1. Introduction
アメリカ合衆国のスポーツライターであり、野球のセイバーメトリクスの先駆者であるビル・ジェームズは、チームの得点数を予測する数式を作り出した。
得点数 = (安打数+四球数) × 塁打数 ÷ (打数+四球数)
この数式によって見積もられる得点数は、RC(Runs Created)と名づけられた。
ジェームズはこの式の右辺に色々なMLBチームの過去のシーズン記録を代入して、実際の得点数と合うのかどうかを確認した。その結果、この数式はどのチームに当てはめても有効であり、極めて精度良く得点数を予測することが出来た。
しかし一つの疑問がある。
- ジェームズがこの公式の精度を検証する際に用いたのはMLBのデータだった。NPBのチームに関しても、この数式を用いて得点数を精度良く予測することは出来るのだろうか?
そこで今回は、実際のNPBのチームデータを用いて、この得点公式RCの精度の検証を行った。
2. Data and Program
2.1. Data
用いたデータは、2005年〜2016年の、日本プロ野球(NPB)の12球団のシーズン成績である。
データは日本野球機構のホームページ
http://npb.jp/
から得た。
例えば2016年セ・リーグのシーズン成績は、
http://npb.jp/bis/2016/stats/tmb_c.html
から取得し、以下のようにフォーマットを加工して保存した。
Carp, .272, 143, 5582, 4914, 684, 1338, 203, 35, 153, 2070, 649, 118, 52, 91, 29, 500, 13, 47, 1063, 85, .421, .343
Yakult, .256, 143, 5509, 4828, 594, 1234, 210, 20, 113, 1823, 565, 82, 24, 85, 33, 524, 10, 39, 907, 117, .378, .331
Giants, .251, 143, 5356, 4797, 519, 1203, 217, 19, 128, 1842, 497, 62, 26, 112, 23, 389, 11, 35, 961, 100, .384, .310
DeNA, .249, 143, 5364, 4838, 572, 1205, 194, 21, 140, 1861, 548, 67, 34, 81, 18, 373, 7, 54, 1049, 92, .385, .309
Dragons, .245, 143, 5405, 4813, 500, 1180, 209, 21, 89, 1698, 473, 60, 28, 108, 28, 410, 7, 46, 1001, 103, .353, .309
Tigers, .245, 143, 5401, 4789, 506, 1171, 204, 17, 90, 1679, 475, 59, 25, 88, 38, 435, 17, 51, 1149, 99, .351, .312
(なお、データは
https://github.com/AnchorBlues/python/tree/master/baseballdata
に加工した状態のものを置いている)
2.2. Program
データの読み込み、解析、及び可視化にはプログラミング言語のPythonを用いた。
#coding:utf - 8
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
fy = 2005
ly = 2016
Yn = ly - fy + 1
Bat_Column = ['Average', 'Game', 'PA', 'AB', 'Score', 'Hit', \
'TwoBase', 'ThreeBase', 'HR', 'TB', 'RBI', 'Steel', \
'MissSteal', 'Bunt', 'SF', 'BB', 'IntentionalWalk', \
'DeadBall', 'StrikeOut', 'DoublePlay', 'SLG', 'OBP']
# PA : Plate Appearance 打席数
# AB : At Bat 打数
# TB : Total Bases 塁打数
# RBI : 打点
# SF : Sacrifice Fly 犠牲フライ
# IntentionalWalk : 故意四球
N = len(Bat_Column)
class Bat_Data():
def __init__(self, Data, Year, Team):
self.Year = Year
self.Team = Team
for i in range(0, N):
setattr(self, Bat_Column[i], Data[:, i])
self.OPS = self.SLG + self.OBP
self.NOI = (self.SLG / 3.0 + self.OBP) * 1000
self.BABIP = (self.Hit - self.HR) / (self.AB + self.SF - self.HR - self.StrikeOut)
self.RC = (self.Hit + self.BB) * self.TB / (self.AB + self.BB)
self.IsoP = self.SLG - self.Average
self.IsoD = self.OBP - self.Average
class TEAM:
def __init__(self, ID, Name, maker):
self.ID = ID
self.Name = Name
self.maker = maker
team = [0] * 12
team[0] = TEAM(0, 'Carp', '>')
team[1] = TEAM(1, 'Tigers', '<')
team[2]= TEAM(2, 'Giants', '^')
team[3] = TEAM(3, 'Dragons', 'v')
team[4] = TEAM(4, 'DeNA', 'd')
team[5] = TEAM(5, 'Yakult', 'D')
team[6] = TEAM(6, 'Fighters', '8')
team[7] = TEAM(7, 'Lotte', 'H')
team[8] = TEAM(8, 'Lions', 'h')
team[9] = TEAM(9, 'Eagles', '*')
team[10] = TEAM(10, 'Orix', 'p')
team[11] = TEAM(11, 'Hawks', 's')
# 2つのBat_Dataインスタンスを1つのインスタンスに統合する
def Docking(Data1, Data2):
data = np.zeros((Data1.Average.shape[0] + Data2.Average.shape[0], N))
for i in range(0, N):
data[:, i] = np.r_[getattr(Data1, Bat_Column[i]), getattr(Data2, Bat_Column[i])]
year = np.r_[Data1.Year, Data2.Year]
team = np.r_[Data1.Team, Data2.Team]
Data_new = Bat_Data(data, year, team)
return Data_new
def get_data(League, year):
fname = './baseballdata/' + str(year) + League + '_bat.csv'
Data = np.loadtxt(fname, delimiter = ',', usecols = range(1, N + 1))
Year = np.ones(6) * year
Team = np.loadtxt(fname, delimiter = ',', usecols = range(0, 1), dtype = str)
Data = Bat_Data(Data, Year, Team)
return Data
def get_all_data(League):
for i in range(Yn):
year = i + fy
tmp = get_data(League, year)
if i == 0:
Data = tmp
else:
Data = Docking(Data, tmp)
return Data
# Data.Column_nameの中から、チーム名がTeam_nameのものだけを取り出す。
def PickUp_Data_of_a_team(Data, Column_name, Team_name):
return getattr(Data, Column_name)[np.where(getattr(Data, 'Team') == Team_name)]
def draw_scatter(plt, Data, X_name, Y_name, regression_flg = 0, Y_eq_X_line_flg = 0, \
title = 'Scatter plot', fsizex = 10, fsizey = 8):
fig, ax = plt.subplots(figsize = (fsizex, fsizey))
plt.rcParams['font.size'] = 16
for i in range(0, len(team)):
x = PickUp_Data_of_a_team(Data, X_name, team[i].Name)
y = PickUp_Data_of_a_team(Data, Y_name, team[i].Name)
year = PickUp_Data_of_a_team(Data, 'Year', team[i].Name)
if x != np.array([]):
CF = ax.scatter(x, y, c = year, s = 50, marker = team[i].maker, \
label = team[i].Name, vmin = fy, vmax = ly)
if i == 0:
X = x
Y = y
else:
X = np.r_[X, x]
Y = np.r_[Y, y]
plt.colorbar(CF, ticks = list(np.arange(fy, ly + 1)), label = 'year')
plt.legend(bbox_to_anchor = (1.35, 1), loc = 2, borderaxespad = 0., scatterpoints = 1)
ax.set_title(title)
ax.set_xlabel(X_name)
ax.set_ylabel(Y_name)
# 回帰直線を引く
if regression_flg == 1:
slope, intercept, r_value, _, _ = stats.linregress(X, Y)
xx = np.arange(450, 750, 1)
yy = slope * xx + intercept
ax.plot(xx, yy, linewidth = 2)
# y=xの直線を引く
if Y_eq_X_line_flg == 1:
xx = np.arange(450, 750, 1)
yy_d = xx
ax.plot(xx, yy_d, color = 'k')
print 'Correlation=', np.corrcoef(X, Y)[0, 1]
return plt
例えば、2016年セ・リーグのデータを取り出したいときには以下のようにする。
In [1]:import NPB
In [2]:Data_2016C=NPB.get_data('C',2016) #パ・リーグにしたいときには'C'を'P'に。
In [3]:Data_2016C.Average #2016年セ・リーグの、6チームそれぞれのチーム打率を出力
Out[3]: array([ 0.272, 0.256, 0.251, 0.249, 0.245, 0.245])
3. Result
3.1. Average vs Score
まずは、最も一般的な打撃指標である「打率」と、得点数との相関を見てみる。
2005〜2016年の12球団全てのチームデータ(全部で144サンプル)のデータを取り出して、横軸に「打率(Average)」、縦軸に「得点数(Score)」を取って散布図を描いてみる。
In [1]:import matplotlib.pyplot as plt
In [2]:Data_C=NPB.get_all_data('C') #セ・リーグの全てのデータを取り出す
In [3]:Data_P=NPB.get_all_data('P') #パ・リーグの全てのデータを取り出す
In [4]:Data=NPB.Docking(Data_C,Data_P) #両リーグのデータを統合
In [5]:plt=NPB.draw_scatter(plt,Data,'Average','Score') #打率と得点の散布図を描く
In [6]:plt.show()
出力された図は以下の通り。
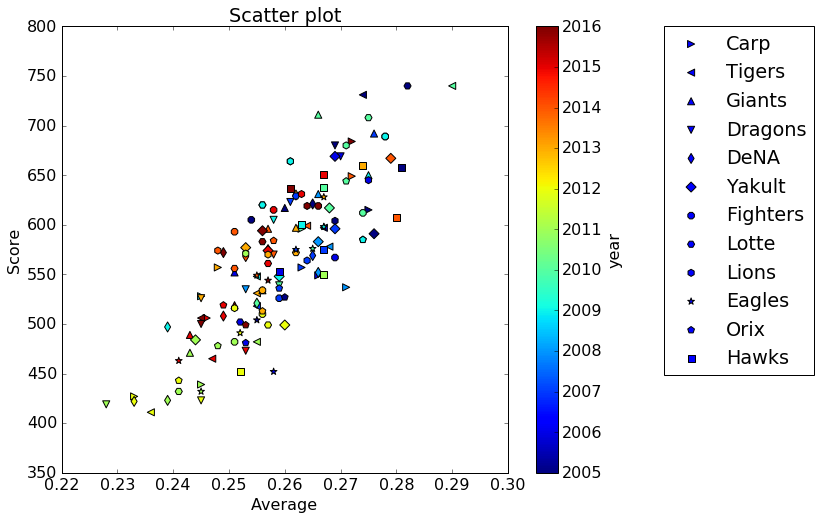
また、相関係数は、
Correlation= 0.825987845723
という結果になった。
3.2. RC vs Score
3.1. と同じデータに対して、今度は横軸に「RC」、縦軸に「得点数(Score)」を取って散布図を描いてみる。
In [7]:plt=NPB.draw_scatter(plt,Data,'RC','Score',regression_flg=1,Y_eq_X_line_flg=1) #RCと得点の散布図を描く。さらにその回帰直線と、y=xの直線を引く。
In [8]:plt.show()
出力された図は以下の通り。
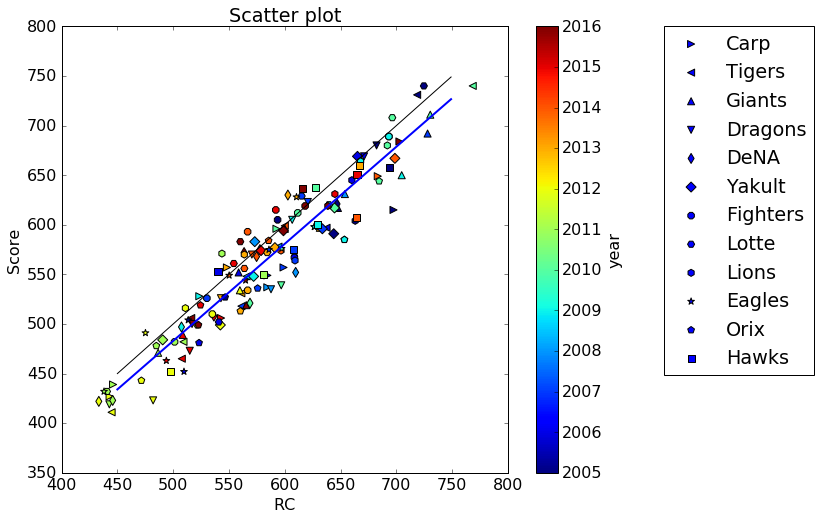
また、相関係数は、
Correlation= 0.953524104544
という結果になった。
相関係数の値からも、RCと得点数の間には極めて強い相関があるということが分かる。
更に、その回帰直線(上図の青線)は、「y=x」の直線(上図の黒線)と非常に近いものとなった。
(なお、回帰直線はy=0.95*x-6.3であった)
4. Conclusion
NPBの過去のチームデータで検証してみた結果、得点公式RCはNPBのチームの得点数も極めて精度良く予測することが出来るということがわかった。
ビル・ジェームズが考案したRCの式は、今では係数の値などの改良が行われ、盗塁数なども説明変数に使われるようになっている(Wikipediaのページ[後記]参照)。
しかしビル・ジェームズの考案した得点公式の素晴らしい点は、出塁能力(=安打数+四球数)×進塁能力(=塁打数)だけで得点数を精度良く見積もれるとした点だと思う。各説明変数に係数が一切かかっておらず、その式の形は非常にシンプルである。
この様なシンプルな式で得点数を見積もれるというということを発見したという事実は、やはり特筆に値するのではないか。