Pybrainはニューラルネットワークの仕組みが実装されているPythonのライブラリです。
今回はチュートリアルに乗っている強化学習(Reinforcement Learning)をやったので備忘録の意味も込めて記述しておきます。
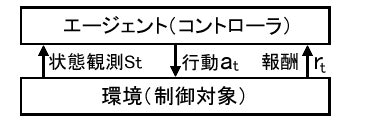
強化学習とは試行錯誤を通じて環境に適応する学習制御の枠組です。
例えば
新米セールスマンをエージェントとして、環境をお客さんとします。
その再に新米セールスマンがセールスする行動をアクション
セールスに対するお客様の反応を状態観測
それに対する”お客様の購買意欲が上がったか”を報酬とします。
新米セールスマンはセールスの経験がないので報酬つまり”お客様の購買意欲が上がったか”が正確なものか把握できません。
またセールスに対するお客様の反応も新米セールスマンは正確に把握することはできません。
このような不確実性の高く、教師データもないような状況で使われる強化学習がPOMDPと呼ばれます。
詳しい説明は下記を参照下さい(引用元:NTTコミュニケーション科学基礎研究所 南泰浩)
http://www.lai.kyutech.ac.jp/sig-slud/SLUD63-minami-POMDP-tutorial.pdf
下記のチュートリアルでは、観測された状態が正しいと仮定しているMDPを使用しています。
MDP(マルコフ決定過程)
http://www.orsj.or.jp/~wiki/wiki/index.php/%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E6%B1%BA%E5%AE%9A%E9%81%8E%E7%A8%8B
今回はこの枠組みを使用して迷路ゲームをクリアするためのチュートリアルをPythonで実践しました。
PyBrainの始め方は下記を参考にして下さい。
必要なライブラリをインストールします。
from scipy import *
import sys, time
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, SARSA
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task
ビジュアル化の準備をします。
import pylab
pylab.gray()
pylab.ion()
チュートリアルでは迷路ゲームのクリアを目標とするので下記のような迷路構造を定義します。
structure = array([[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]])
迷路構造を環境として定義します。
先ほど定義した迷路構造と最終ゴールを渡しておきます。
environment = Maze(structure, (7, 7))
次にエージェントのアクションを定義します。
エージェントのアクションは今回は値のテーブルを持つエージェントとし、81の状態と4つのアクションを持っています。
そしてエージェントの状態を初期化しておきます。
81状態:迷路構造が9×9構造のため
4アクション:上、下、右、下のアクションが可能なため
アクション定義用のインターフェースはActionValueTableとActionValueNetworkがあります。
ActionValueTable:離散的な行動の時に使用
ActionValueNetwork:連続的な行動の時に使用
controller = ActionValueTable(81, 4)
controller.initialize(1.)
エージェントの学習の仕組みを定義します。
Q学習を用いて、エージェントのアクションが報酬に対して最適化されるように定義しておきます。
learner = Q()
agent = LearningAgent(controller, learner)
エージェントと環境をつなげるタスクを定義します。
task = MDPMazeTask(environment)
下記のコードで実際に強化学習を100回実践し、実践ごとに再度エージェントの位置をプロットするようにしています。
experiment = Experiment(task, agent)
while True:
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(controller.params.reshape(81,4).max(1).reshape(9,9))
pylab.draw()
pylab.show()
以上で終わりです。