TOPIC MODEL をPythonで実装してみました
参考にさせて頂いたのは下記資料
NLP Programming Tutorial 7 -トピックモデル
http://www.phontron.com/slides/nlp-programming-ja-07-topic.pdf, (参照 2015-06-25)
TOPICモデルのざっくりした解説は下記をご参照ください。
Pythonで実装にあたって全体構成を記述しておきます。
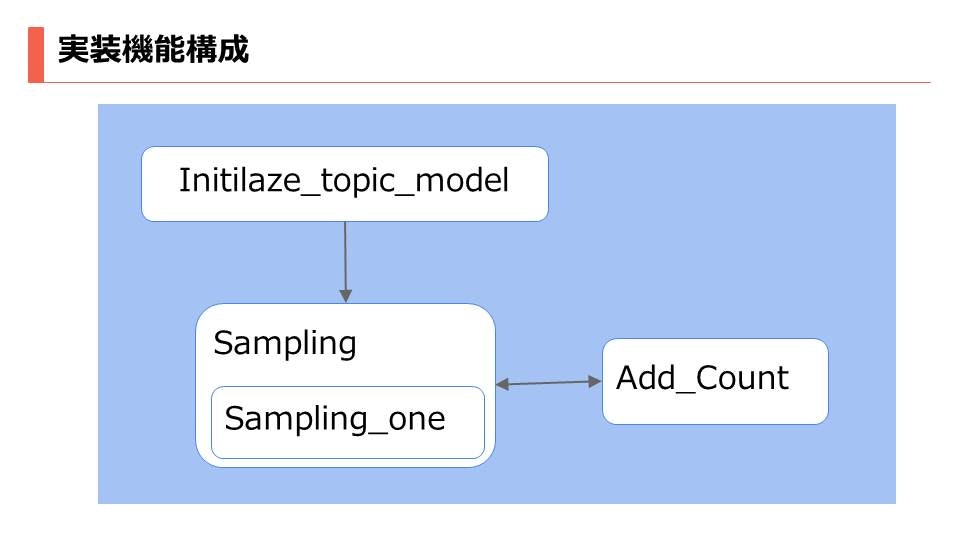
構成事態は難しくないので、簡単に実装できる気になってきたと思います。
TOPICモデルは一般的な機械学習と違って、ラベルにあたる文書のトピックが与えられていません。
その状況でどのようにトピックを推定するかを実践した手法です。
一般的には教師なし学習の手法を用います。
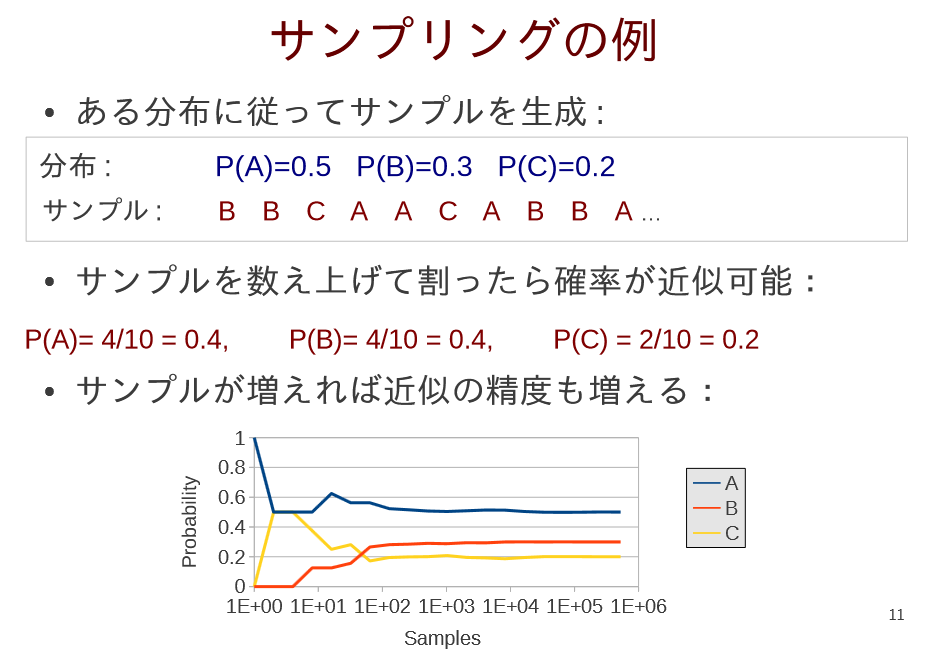
サンプリング
11ページ引用
NLP Programming Tutorial 7 -トピックモデル
http://www.phontron.com/slides/nlp-programming-ja-07-topic.pdf, (参照 2015-06-25)
下記が実装したコードです。
def sampleOne(probs):
z = 0
for k, v in probs.items():
z = z + v
remaining = random.uniform(0, z)
for k,v in probs.items():
remaining = remaining - v
if remaining <= 0:
return k
1.分布から得られたサンプルに対するトピックと確率の値を保持する辞書データを関数に渡します。
2.確率の値の総和を算出します。
3.0から確率の値の総和の値のレンジでランダムな値を一様分布によって取得します。(問題によってはこの分布を変更する)
4.ランダムな値から各確率の値を引いていき、0より小さくなったときに得られたトピックがその単語のトピックとなります。
具体例を挙げると下記のようになります。
文字列
A B C D
トピック列
1 2 2 3
トピックの出力される確率は確率分布より、仮に下記のようになるとすると
1:1/2
2:1/3
3:1/4
総和は1/2 + 1/3 + 1/3 + 1/4
0から総和の範囲で仮に出力された値が
1/2 + 1/3
の場合
A B C D
1 2 2 4
1/2 1/3 1/3 1/4
上記のBまでの文字列で出力された確率を引くことで得られるトピック”2”が今回のサンプルで得られたトピックであることが分かります。
ギブスサンプリング
今回使用した手法はギブスサンプリングです。
この手法はある分布に従って、サンプルを生成する手法です。
ある分布が大事なところでこの分布の選択が解きたい問題によって変わってきます。
今回与えられているのが同時確率分布$P(X,Y)$ですが同時確率からは二つの変数が与えられているためサンプリングが不可能です。
そこで条件付き確率分布を用いてサンプリングを行います。
要約すると
文字列を固定してサンプリング
トピックを固定してサンプリング
上記を行うだけです。
具体的なトピックモデルのサンプリングです。
16~19ページ引用
NLP Programming Tutorial 7 -トピックモデル
http://www.phontron.com/slides/nlp-programming-ja-07-topic.pdf, (参照 2015-06-25)
文字列とトピックのペアを削除し、確率を再計算

同時確率を算出するため、トピック確率と単語確率を掛け合わせる

更新された同時確率分布から一つサンプリングし、出力された単語とトピックをもとに更新する

多くのカウントが0に陥るため、平滑化を行う。

初期化
初期化を行い必要な値を定義
init部分の定義
文書コーパスの単語とトピックを定義
self.xcorpus = numpy.array([])
self.ycorpus = numpy.array([])
単語数とトピック数をカウントして保持する
self.xcounts = {}
self.ycounts = {}
トピックベクトル
self.topics_vector = numpy.array([])
トピック数
self.TOPICS = 7
文書id
self.docid = 1
異なる単語数
self.different_word = 0
initilize部分で初期の単語のトピックをランダムに与える処理を行っています。このランダムに与える部分は共役事前分布を用いるなどの工夫が出来る部分です。
#-*- coding:utf-8 -*-
__author__ = 'ohgushimasaya'
from numpy import *
from numpy.random import *
import numpy
from Add_Count import add_count
import os.path
class initilaze_topic_model:
def __init__(self):
self.xcorpus = numpy.array([])
self.ycorpus = numpy.array([])
self.xcounts = {}
self.ycounts = {}
self.topics_vector = numpy.array([])
self.TOPICS = 7
self.docid = 1
self.different_word = 0
def initilize(self):
first_time = 1
adder = add_count(self.xcounts, self.ycounts)
self.docid = os.path.getsize("07-train.txt")
for line in open("07-train.txt", "r"):
rline = line.rstrip("¥n")
words = numpy.array(rline.split(" "))
topics_vector = []
self.different_word = set(words)
for word in words:
topic = randint(self.TOPICS) + 1
topics_vector.append(topic)
adder.add_counter(word, topic, self.docid, 1)
array_topics_vector = numpy.array(topics_vector)
if first_time == 1:
self.xcorpus = numpy.hstack((self.xcorpus, words))
self.ycorpus = numpy.hstack((self.ycorpus, array_topics_vector))
first_time = first_time + 1
else:
self.xcorpus=numpy.vstack((self.xcorpus, words))
self.ycorpus = numpy.vstack((self.ycorpus, array_topics_vector))
カウンター
__author__ = 'ohgushimasaya'
class add_count:
def __init__(self, xcounts, ycoutns):
self.xcounts = xcounts
self.ycounts = ycoutns
def add_counter(self, word, topic, docid, amount):
#Word
self.xcounts = add_count.check_dict(topic, self.xcounts, amount)
self.xcounts = add_count.check_dict((word, topic), self.xcounts, amount)
#TOPIC
self.ycounts = add_count.check_dict(docid, self.ycounts, amount)
self.ycounts = add_count.check_dict((topic, docid), self.ycounts, amount)
@staticmethod
def check_dict(key, w_t_count, amount):
if w_t_count.has_key(key):
w_t_count.update({key:w_t_count[key] + amount})
return w_t_count
else:
w_t_count[key] = 1
return w_t_count
トピック数と単語をカウント
トピックが与えられたときの単語数及び文書idが与えられた時のトピックも計算
サンプリング
__author__ = 'ohgushimasaya'
from numpy import *
from numpy.random import *
import numpy
import random
from Add_Count import add_count
import os.path
class Sampling:
def __init__(self, xcorpus, ycorpus):
self.iteration = 1000
self.xcorpus = xcorpus
self.ycorpus = ycorpus
self.alpha = 0.01
self.beta = 0.03
def sampling(self, TOPICS, xcounts, ycounts, docId, different_word):
for i in range(0, self.iteration):
Sampling.sampler(self, i, TOPICS, xcounts, ycounts, docId, different_word)
@staticmethod
def sampler(self, i, TOPICS, xcounts, ycounts, docId, different_word):
ll = 0
adder = add_count(xcounts, ycounts)
probs = {}
for i in range(0, len(self.xcorpus)):
for j in range(0, len(self.xcorpus[i])):
x = self.xcorpus[i][j]
y = self.ycorpus[i][j]
adder.add_counter(x, y, i, -1)
for k in range(TOPICS):
if xcounts.has_key(k) and (x, k) in xcounts and ycounts.has_key(docId) \
and (y, docId) in ycounts:
if xcounts[k] != 0 and ycounts[docId] != 0:
p_x_y = 1.0 * xcounts[(x, k)] + self.alpha / xcounts[k] + self.alpha * len(different_word)
p_y_Y = 1.0 * ycounts[(y, docId)] + self.beta / ycounts[docId] + self.beta * TOPICS
probs.update({k : p_x_y * p_y_Y})
new_y = Sampling.sampleOne(probs)
ll = ll + log(probs[new_y])
adder.add_counter(x, new_y, i ,1)
self.ycorpus[i][j] = new_y
print ll
@staticmethod
def sampleOne(probs):
z = 0
for k, v in probs.items():
z = z + v
remaining = random.uniform(0, z)
for k,v in probs.items():
remaining = remaining - v
if remaining <= 0:
return k
1.単語、トピックをピックアップして減算
2.トッピクの数だけ、各トピックに対するトピックに対する単語の条件付き確率とトピックに対するドキュメント条件付き確率を算出
3.各トピックに対する同時確率を更新
4.同時確率を使用してトピックを生成
5.生成したトピックを使用して対数確率を計算
6.単語に対して、トピックを加算する
7.トピックのコーパスに対してトピックを加算する
コードは下記に置いておきます。