私のチームでは週2回、当番制でサービスのログをチェックして問題がないか確認しています
こんな感じで当番の人に通知して当番をまわしています

サービスのエラーログはelasticsearchとkibanaで可視化しているので、確認自体はさほど大変ではないのですが、問題が起きていない場合がほとんどで作業コストの方が大きく感じてしまいます...
そのせいか、最近はみんなの妹への反応が薄いような気もします...
エラーログの確認を自動化して異常があれば通知する
そんな話をしていたら誰かに「elastalert」というツールを教えてもらいました
elastalertは、Elasticsearchのインデックスをモニタリングして設定した条件とマッチした時にalertを通知するためのツールのようです
本家ドキュメント: https://elastalert.readthedocs.org/en/latest/index.html
GitHub: https://github.com/Yelp/elastalert
elastalertでサービスのエラーログの数を監視して、設定した閾値を超えたらslackに通知してみようと思います
elastalertをインストールする
本家ドキュメントのインストール手順 通りに作業します
git clone してツールをダウンロードする
$ git clone https://github.com/Yelp/elastalert.git
moduleをインストール
$ python setup.py install
$ pip install -r requirements.txt
私の環境には既にElasticsearchが導入されており、アプリサーバのエラーログが収集されているので、Elasticsearchの導入やログの収集方法などの説明は割愛します
私の環境にはversion 1.2.1のElasticsearchがインストールされています
elastalertの設定ファイルを準備する
git cloneしたディレクトリにconfig.yaml.exampleというファイルがあるはずなので、config.yamlという名前にコピーして設定ファイルを準備します
$ cp config.yaml.example config.yaml
作成したconfig.yamlに必要な設定を書きます
rules_folder: rules # ruleの設定ファイルが配置されているディレクトリ
run_every: # Elasticsearchにクエリを発行する間隔
minutes: 1
es_host: 127.0.0.1 # 監視するElasticsearchのhost
es_port: 9200 # 監視するElasticsearchのport
elastalert用のindexをElasticsearchに作成する
elastalert-create-indexを実行すれば必要なindexを作成してくれます
$ elastalert-create-index
New index name (Default elastalert_status)
Name of existing index to copy (Default None)
New index elastalert_status created
Done!
実行すると2回入力を求められます
"New index name": 保存するindexの名前を名前を入力する。defaultでいいなら入力しない
"Name of existing index to copy": すでにindexがある場合、それをコピーして作成するかどうか。コピーする場合はコピー元のindex名を入力する
ruleを作成する
ruleというのはelastalertで監視するindexの設定や、alertを送信する条件とalertの方法などを書いた設定ファイルです
ruleを配置するディレクトリを作成する
config.yamlのrules_folderに設定した名前でディレクトリを作成します
$ mkdir rules
ruleを作成する
example_rulesというディレクトリにsampleのruleがいくつか配置してあるので、コピーして作成すると良いかもしれません
ruleの設定についてのドキュメント: https://elastalert.readthedocs.org/en/latest/ruletypes.html
私が今回作成したruleは↓です
# rule name
name: exp spike rule
# rule type
type: spike
spike_height: 3
spike_type: "up"
threshold_cur: 50
timeframe:
minutes: 10
# query key
query_key: "exp-name"
# index
index: exp-log.*
# top count
top_count_keys:
- "exp-name"
raw_count_keys: False
# filter
filter: []
# alert type
alert:
- "slack"
slack_webhook_url: "https://hooks.slack.com/services/~~~~"
# kibana
use_kibana_dashboard: "exp.dashboard"
kibana_url: "http://xxx.xxx.xxx.xxx"
- name
- 作成したruleの名前です、分かりやすければ何でもいいです
- type
- ruleのタイプです、ここの設定でalertする条件のロジックが変わります
- 設定できるtype: https://elastalert.readthedocs.org/en/latest/ruletypes.html#ruletypes
- 各タイプについて、下の方に軽く説明を書こうと思います
- timeframe
- 選択したtypeのロジックで使用する値を集計する間隔
- 今回の設定だと、10分間の間に発生したexceptionを集計します
- query_key
- 使用するElasticsearchのindexにあるfield名を設定
- 設定すると設定したfield名をユニークなkeyとして集計するようになります
- sqlでいう'GROUP BY field名'と同じだと思います
- index
- 使用するElasticsearchのindex名を設定
- top_count_keys
- 使用するElasticsearchのindexにあるfield名を設定
- 設定すると設定したfield名毎にcountした結果をalertのメッセージに付けてくれます
- デフォルトで上位5つが出力されますが、変更可能です
- raw_count_keys
- top_count_keysのオプション設定、trueにすると設定したfield名に.rawをつけてクエリを発行します
- デフォルトがtrueなのでfield名.rawのfieldがなければ設定しておくといいと思います
- filter
- Elasticsearchになげるクエリの結果をフィルターする設定
- 特定のfield値のときはルールを適用しないとかができます
- 詳しくは https://elastalert.readthedocs.org/en/latest/recipes/writing_filters.html
- フィルターしない場合は[]を設定してください
- alert
- alertの方法を設定
- email, hipchat, slackなどが設定できます
- 詳しくは https://elastalert.readthedocs.org/en/latest/ruletypes.html#alerts
- use_kibana_dashboard
- 既存のkibanaにあるダッシュボード名を設定
- 設定すると既存のダッシュボードをテンプレートにして生成したkibanaリンクをalertメッセージに付けてくれます
- generate_kibana_linkという設定もありますが、フィルターと併用出来ないみたいなのでこっちの方がオススメです
作成したruleをテストする
作成したruleはelastalert-test-ruleというコマンドでテストすることが出来ます
詳しくは https://elastalert.readthedocs.org/en/latest/ruletypes.html#testing-your-rule
実行するとElasticsearchにある過去のindexにruleを適用して、何件alertされたかなどの結果が出力されます
elastalert-test-rule rules/exp_spike.yaml --alert --days 3
- --days
- 過去何日分のデータに対してruleを適用するかを指定
- elastalert-test-ruleはデフォルトで過去24h分のindexに対してruleを適用します
- --alert
- このオプションを付けるとalertに設定した方法で実際にalertを送信します
- 指定しない場合は、alert件数とメッセージが標準出力されます
elastalertを起動する
python elastalert/elastalert.pyで起動できます
elastalertをデーモンとして起動する
本家ドキュメントに'supervisor'というツールを使うと良いとあるので使ってみます
supervisorのドキュメント: http://supervisord.org/
supervisorのinstall
easy_install supervisor
設定ファイルを準備する
echo_supervisord_confというコマンドを実行すると設定ファイルのsampleが出力されるので
echo_supervisord_conf > /etc/supervisord.confを実行して設定ファイルを準備します
設定ファイルを編集する
必要な設定をsupervisord.confに追記します
[program:elastalert]
command=python /usr/share/elastalert/elastalert/elastalert/elastalert.py
user=hogehoge
autorestart=true
stdout_logfile=/var/log/supervisor/elastalert.log
stdout_logfile_maxbytes=1MB
stdout_logfile_backups=5
stdout_capture_maxbytes=1MB
redirect_stderr=true
supervisorを起動する
supervisord -c /etc/supervisord.conf
elastalertをデーモンとして起動する
supervisorctl start elastalert
startの後にはsupervisord.confの[program:elastalert]で設定した名前を指定してください
これで自動検知できたはず..!
とりあえず、elastalertの導入は完了しました
いまのところ、エラーログが増えた時にちゃんとalertが来ているので導入して良かったと思っています
↓こんな感じで妹が異常を知らせてくれます
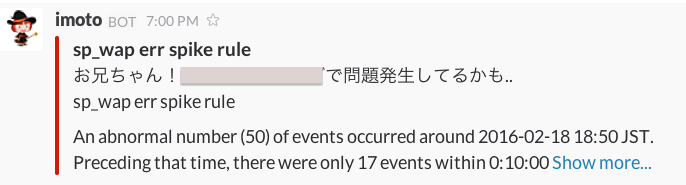
でも、まだ必要のないalertが来てしまうことがあるので、ruleの設定の調整はしばらく必要そう...
【補足】設定できるrule type
- Any
- どなんな結果にもマッチする
- BlackList
- ブラックリストに登録した値とマッチしたらalert
- - 追加設定項目 -
- 【必須】
- compare_key: ブラックリストと比較するfield名を設定
- blacklist: マッチさせたいfield値のリスト
- Whitelist
- ホワイトリストに登録した値以外とマッチしたらalert
- - 追加設定項目 -
- 【必須】
- compare_key: ホワイトリストと比較するfield名を設定
- ignore_null: trueにするとnull値を無視する
- whitelist: alertさせたくないfield値のリスト
- Change
- fied値を監視して値が変化したときにalert
- - 追加設定項目 -
- 【必須】
- compare_key: 監視するfield値
- ignore_null: trueにするとnull値を無視する
- query_key: field値を設定する compare_keyの変化を、設定したfield値毎の範囲で判断する 例えばhost毎にcompare_keyの変化を監視したい場合はhostを設定する
- 【オプション】
- timeframe: 比較する期間の最大値を設定できる
- Frequency
- 設定した期間内に発生したイベント数が閾値を超えたらalert
- - 追加設定項目 -
- 【必須】
- num_events: alertする閾値
- timeframe: イベント数をカウントする間隔
- 【オプション】
- use_count_query: trueにすると、Elasticsearchの'count api'を使用するようになる ドキュメントのデータを使用する必要がない場合はtrueにした方がいい この設定を使うには'doc_type'の設定が必須になる
- doc_type: 'use_count_query'と'use_terms_query'を使う場合は設定必須 使用するfieldの_typeを設定する
- use_terms_query: trueにするとElasticsearchの'aggregation query'を使用するようになる この設定を使用するには'doc_type'と'query_key'の設定が必須 (私はaggregation queryを使うことのメリットが分かっていません...分かる方教えて下さいmm)
- query_key: field名を設定 設定すると設定したfield毎にイベントをカウントする
- attach_related: trueにするとalertのトリガーになったイベントの情報が'related_events'という名前でalerterから参照できるようになる...と思います
- Spike
- 設定した間隔でイベント数をカウントして、その結果を直前とその前で比較してx倍になっていたらalert
- - 追加設定項目 -
- 【必須】
- spike_height: 何倍になっていたらalertするかを設定
- spike_type: alertする条件を、イベント数が増えていた時にするか減った時にするかを設定
- timeframe: イベント数をカウントする間隔時間を設定
- 【オプション】
- threshold_ref: 比較するtimeflameのうち、前のカウント結果の最小値条件 設定した値を超えていないとalertしない
- threshold_cur: 比較するtimeflameのうち、後のカウント結果の最小値条件 設定した値を超えていないとalertしない
- query_key: 'Frequency'と同じ
- use_count_query: 'Frequency'と同じ
- use_terms_query: 'Frequency'と同じ
- Flatline
- 設定した間隔でイベント数をカウントして、閾値よりもイベント数が少なければalert
- - 追加設定項目 -
- 【必須】
- threshold: alertする閾値
- timeframe: イベント数をカウントする間隔時間
- 【オプション】
- query_key: 'Frequency'と同じ
- use_count_query: 'Frequency'と同じ
- use_terms_query: 'Frequency'と同じ
- New Term
- field値を監視して未確認の値が出現したらalert
- - 追加設定項目 -
- 【必須】
- fields: 監視するfield名を設定
- 【オプション】
- terms_window_size: 未確認かを確認するために遡る時間を設定 デフォルトは30日間
- use_terms_query: 'Frequency'と同じ
- Cardinality
- field値の種類数を監視して、種類数が閾値を超えたらalert
- - 追加設定項目 -
- 【必須】
- timeframe: 種類数をカウントする間隔時間
- cardinality_field: 監視するfield名を設定
- max_cardinality: 種類数の最大値を設定 この値を超えたらalert
- min_cardinality: 種類数の最小値を設定 この値より少ない場合alert
- 【オプション】
- query_key: 'Frequency'と同じ