はじめに
最近は音声認識による家電操作などがCMでも流れている。
自分でもとりあえず音声認識してWebが操作できるものが作りたい!
と思い立ち、作ってみた。
とはいえ、先人の人が既に作り方を公開していらっしゃるので
そちらを参考に気が付いた点だけ補足していきます。
用意したもの
今回用意したものは以下のとおり
- RaspberryPi(Model A)
- SDカード(32GB)
- PLANEX GW-USNano2
- Logitech, Inc. QuickCam Pro 4000
- スピーカー
- microUSBケーブル
- USB AC電源アダプター
- miniUSBケーブル
- Web表示用PC
音声入力(USBマイク設定)
認識させるための音声を拾うために音声入力の設定をします。
こちらが参考になります。
pulseaudioの起動時にエラーとなっても特に問題は無いようです。
音声出力(OpenJTalk)
認識ついでに応答してもらうために、喋ってもらう用意をします。
こちらを参考にしました。
スピーカー、マイクの調節
$alsamixer
上記コマンドで設定画面を開きます。
※以下のような画面でMasterが出力(スピーカ音量)、Captureが入力(マイク感度)
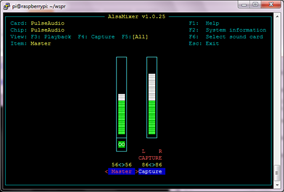
マイク、スピーカ共に50%程度が適量です。この状態でマイクに対して2~30cm離れた距離から
普通の音量で発声することで、期待した結果が最大限に発揮されるようです。
音声認識環境の構築(Juliusのインストール)
Juliusのインストール、設定は今までのリンクに方法が記載されています。
音声認識辞書の作成
認識させる言葉を予め登録しておくことにより、音声認識ができます。
辞書の作成は以下のサイトを参考にしました。
とりあえず、上記までで環境の構築はできました。
音声認識でのコントロール
後はJuliusで認識した言葉を命令にして実行するpythonなどを用意する。
音声応答を返す、WebSocketなりでPCのブラウザに飛ばし画面遷移を実現する。
デバイスを動かす等、いろいろなことができます。
以下のサイトを参考にしました。
まとめと課題
実際に動くことを確認できたのでいきなり誘われたHTML5カンファレンスに出展しました。
某音声認識ソフトをもじって「Chiriちゃん」by D.F.Mac(命名)
朝、設定しているときは動くことを確認できたんですが…
想定を大きく超えて、周りうるさ過ぎ!
雑音というより騒音で、ほとんど認識できませんでした… orz
音声認識では雑音対策が必要となる場合があります。(家庭で使う分には十分ですが)
デフォルトの環境ではノイズ対策がされていないため、次はノイズ対策に取り組みたいと思います。