はじめに
クラスタリングとハッシュラーニングの部分を完全に理解することはできませんでした。有識者の方がいれば教えて欲しい・・・
対象読者
教師なし学習で分類を行いたい方。一般的な機械学習の知識、コンピューターサイエンスの知識がある方が対象になります。
背景
- 教師データが用意できないタスクがある。
- 教師データが少量しか用意できないタスクがある。
- 教師なしデータはある。
上記の状況で有効な手法を探すために下記の論文を読みました。
Hu, Weihua, et al. "Learning Discrete Representations via Information Maximizing Self Augmented Training." arXiv preprint arXiv:1702.08720 (2017).
選んだ理由
- 精度が高い
- コードが公開されていて再現できそう
手法
ベースとなる手法
クラスタリング
教師なしの分類で一般的に使われる手法
ハッシュラーニング
大きな情報に対して近侍近傍探索で使われる手法。情報をハッシュによって近侍的な空間に写像することによって探索などを簡易的に行えるようにする手法です。
Wang, Jun, Liu, Wei, Kumar, Sanjiv, and Chang, Shih-Fu. Learning to hash for indexing big data—a survey. Pro- ceedings of the IEEE, 104(1):34–57, 2016.
IMSAT:Information Maximizing Self-Augmented Training
本論文で提唱されている手法はIMSATという手法になります。
Information Maximizing(以下IM):情報量の最大化
Self-Augmented Training(以下SAT):汎化性能を上げるためにData Augmentationを加える
RIMという手法が元になっており、違いはハッシュラーニングを利用した距離空間の学習、深層学習を用いた空間へのマッピング、SATを用いて汎化性能を向上している点です。
Gomes, Ryan, Krause, Andreas, and Perona, Pietro. Dis- criminative clustering by regularized information maxi- mization. In NIPS, 2010.
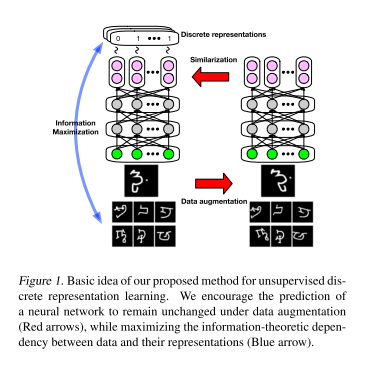
問題設定は入力情報の空間と出力情報の空間の情報量を最大化する学習することにしています。図だと左側
下記の条件付き確率を学習することになります。
p_\theta(y|x)
yは出力空間を表し、クラスタリングする数存在していることとします。
X \in \it{X} \\
Y \equiv {0,...K-1} \\
最初の出力はランダムで下記の式を最小化するように学習します。
R(\theta) - \lambda I(X;Y)
最初の項は正則化項で次の項が入力と出力の空間の相互情報量で相互情報量が最大になるときに上記の式が最小になります。
相互情報量は一方の変数を知った時にもう一方の変数をどれだけ推測可能にできるかの尺度になります。
RIMについて
出力空間がM次元の離散空間として
Y \equiv {y_1 \times ... \times y_M} \\
上記の個々の空間は下記のように表し
y_m \equiv {0,...V_{m}-1} \\
1 \leqq m \leqq M
Y = (Y_1,..,Y_M)
になるので条件付確率により入力から出力空間を表すと
p_\theta(y_1,..,y_M|x) = \prod^{M}_{m=1}{p_\theta(y_m|x)}
SATによる正則化について
正則加項の計算になります。Data Augmentationにより汎化性能を上げる手法になります。
下記の式で表されます。
R_{SAT}(\theta;x,T(x)) = - \sum^M_{m=1}\sum^{V_m-1}_{y_m=1}p_\hat{\theta}(y_m|x)\log p_{\theta}(y_m|T(x))
下記の項はオリジナルのデータに適用します。
p_\hat{\theta}(y_m|x)
下記の項はData Augmentationされたデータに適用します。
\log p_{\theta}(y_m|T(x))
全てのデータに適用すると下記のようになります。
R_{SAT}(\theta;T) = - \frac{1}{N}\sum^N_{n=1} R_{SAT}(\theta; x_n, T(x_n))
Data Augmentationはデータに微小な変化を加えることを意味するので下記の式で表せます。
T(x) = x + r
微小な変化は深層学習において識別性能に大きな影響を与えることが知られています。そこでVirtual Adversarial Training(VAT)の仕組みを入れて汎化性能を向上させます。
先ほど設定したrの中で最も汎化性能を向上させるようなrを選択する式は下記になります。
r = \arg \max_{r'}{R_{SAT}(\hat{\theta} ; x, x + r'); \|r'\|_2 \geq \varepsilon}
IMSATによるクラスタリング
この部分は論文読んでも分からなかったです・・・
最初の式の相互情報量部分を分解して下記の式にします。
\theta
は各クラスの識別士
R(\theta) - \lambda [H(Y) - H(Y|X)]
さらに分解して記述すると
H(Y) = h(p_\theta(y)) = h(\frac{1}{N}\sum^{N}_{i=1}{p_\theta(y|x)})\\
H(Y|X) = \frac{1}{N}\sum^{N}_{i=1}{h(p_{\theta}(y|x_i))} \\
hはエントロピーの関数
h(p(y)) = - \sum_{y'}\log p(y')
H(Y)は書き換えると下記のようにも記述できる。Kはクラスタリングクラスの数でUは単一分布である。MNISTのデータの分布は一様なので単一分布
H(Y) = \log K - KL[p_\theta(y) || U]
カルバックラー距離の最小化がエントロピーの最大化に繋がるので
p_\theta(y)
は単一分布に近くことになる。
p_{\theta}(y)
を
q(y)
に近づけるには下記のような制約付きの問題を解くことになる。
TはAugment関数
q(y)は特定のクラスへの確率
\min_{\theta}{R_{SAT}(\theta ; T) + \lambda H(Y|X)} \\
KL[p_{\theta}(y) || q(y)] \leq \delta
δはハイパーパラメータ
IMSAT ハッシュラーニング
この部分もよく分からなかった
相互情報量部分をDビットのバイナリコードに写像します。
相互情報量は交互情報量の和で表せるので
I(Y_1,...Y_D;X) = \sum_{C \subseteq S_Y}{I(C \cup X)} , |C| \geq 1
Data augmentationされたデータの出力空間も考慮すると
\sum^{D}_{d=1}{I(Y; X)} + \sum_{1 \leq d \neq d' \leq D}{I({Y_d, Y_{d'}; X})}
第2項は書き換えると
I({Y_d,Y_{d'},X}) = I(Y_d;Y_{d'}|X) - I(Y_d;Y_{d'})= - I(Y_d;Y_{d'})
通常の入力に対する出力とData augmentationされた入力データを条件とした出力の依存関係は独立なので最初の項が消える。
最終的にDビットのバイナリ空間に写像された情報量を導出することになるので
R_{SAT}(\theta;x,T(x)) - \lambda( \sum^{D}_{d=1}{I(Y; X)} - \sum_{1 \leq d \neq d' \leq D}{I({Y_d; Y_{d'}})} )
最初の項は正則化、次の項はハッシュビットにマッピングした相互情報量、最終項は重複されたハッシュビットの削除の役割をもつ
周辺分布の近似
相互情報量の計算の際に周辺分布の計算が必要になりますが今回はミニバッチのサイズに抑えた近似された周辺分布を用いいます。
p_{\theta}(c) \approx \frac{1}{|\beta|}\sum_{x\in\beta}{p_{\theta}(c|x)} \equiv \hat{p}^{\beta}_{\theta}(c)
実験結果
条件
- ハイパーパラメータはクロスバリデーションで決定
- ニューラルネット
- 入力d次元、中間1200,1200, 最終層M次元
- Reluを活性化関数
- クラスタリング:softmax
- ハッシュラーニング:sigmoid
- Optimizer: Adam
- 実装詳細
クラスタリングの実験に使用したデータ
クラスタリングの結果
実験結果の用語の説明は下記
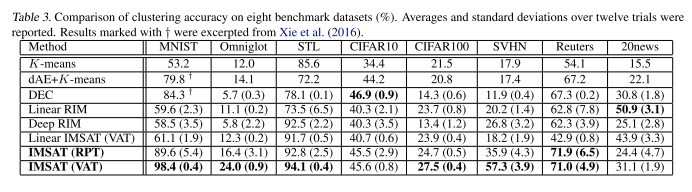
RIM(Regularized Information Maximization)
RPT(ランダムにData augmentationをかける)
VAT(VATの評価関数に基づいてData augmentationをかける)
評価方法
ACC = max_{m}\frac{\sum^{N}_{n=1}1(l_n = m(c_n))}{N}
mでクラスタリングで与えられた出力をラベルに割り当てる。上記の式の値が最大になるようにハンガリアンアルゴリズムで最適化したマッピングのmが選ばれる
ハイパーパラメータチューニング
Augmentationをかける敷居値のεのレンジを下記の式で導出する
\varepsilon = \alpha \cdot \sigma_t(x)
αはスカラー値
tは10で固定
シグマはユークリッド距離
入力xに対するユークリッド距離の近い候補から10番目のユークリッド距離の値を採用しています。
ハッシュラーニング
下記の論文に基づいて
1: 出力結果とハッシュコードの損失が最小になるように学習
2: ハッシュコードの分布は全てのビットを用いて生成される
3: 各ビットは他のビットに依存せずに学習
Dilokthanakul, Nat, Mediano, Pedro AM, Garnelo, Marta, Lee, Matthew CH, Salimbeni, Hugh, Arulkumaran, Kai, and Shanahan, Murray. Deep unsupervised clustering with gaussian mixture variational autoencoders. arXiv preprint arXiv:1611.02648, 2016
下記の構成のネットワークを16または32ビットのハッシュコードで学習しています。
- ニューラルネット
- 入力d次元、中間200,200, 最終層M次元
- 入力d次元、中間400,400, 最終層M次元
- 入力d次元、中間60,30, 最終層M次元
- 入力d次元、中間80,50, 最終層M次元
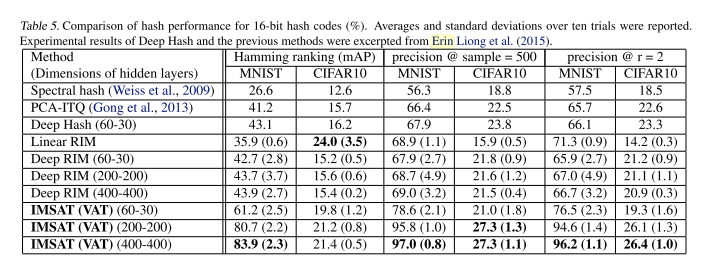
結果
データ
- MNIST
- CIFAR10
評価
- mean average precision(平均のprecisionの値)
- 500 sample precision
- Hamming look up result(エラー検知のハミングコードの間違い)
近くのクラスをラベルとして10回の値の平均値
コードの感想
Chainerでできる便利な誤差逆伝搬の書き方
損失を使って誤差逆伝搬
(loss_ul + args.lam * loss_eq).backward()
LSTMなどで過去の値を消すのに使用される。(大きな入力が来た場合に対応するため)
下記の実装がKerasだと分からない・・・
loss_ul.unchain_backward()
参考
https://arxiv.org/pdf/1702.08720.pdf
http://musyoku.github.io/2016/12/10/Distributional-Smoothing-with-Virtual-Adversarial-Training/
https://r2rt.com/styles-of-truncated-backpropagation.html