キーワードマッチングを超えた知識を利用する価値
人間間の会話では"Twitter"や"Facebook"がSNSだなと分かって会話ができたり、"ヤマハ"と言われても前後の文脈で"ヤマハ"がバイクの"ヤマハ"かピアノの"ヤマハ"か分かります。
これは単語の背景に関連する知識情報を利用できているからです。
この単語を知識情報と繋げる手法として近年の自然言語処理ではエンティティリンキングという手法がよく用いられています。

コードを使ってすぐに確認したい方は下記でインストールしてください。
コード:
必要なデータ:
- 分析したいデータ
- Wikificatation
- 日本語 Wikipedia エンティティベクトル
ユースケース
これを実際に使用する場合に下記のようなユースケースが考えられます。
1:サジェスト
キーワード検索する際にその単語と関連する語が出てくれば検索が容易になり、ユーザーにとってもメリットができます。

2:対話インターフェース
対話で発せられる文章は短いため情報が少ないです。この少ない情報から高度な回答をするには単語だけでなく関連する知識へとリンクすることが必須になります。
3:Twitterからの情報抽出
Twitterのつぶやきも情報が少ないので、単純なキーワードを用いるだけで有用な情報抽出には使用しづらいのが現状です。キーワードを関連する知識と紐づければ、キーワードマッチングでは取得できなかった有用な情報を取得することにも繋がります。

エンティティリンキングとは
ACLという自然言語処理のトップのカファンレンスでも課題に上がるほど注目されている手法です。
単純なキーワードと知識を繋げる手法、繋げ方は詳細な情報を含んだリンクでも補足情報を含んだサマリ情報でも良いです。
重要な点は2点です。
1:テキストから重要と思われるキーワードのみ抽出
2:キーワードと関連する情報を繋げる
テキストから重要と思われるキーワードのみ抽出
一般的に重要と思われる単語はWikificatationを用いてキーワードマッチングすれば抽出可能ですが、単純に動作させたい場合はmecabで固有名詞のみ抽出すれば試すことは可能です。
本来はこのキーワードが有用かそうでないかの判断をする機械学習のモデルを挟む必要がありますが、今回紹介する記事では述べません。詳細を知りたい方は下記の資料をご覧ください
キーワードと関連する情報を繋げる
単純にキーワードをWikiPediaまたはDBPediaとマッチングさせてマッチングしたリンク先の情報を使用するのも手法としてあります。
仮にマッチングするのがベクトル空間の場合、計算によって様々な操作が可能になり、用途が広がります。それを可能としているのが今回、紹介する日本語 Wikipedia エンティティベクトルです。
Word2Vecの発展させた手法なので、中身が分かれば応用が可能なので詳細を知りたい方は論文を読むことをお勧めします。読まなくてもベクトル計算後のデータはすでに用意してくれているので時間がない方はそちらを使ってもらっても問題ないと思います。
日本語 Wikipedia エンティティベクトルの作成方法
非常にシンプルで分かりやすく作られています。
1:WikiPediaのデータをmecabなどで単語に区切る
2:WikiPedia中のハイパーリンクが付与された単語をリンク先のタイトルに置き換え
3:WikiPedia中にハイパーリンク付きの単語が再度現れる場合はハイパーリンクが付いていないので、付いているものとみなし2と同様の処理を行う。
4:得られた単語群を元にWord2Vecで学習を行う。
これによって固有表現を単語として抽出し、 実世界のエンティティに関連づけること(エンティティリンキング)が可能になります。
日本語 Wikipedia エンティティベクトルを利用した実装例
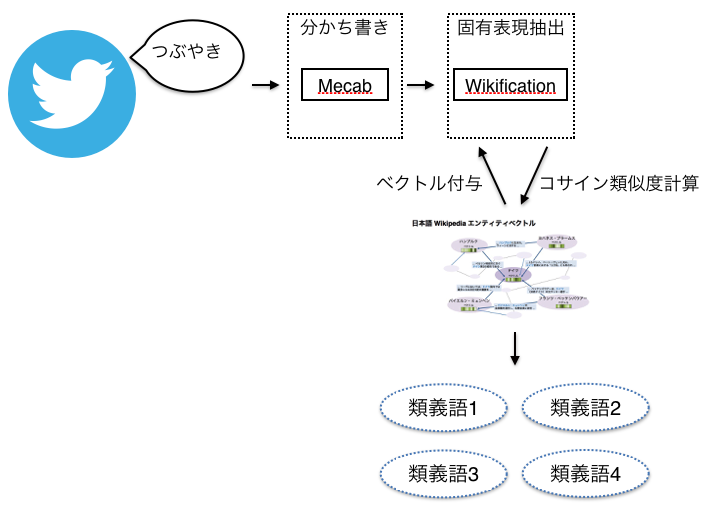
上記がシステムの実装例になります。
wikipediaエンティティベクトルを使用して単語から関連する語を取得してみます。
コードはgithubに載せているので、重要な部分のみ引用します。
1:Twitterのつぶやきを収集(今回はりんなのデータを使用)
2:分かち書きを行う
3:Wikificationで固有表現を抽出
4:日本語 Wikipedia エンティティベクトルでベクトルを付与
5:コサイン類似度を計算し類似度が高いものを類義語として付与
コードは単純なので下記をご覧ください。
高速化のための工夫
工夫1:OpenBlasを直接使用
コサイン類似度を計算していますが、計算コストが高いのでこの部分の高速化を試みます。
高速化のためにOpenBlasを使用している部分が難しいので解説を書いておきます。
Macでインストールする場合は下記のコマンドでインストールします。
brew install openblas
下記でどのディレクトリにopenblasのライブラリがあるか明記しておきます。
[openblas]
libraries = openblas
library_dirs = /usr/local/opt/openblas/lib
include_dirs = /usr/local/opt/openblas/include
Cython型で計算しているため、効果は不明ですが、まず下記のコードでコサイン類似度を計算するベクトルがのメモリーのレイアウトがCのスタイルかどうかをチェックします。
このチェックの理由はBlasがベクトルのメモリーのレイアウトがCのスタイルだった場合コピー処理を行うのですが、Fortranのスタイルの場合にも同様の処理を行わないことで余計な処理を除き高速化するためです。
def __force_forder(self, x):
"""
Converts array x to fortran order Returns a tuple in the form (x is transposed)
:param x(vector):
:return:
"""
if x.flags.c_contiguous:
return (x.T, True)
else:
return (x, False)
次に下記のコードでベクトルの内積を計算しています。ベクトルの型をチェックした後でCの型の場合は変換処理があること明記しておくことでベクトルの型がFortranの場合は変換処理が必要ではなく、高速に計算が可能になります。
def __faster_dot(self, A, B):
"""
Use blas libraries directory to perform dot product
Reference:
https://www.huyng.com/posts/faster-numpy-dot-product
http://stackoverflow.com/questions/9478791/is-there-an-enhanced-numpy-scipy-dot-method
:param A(mat): vector
:param B(mat): vector
:return:
"""
A, trans_a = self.__force_forder(A)
B, trans_b = self.__force_forder(B)
return FB.dgemm(alpha=1.0, a=A, b=B, trans_a=trans_a, trans_b=trans_b)
工夫2:スレッドベースの並列分散処理
コサイン類似度の計算もボトルネックになりますが、WikiPediaEntityVectorの登録されている単語数も多いため同様の処理を何度も行うと時間が非常にかかります。
Pythonは基本的にシングルプロセスで動作するためスレッドベースでの並列処理を実装して高速化を試みました。
Queueを用いたProducer Consumerパターンを使用しています。今回のケースはConsumerの処理が重いため、Consumerに与えるスレッド数を多くして高速化を試みました。
コンシューマーのサイズを設定して、そのサイズ分だけスレッドを生成して動作を行っています。
for index in range(args.consumer_size):
multi_thread_consumer_crawl_instance = threading.Thread(target=producerConsumer.consumer_run, name=consumer_name + str(index))
multi_thread_consumer_crawl_instance.start()
結果の例
元の固有表現:[計算により導出された類義語群]
下記を見ると単純なキーワードマッチで取ることが難しいが関連性の高い単語が取れていることが分かります。
'秋田': ['長野', '福島', '高知', '岩手', '山形', '新潟', '青森', '熊本', '盛岡'],
'百': ['百', '十', '千'],
'ゴジラ': ['ゴジラ_(1954年の映画)', 'ゴジラ_(架空の怪獣)', 'ガメラ'],
'3': ['4', '6', '5', '0', '7', '8', '9', '2', '1'],
'赤': ['紫', '緑色', '緑', '朱色', '黒', '赤色', '青色', '白', '黄色', '藍色', '青']
'豚': ['牛', '羊', 'ヒツジ', 'ニワトリ', 'ヤギ', '鶏', '山羊', 'ブタ', 'ウシ'],
'ゴルフ': ['ボウリング'],
'竹': ['柳', '松']
'5': ['4', '6', '0', '7', '3', '8', '9', '2', '1'],
'枝': ['茎', '葉', '枝は'],
'木': ['杉', '樫', '切り株', '松の木'],
'ふん': ['ぺん', 'ぎゅう'],
'学生': ['生徒', '大学生'],
'餅': ['饅頭', '徳利', '赤飯', '玉子', '神酒', '粥', 'アズキ', '団子'],
'腰': ['臀部', '膝', '踵', '肩'],
'髭': ['口髭', 'ひげ', '口ひげ', 'ヒゲ', '髭', '髪の毛', 'あごひげ'],
'猫': ['小鳥', 'ネコ', '仔猫', 'ネズミ'],
'中国': ['台湾', '朝鮮', '韓国', '中華人民共和国'],
'二つ': ['五つ', 'ふたつ', '2つ', '三つ'],
'浴衣': ['浴衣', '普段着', '白無垢', '喪服', '着物', 'タキシード', '普段着', '白無垢', '喪服', '着物', 'タキシード'],
'野球': ['ラグビー'],
'髪': ['頭髪', '黒髪', '長髪', '髭', '髪の毛', '前髪', '金髪', '髪型'],
'秋': ['秋', '夏', '春', '夏', '春'],
'奈良': ['和歌山']
注意点
固有表現はWikificationで表しているのでWikipediaに依存しています。
データの知識空間はWikiPediaに依存しています。
業界が特殊な場合やレアケースが多い場合は使用しない方がベターです。
日本語 Wikipedia エンティティベクトルはハイパーリンクの単語は"<<単語>>"で表されているので"<<>>"を除く処理が必要です。
メモリを多く消費します。
計算時間も非常に長いです。元の固有表現が192単語の場合はシングルプロセスでシングルスレッドで動作させると3時間程度かかりますが、固有表現ごとに同一の処理をしているため並列分散処理をすれば早くなります。
参考
Yamada123, Ikuya, Hideaki Takeda, and Yoshiyasu Takefuji. "Enhancing Named Entity Recognition in Twitter Messages Using Entity Linking." ACL-IJCNLP 2015 (2015): 136.
Faster numpy dot product for multi-dimensional arrays