このチュートリアルの内容
このチュートリアルでは、人との接触・接近を検出する例として、タッチセンサーと人の認識機能について、その仕様や挙動を、サンプルを通じて説明します。
- タッチセンサー仕様
- タッチ検出
- 人の認識
なお、 タッチ検出および人の認識についてはバーチャルロボットでは動作確認手段はなく、Pepper実機が必要になります。 アルデバラン・アトリエ秋葉原などでPepper実機を使って実験などおこなってみていただければと思います。 (予約URL:http://pepper.doorkeeper.jp/events)
センサー仕様
Pepperは以下のタッチセンサーを備えています。
-
頭部 ... 前部 [A]、中央 [B]、後部 **[C]**の3種類

-
手 ... 左右それぞれ、手の甲

タッチ検出
単純なタッチ検出のテストとして、頭部の前、中央、後部がさわられたら、「あたままえ」「あたままんなか」「あたまうしろ」としゃべり、左手の甲がさわられたら「ひだりて」としゃべり、右手の甲がさわられたら「みぎて」としゃべらせてみる ことをやってみます。
つくってみる
-
利用するボックスの準備
- Sensing > Tactile Head ... 頭のタッチを検出する
- Sensing > Tactile L.Hand ... 左手のタッチを検出する
- Sensing > Tactile R.Hand ... 右手のタッチを検出する
- Audio > Voice > Set Language ... 言語設定を変更する
- Audio > Voice > Say (5回ドラッグ&ドロップ) ... 入力した文字列をしゃべる
-
ボックスをつなぐ
それぞれTactile Head, L.Hand, R.Handを以下のようにつなぎます。
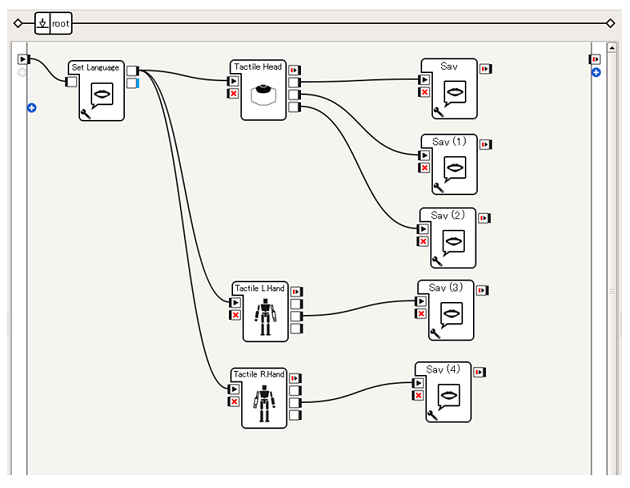
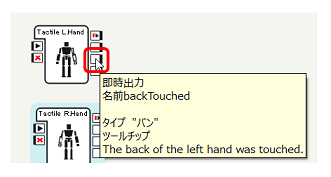
なお、Tactile L.Hand, R.Handも3つ出力を持っていますが、Pepperにおいて出力されるのは以下の backTouched のみです。
####
 [Tips]センサーボックスの停止方法
[Tips]センサーボックスの停止方法
今回のサンプルは、再生後Choregrapheから停止 されない限り、センサーを監視し、タッチが発生したらしゃべることをおこない続けます。
されない限り、センサーを監視し、タッチが発生したらしゃべることをおこない続けます。
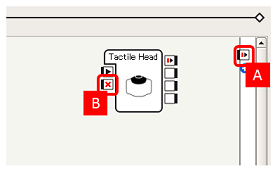
アプリケーションを停止するようなフローを記述する(onStopped出力 [A] に何らかの出力を接続する)ことでアプリケーション全体を停止することもできますが、このようなセンサー関連ボックスの onStop入力 [B] に対して入力をおこなうことで、ボックスを停止することもできます。
-
パラメータを設定する
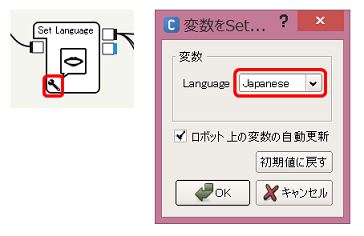
Set LanguageボックスにJapaneseを設定します。
-
Sayの内容を変更する
Tactileの出力によってしゃべる内容が変化するように、各Sayボックスの内容を変更します。ここでは、上から、それぞれ あたままえ, あたままんなか, あたまうしろ, ひだりて, みぎて とします。
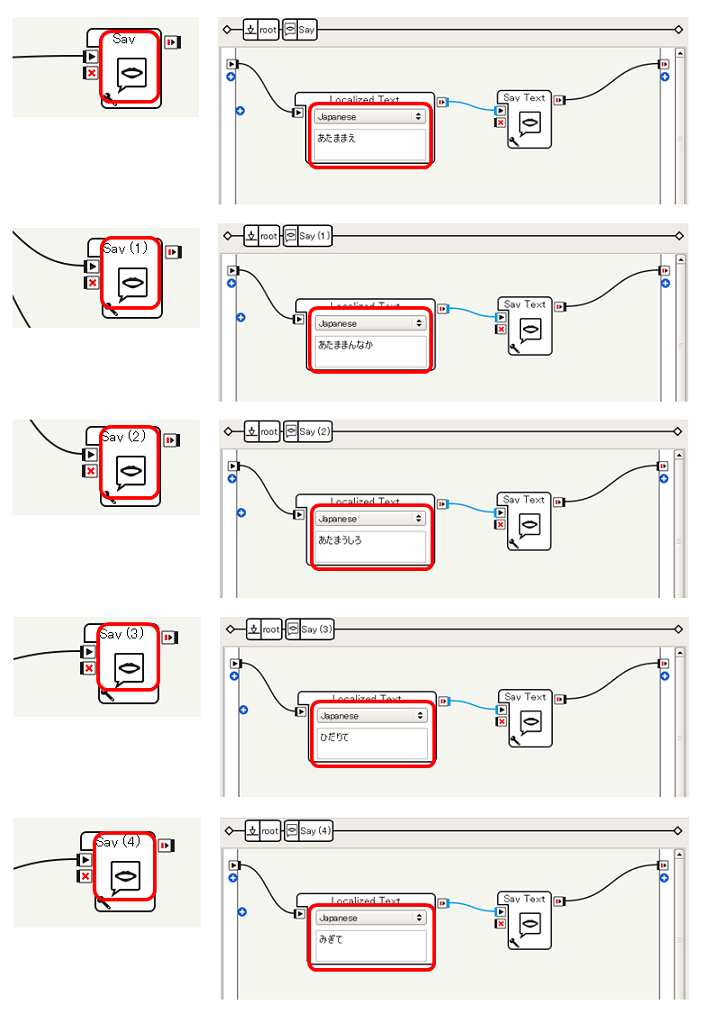
これで、タッチされた部位ごとにしゃべる内容を変化させることが可能になります。
動作確認
Pepperに接続し、再生をおこなって動作確認してみてください。頭の各部位をさわってみて、しゃべる内容が変化したり、手の甲をさわってしゃべることができれば成功です。
人の認識
エンゲージメントゾーン
Pepperは、3Dセンサーをはじめさまざまなセンサーを活用して、周辺の人を識別し、その人がどのあたりにいるのかを検出することができます。
ロボットビューに、以下のように地面に1, 2, 3と領域が表示されていますが、これはエンゲージメントゾーンと呼び、この中に人が入ったり、移動したりすることによってロボットの挙動を変更することができます。
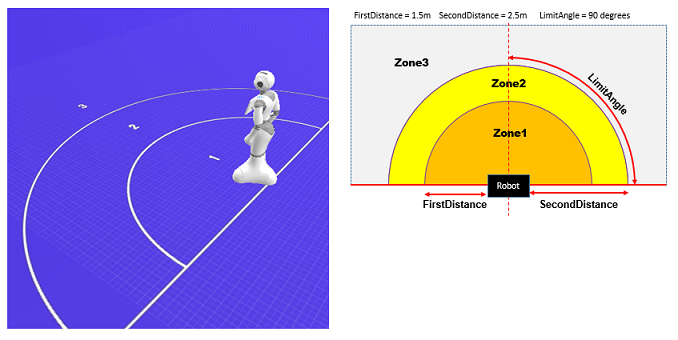
エンゲージメントゾーンの定義はAPIによりカスタマイズすることができます (参考:SDKドキュメント NAOqi Developer guide > NAOqi Framework > NAOqi API > NAOqi PeoplePerception > ALEngagementZonesページ内 Zone definition)が、デフォルトでは、
- FirstDistance ... Pepperから1.5m
- SecondDistance ... Pepperから2.5m
- LimitAngle ... 90°
となっています。ここでは、エンゲージメントゾーンに関するイベントの検出をチュートリアルを通じて説明します。
メモリイベント
ここまでで、タッチ、顔検出などイベントの取得にはボックスを利用することでおこなってきましたが、エンゲージメントゾーン関連のイベント取得は メモリイベント を介しておこなってみます。
メモリイベントとは
メモリイベントは、ALMemory が提供する機能の1つです。
ALMemoryはロボットに関する情報を集約する機構で、ハードウェア関係の情報(たとえば、各関節のセンサーから得られた各種情報)や、これらのハードウェアのセンサー情報から計算された情報(たとえば、検出されている顔の情報)などを蓄積、共有することができます。
ALMemoryはキーと値の組み合わせを設定、取得ができるほか、 メモリイベント という形で通知をおこなうこともできます。
何かイベントに反応するようなボックスはこのメモリイベントの発生を検出し、出力をおこなうという形で実装されています。
たとえば、先のTactile Headボックスをダブルクリックすると、以下のような構造になっていることがわかります。
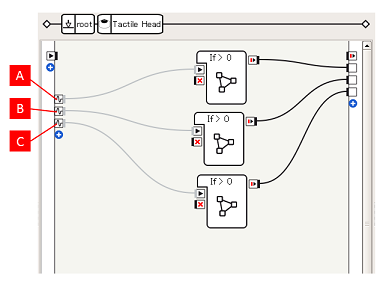
これまで見てきたフローの場合、左端にはonStart入力の1つだけでしたが、これに加えて3つの入力があります。
内容はマウスオーバーにより確認でき、それぞれ、FrontTactilTouched [A], MiddleTactilTouched [B], RearTactilTouched [C] というメモリイベントによりシグナルが送られるようになっていることがわかります。
メモリウォッチャーによる確認方法
メモリイベントは メモリウォッチャー パネルによって確認することができます。
メモリウォッチャーを確認するには、以下の手順でおこなってください。
-
[表示]メニューの [メモリウォッチャー] を選択します
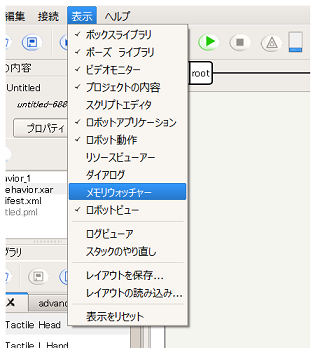
メモリウォッチャーパネルが開きます。

-
<監視するメモリキーの選択> をダブルクリックするか、右クリックメニューから [+]選択... をクリックします
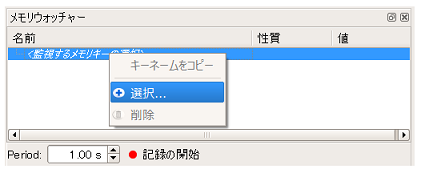
-
監視したいメモリキーを選択します。ここでは、先のTactile Headボックス内にあったFrontTactilTouchedを監視してみます。メモリキーの一部を入力 [A] し、現れたメモリキーをチェック [B] し、OKボタンをクリックします
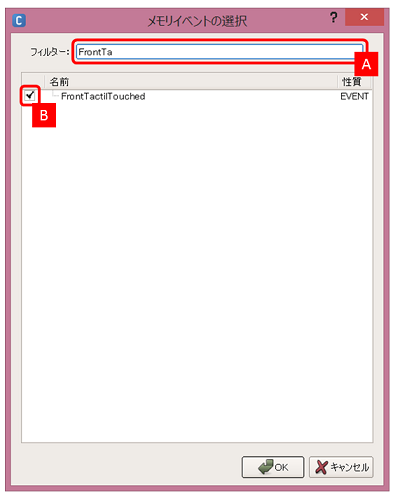
-
メモリウォッチャーパネル内にメモリキーとその値 [A] が表示されます。
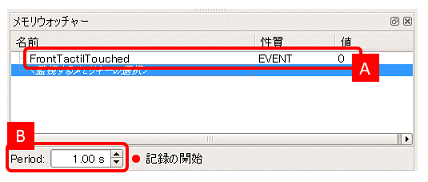
なお、メモリウォッチャーは定期的にロボットに対してメモリの値を取得し、表示を更新します。この頻度は更新間隔 [B] で変更することができます。
これで、メモリキーの値をチェックすることができます。Pepperの頭をさわってみて、FrontTactilTouchedの値がどう変化するか確認してみてください。
このように、Pepperが検出する事象はメモリイベントとして取得することができ、自身の作成しているビヘイビアで直接メモリイベントを取得するといったこともおこなえます。ここでは、エンゲージメントゾーン関連のメモリイベントの検出を通してその方法について説明していきます。
人の接近
ここでは、人が接近してきたことを認識したら「やあ」としゃべり、離れていったことを検出したら「じゃあ また」としゃべらせる ことをやってみます。
つくってみる
-
利用するボックスの準備
- Audio > Voice > Set Language ... 言語設定を変更する
- Audio > Voice > Say (2回ドラッグ&ドロップ) ... 入力した文字列をしゃべる
-
人が近づいたことや、離れていったことを メモリイベント として検出します。まず、フローダイアグラム左端の [+]ボタン をクリックします
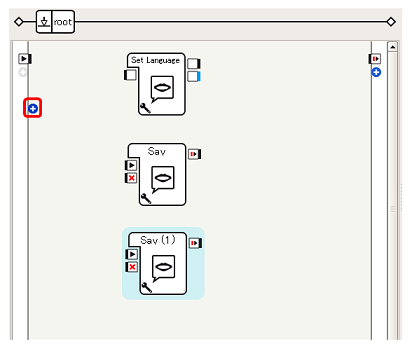
-
メモリイベントの選択ダイアログが開きます。今回は、人が近づいたことを検出するために、 EngagementZones/PersonApproached というイベントを使いたいので、フィルターとして Personを入力 [A] し、そこであらわれた候補にある PersonApproachedをチェック [B] し、OKボタンをクリックします
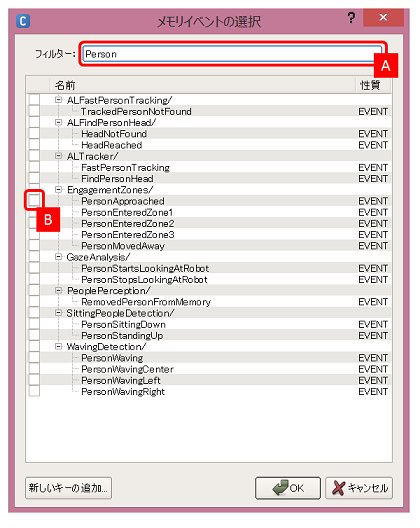
-
フローダイアグラム左端に、新たな入力があらわれます。これは、先ほど選択した EngagementZones/PersonApproached イベントが発生した際にシグナルが発生します
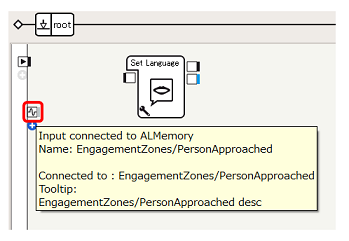
マウスオーバーで説明を確認することもできます。 -
同様に、2.~4.の手順にしたがって、人が離れたことを検出するため EngagementZones/PersonMovedAway メモリイベントを入力として追加します
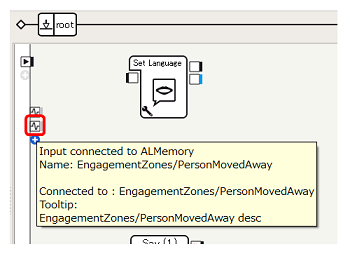
-
ビヘイビアが開始したらSet Languageボックスを開始するように、PersonApproachedが発生したらSayボックス(1つめ)、PersonMovedAwayが発生したらSayボックス(2つめ)を開始するようにボックスをつなぎます
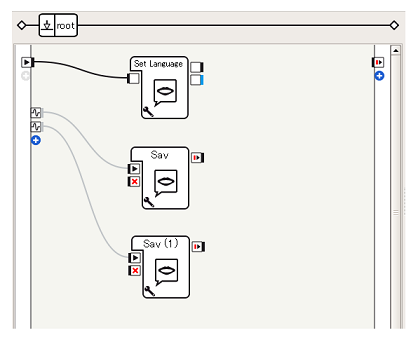
-
Set LanguageボックスをJapaneseに設定します

-
Sayボックスの内容をそれぞれ変更します
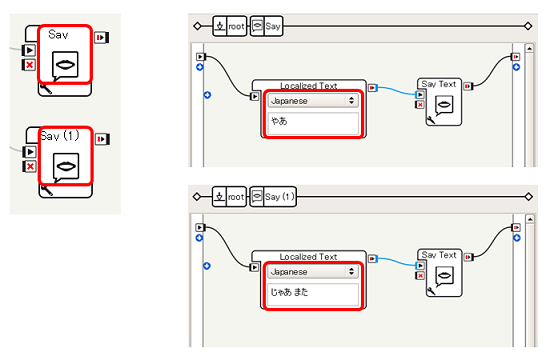
これで、人が近づいてきたら(EngagementZones/PersonApproachedイベント)、「やあ」と言い、人が離れたら(EngagementZones/PersonMovedAwayイベント)、「じゃあ また」と言うことを実現することができます。
動作確認
Pepperに接続し、再生してから、Pepperの前を歩き回ったり、一度離れて(2mくらい)みたり、近づいてみたりをしてみてください。近づくと「やあ」離れると「じゃあ また」とPepperが言えば成功です。
エンゲージメントゾーンへの侵入
次に、より詳細に、どのエンゲージメントゾーンに人が入ったのか検出することをおこなってみましょう。
ここでは、ゾーン1に人が入ってきたら「ゾーン1」、ゾーン2ならば「ゾーン2」、ゾーン3ならば「ゾーン3」としゃべらせる ことをやってみます。
つくってみる
先ほどの例と同様に、メモリイベント(EngagementZones/PersonEnteredZone1, EngagementZones/PersonEnteredZone2, EngagementZones/PersonEnteredZone3)を利用してエンゲージメントゾーンに人が入ったことを検出します。
-
利用するボックスの準備
- Audio > Voice > Set Language ... 言語設定を変更する
- Audio > Voice > Say (3回ドラッグ&ドロップ) ... 入力した文字列をしゃべる
-
メモリイベントを追加
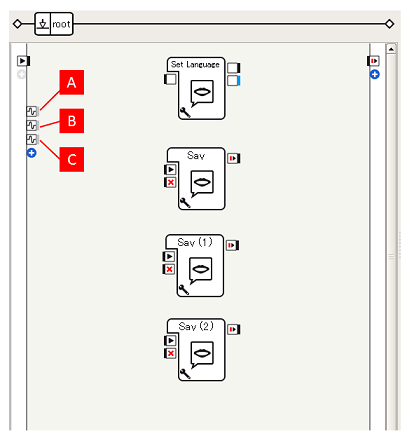
やり方は[人の接近]チュートリアルのEngagementZones/PersonApproachedと同様です- EngagementZones/PersonEnteredZone1 [A]
- EngagementZones/PersonEnteredZone2 [B]
- EngagementZones/PersonEnteredZone3 [C]
-
ボックスをつなぐ
-
パラメータの設定
Set LanguageボックスをJapaneseに設定します。
-
Sayの内容を変更する
3つのSayボックスについて、それぞれ ゾーン1, ゾーン2, ゾーン3 と変更します。
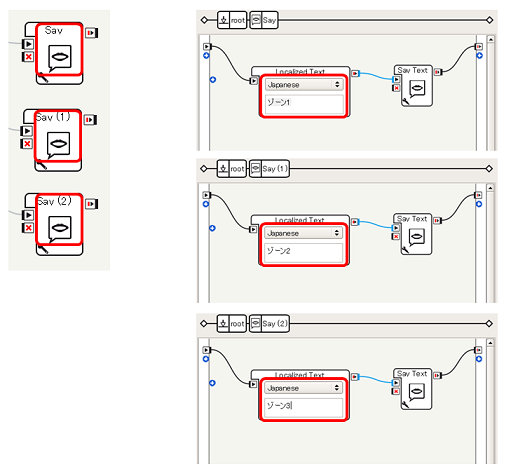
これで、各ゾーンに人が入ったことが検出されると、「ゾーン1」や「ゾーン2」としゃべるようになります。
動作確認
Pepperに接続、再生し、周辺を歩き回ってみてください。「ゾーン1」「ゾーン2」などとPepperがしゃべるはずです。
このようにして、タッチイベントのような個々のセンサーによって検出できる事象以外に、複数のセンサーによって検出できるイベントもあります。イベントはボックスライブラリで簡単に使用できるものもありますが、メモリイベントによってより広くイベントを検出することが可能です。