import math
import sys
import time
import numpy as np
import six
import chainer
from chainer import cuda
import chainer.functions as F
from chainer import optimizers
初期設定
・引数でGPUを使用するかどうかを判断しています。
・GPUが指定されればcudaを実行するように設定されています。
・学習回数、ユニット数、確率的勾配法に使用するデータの数、学習に使用する文字列の長さ、勾配法で使用する敷居値を設定しています。
parser = argparse.ArgumentParser()
parser.add_argument('--gpu', '-g', default=-1, type=int,
help='GPU ID (negative value indicates CPU)')
args = parser.parse_args()
mod = cuda if args.gpu >= 0 else np
n_epoch = 39 # number of epochs
n_units = 650 # number of units per layer
batchsize = 20 # minibatch size
bprop_len = 35 # length of truncated BPTT
grad_clip = 5 # gradient norm threshold to clip
データ保持
予めdownload.pyでダウンロードしたファイルをプログラムに読ませる処理を関数化しています。
・最終文字を改行から<eos>に変更しています。<eos>は最終文字を表す明示的な物なので改行コードを置き換えて明示的に最終文字にしています。
・文字データを確保するための行列を定義しています。
・データを単語をキー、長さを値とした辞書データにして行列データセットに登録しています。
学習データ
validデータ
テストデータ
上記をそれぞれ行列データとして保持しています。
# Prepare dataset (preliminary download dataset by ./download.py)
vocab = {}
def load_data(filename):
global vocab, n_vocab
words = open(filename).read().replace('\n', '<eos>').strip().split()
dataset = np.ndarray((len(words),), dtype=np.int32)
for i, word in enumerate(words):
if word not in vocab:
vocab[word] = len(vocab)
dataset[i] = vocab[word]
return dataset
train_data = load_data('ptb.train.txt')
valid_data = load_data('ptb.valid.txt')
test_data = load_data('ptb.test.txt')
print('#vocab =', len(vocab))
リカレントニューラル言語モデル
RNNLM(リカレントニューラル言語モデルの設定を行っています)
・辞書データを、入力ユニット数分のデータに変換する処理(潜在ベクトル空間への変換)を行っています。
・出力が4倍の理由はLSTMを使用しているため、出力、入力制御、忘却、出力制御を行うために用いられています。
・初期のパラメータを-0.1〜0.1の間で与えています。
・GPUの引数が一つ以上ならば、cudaの初期化とモデルをGPUに適用させる処理を行っています。
# Prepare RNNLM model
model = chainer.FunctionSet(embed=F.EmbedID(len(vocab), n_units),
l1_x=F.Linear(n_units, 4 * n_units),
l1_h=F.Linear(n_units, 4 * n_units),
l2_x=F.Linear(n_units, 4 * n_units),
l2_h=F.Linear(n_units, 4 * n_units),
l3=F.Linear(n_units, len(vocab)))
for param in model.parameters:
param[:] = np.random.uniform(-0.1, 0.1, param.shape)
if args.gpu >= 0:
cuda.init(args.gpu)
model.to_gpu()
学習関数の設定
1ステップ前方処理関数:学習データ、ラベル、状態を与える
・GPU指定があれば、cuda用のデータに変換する
・学習用データを作成(特徴量データ、ラベルデータ)
・特徴ベクトルはBag of wordsの形式なので潜在ベクトル空間に圧縮する
・過学習をしないようにランダムに一部のデータを捨て、過去の状態のも考慮した第一の隠れ層を作成
・LSTMに現在の状態と先ほど定義した隠れ層を付与して学習し、隠れ層と状態を出力
・2層目も1層目と同様の処理を行う
・ラベルは3層目の処理で出力された値を使用する。
状態の初期化:確率的勾配法に必要なデータを与え、学習データと認識させる
各隠れ層と値を通すか判断するcの値を0で必要なデータ分初期化する
# Neural net architecture
def forward_one_step(x_data, y_data, state, train=True):
if args.gpu >= 0:
x_data = cuda.to_gpu(x_data)
y_data = cuda.to_gpu(y_data)
x = chainer.Variable(x_data, volatile=not train)
t = chainer.Variable(y_data, volatile=not train)
h0 = model.embed(x)
h1_in = model.l1_x(F.dropout(h0, train=train)) + model.l1_h(state['h1'])
c1, h1 = F.lstm(state['c1'], h1_in)
h2_in = model.l2_x(F.dropout(h1, train=train)) + model.l2_h(state['h2'])
c2, h2 = F.lstm(state['c2'], h2_in)
y = model.l3(F.dropout(h2, train=train))
state = {'c1': c1, 'h1': h1, 'c2': c2, 'h2': h2}
return state, F.softmax_cross_entropy(y, t)
def make_initial_state(batchsize=batchsize, train=True):
return {name: chainer.Variable(mod.zeros((batchsize, n_units),
dtype=np.float32),
volatile=not train)
for name in ('c1', 'h1', 'c2', 'h2')}
更新幅を1に設定して確率的勾配法による最適化を行うように設定している。
# Setup optimizer
optimizer = optimizers.SGD(lr=1.)
optimizer.setup(model.collect_parameters())
評価関数の設定
評価の関数
1:状態の初期化と損失の初期化
2:データのサイズ分確率的勾配法に基づいて更新していく
3:損失の平均値をexp関数に与えて返す。(低い値でも0にならないのが特徴で正の値だと急激に増えるため損失が大きい時には有効に働く)
# Evaluation routine
def evaluate(dataset):
sum_log_perp = mod.zeros(())
state = make_initial_state(batchsize=1, train=False)
for i in six.moves.range(dataset.size - 1):
x_batch = dataset[i:i + 1]
y_batch = dataset[i + 1:i + 2]
state, loss = forward_one_step(x_batch, y_batch, state, train=False)
sum_log_perp += loss.data.reshape(())
return math.exp(cuda.to_cpu(sum_log_perp) / (dataset.size - 1))
学習処理を始める前の設定
・学習データのサイズを取得
・ジャンプの幅を設定(順次学習しない)
・パープレキシティを0で初期化
・最初の時間情報を取得
・初期状態を現在の状態に付与
・状態の初期化
・損失を0で初期化
# Learning loop
whole_len = train_data.shape[0]
jump = whole_len // batchsize
cur_log_perp = mod.zeros(())
epoch = 0
start_at = time.time()
cur_at = start_at
state = make_initial_state()
accum_loss = chainer.Variable(mod.zeros(()))
print('going to train {} iterations'.format(jump * n_epoch))
確率的勾配法を用いた学習
確率的勾配法を用いて学習している。
一定のデータを選択し損失計算をしながらパラメータ更新をしている。
逐次尤度の計算も行っている。
for i in six.moves.range(jump * n_epoch):
x_batch = np.array([train_data[(jump * j + i) % whole_len]
for j in six.moves.range(batchsize)])
y_batch = np.array([train_data[(jump * j + i + 1) % whole_len]
for j in six.moves.range(batchsize)])
state, loss_i = forward_one_step(x_batch, y_batch, state)
accum_loss += loss_i
cur_log_perp += loss_i.data.reshape(())
・バックプロパゲーションでパラメータを更新する。
・truncateはどれだけ過去の履歴を見るかを表している。
http://kiyukuta.github.io/2013/12/09/mlac2013_day9_recurrent_neural_network_language_model.html#recurrent-neural-network
・L2正規化をかけている。
if (i + 1) % bprop_len == 0: # Run truncated BPTT
optimizer.zero_grads()
accum_loss.backward()
accum_loss.unchain_backward() # truncate
accum_loss = chainer.Variable(mod.zeros(()))
optimizer.clip_grads(grad_clip)
optimizer.update()
学習データのパープレキシティの計算(9999回に1回行う)し、表示する。
if (i + 1) % 10000 == 0:
now = time.time()
throuput = 10000. / (now - cur_at)
perp = math.exp(cuda.to_cpu(cur_log_perp) / 10000)
print('iter {} training perplexity: {:.2f} ({:.2f} iters/sec)'.format(
i + 1, perp, throuput))
cur_at = now
cur_log_perp.fill(0)
バリデーションデータのパープレキシティの計算(バリデーションの幅によって異なる)し表示する
if (i + 1) % jump == 0:
epoch += 1
print('evaluate')
now = time.time()
perp = evaluate(valid_data)
print('epoch {} validation perplexity: {:.2f}'.format(epoch, perp))
cur_at += time.time() - now # skip time of evaluation
if epoch >= 6:
optimizer.lr /= 1.2
print('learning rate =', optimizer.lr)
sys.stdout.flush()
評価
テストデータに対するパープレキシティの計算
# Evaluate on test dataset
print('test')
test_perp = evaluate(test_data)
print('test perplexity:', test_perp)
参考サイト一覧
言語モデルのカバレージ、パープレキシティの説明
ディープラーニングフレームワークChainerをEC2のGPUインスタンスで動かす g2.2xlarge instance
Drop Out
Learning to forget continual prediction with lstm
Zaremba, Wojciech, Ilya Sutskever, and Oriol Vinyals. "Recurrent neural network regularization." arXiv preprint arXiv:1409.2329 (2014).
Google Mikolov
Neural Network(NN)を利用したLanguage Model(LM),つまりNeural Network Language Model(NNLM)の一種であり, Recurrent Neural Network(RNN)を使ったRecurrent Neural Network Language Model(RNNLM)
Long Short-term Memory
Chainerのptbサンプルを解説しつつ、自分の文章を深層学習させて、僕の文章っぽい文を自動生成させてみる
RNNLM
スパース推定概観:モデル・理論・応用
正則化学習法における最適化手法
リカレントニューラル言語モデル作成参考
https://github.com/yusuketomoto/chainer-char-rnn
ニューラルネット 自然言語処理
http://www.orsj.or.jp/archive2/or60-4/or60_4_205.pdf
言語モデル作成
http://www.slideshare.net/uchumik/rnnln
自然言語処理プログラミング勉強会n-gram言語モデル
http://www.phontron.com/slides/nlp-programming-ja-02-bigramlm.pdf
Statistical Semantic入門 ~分布仮説からword2vecまで~
http://www.slideshare.net/unnonouno/20140206-statistical-semantics
linux source code
https://github.com/torvalds/linux
なぜGPUコンピューティングが注目を浴びているか - 慶應義塾 http://www.yasuoka.mech.keio.ac.jp/gpu/gpu_0.php
CUDA技術を利用したGPUコンピューティングの実際(前編) ―― グラフィックス分野で磨かれた並列処理技術を汎用数値計算に応用
http://www.kumikomi.net/archives/2008/06/12gpu1.php?page=1
GPGPU
https://ja.wikipedia.org/wiki/GPGPU#.E7.89.B9.E5.BE.B4.E3.81.A8.E8.AA.B2.E9.A1.8C