1週間前にRaspberry Pi Advent Calendar 2015に投稿するはずだった記事です。Raspberry PiのGPUで行列乗算(その1)の続きです。予定を過ぎ大変申し訳ありませんでした。
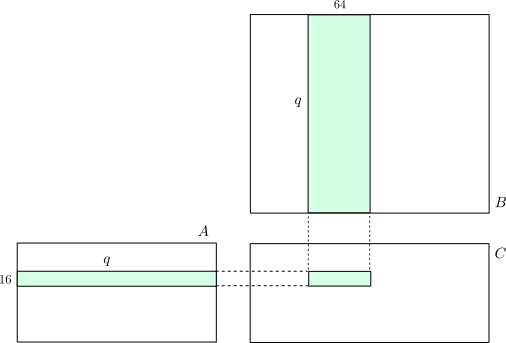
前回は下図の16x64行列をSIMDで並列計算する部分を作りましたので、その他の部分を作って行列乗算のコードを完成させます。
i-loop, j-loopはk-loopに比べると実行される回数が非常に少ないので、簡単にやります。
j-loopについて
for(j = 0; j < r; j+=64) {
body
}
を素直にアセンブリ風に翻訳すると
j = 0
j_loop_begin:
if(j >= r) goto j_loop_exit
body
j += 64
goto j_loop_begin
j_loop_exit:
となりますが、このままでは無駄なジャンプがあります。ジャンプは時間が掛かりますし、Instruction Cacheのエントリが追い出されてしまったりすると他の部分の性能にも影響が及びます。以下のようにループ内のジャンプが1回になるように書き直す事が出来ます。
j = 0
if(j >= r) goto j_loop_exit
j_loop_begin:
body
j += 64
if(j < r) goto j_loop_begin
j_loop_exit:
一番最初のj >= rは常に不成立なので省く事が出来ます。
j = 0
j_loop_begin:
body
j += 64
if(j < r) goto j_loop_begin
j_loop_exit:
つまり、以下のようなdo-while型ループの形になります。
j = 0
do {
body
j += 64
} while (j < r);
また、上の形よりも、
j = r
do {
body
j -= 64
} while(j > 0);
という形の方が良いと思います。ポイントは後者ではrへのアクセス回数が減るという所です。(おまけとして演算が1つ減ります。前者はj + 64とj - rの2回だったのが、後者ではj - 64の1回になります。)
j = 0
do {
body
j += 64
} while (j < r); <- ここで毎回rを読む
j = r <- ここの一回だけ
do {
body
j -= 64
} while(j > 0);
アクセス頻度が低い変数は遅いところに置いても影響が少ないので、メモリに退避したり前回紹介したような方法で退避する事が出来ます。すると、節約したレジスタやアキュムレータがloop bodyで有効活用出来ますので、間接的に性能向上につながります。i-loopも同じ要領で書きます。
ソフトウェアパイプライニング
前回触れた、ソフトウェアパイプライニングをやろうと思いましたが、後述の排他制御回りで力尽きたのでやっていません。
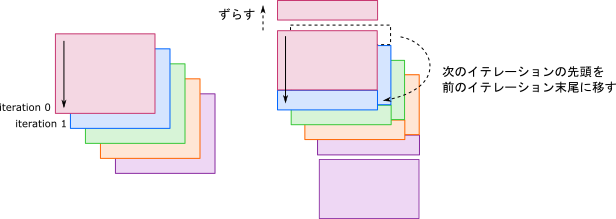
やろうとした事を説明しておきます。今回のプログラムを疑似コードで書くと以下のようになります。前回説明したように16x16行列を4回に分けて足しこむんですが、第4ブロックをホストに転送する箇所で何も計算をしない時間が生じています。
for (j) {
アドレス計算やキャッシュの初期化
k-loopから前にはみ出した部分
for (k) {
AとBのベクトルの積を計算
}
第1ブロックをロードしつつ、k-loopから後ろにはみ出した分を計算
第2ブロックをロードし、第1ブロックを計算
第1ブロックをストアしつつ、第3ブロックをロードしつつ、第2ブロックを計算
第2ブロックをストアしつつ、第4ブロックをロードしつつ、第3ブロックを計算
第3ブロックをストアしつつ、第4ブロックを計算
第4ブロックをストア <- 何も計算していない!
条件分岐(先頭に戻るかループを抜ける)
}
こういった待ち時間(レイテンシ)を埋める為に、次のイテレーションから、命令を持ってくるという操作をソフトウェアパイプライニングと言います。場合によっては次の次以降のイテレーションから持って来ても良いです。VideoCore IVは価格の高いGPUのように命令のOut-of-order実行は(恐らく)行ってくれませんので、こういった努力が大切だと思います。
もちろん、マルチスレッド化によってもレイテンシを隠蔽出来ます。NVIDIAのGPUでいうwarpですね。VideoCore IVのQPUは同時に2スレッド走らせる事が出来ます。
シングルスレッドでのベンチマーク
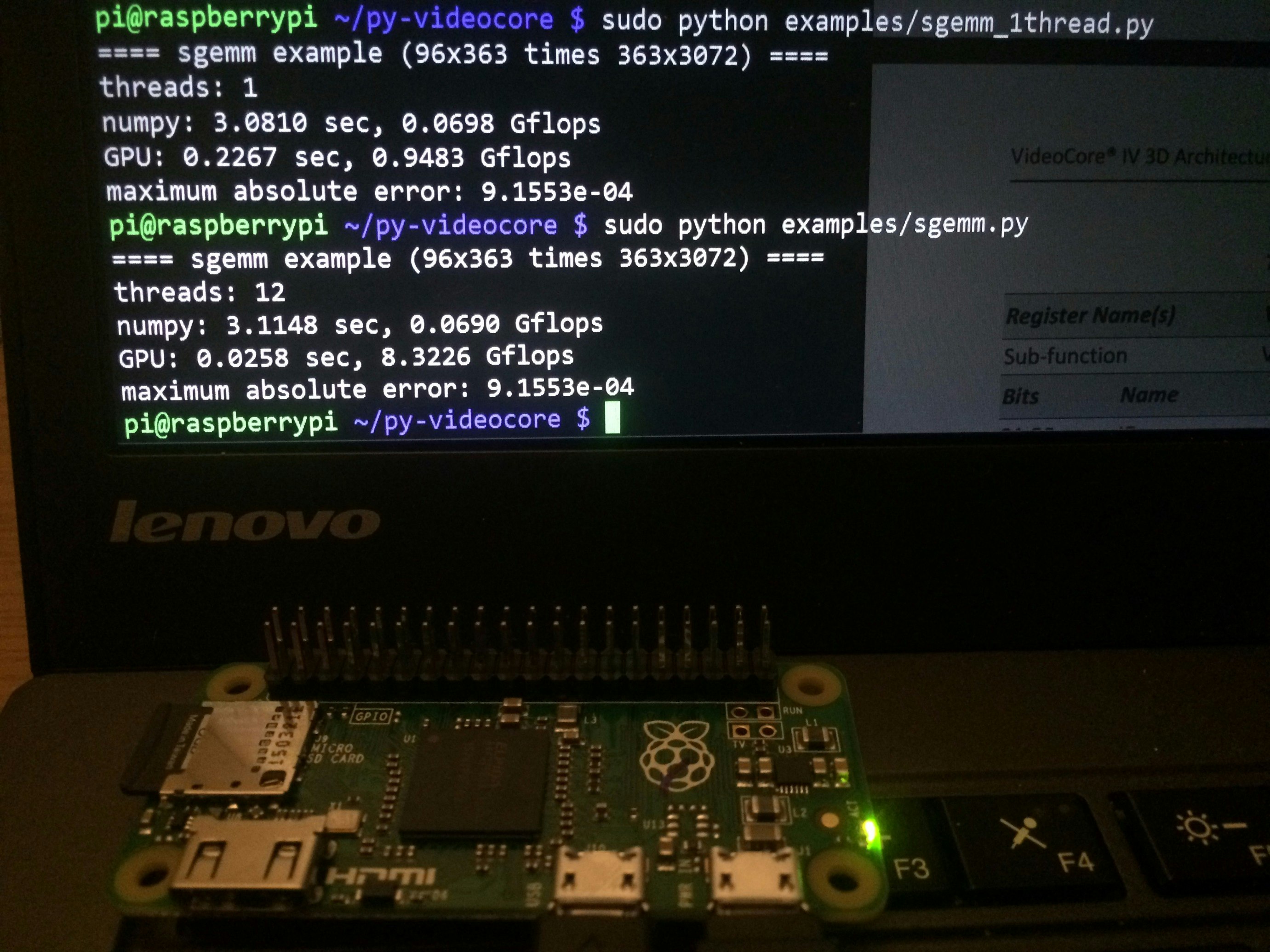
ここまででQPU 1つを使って走らせる事が出来るようになりましたのでベンチマークを取ってみました。マシンは先日購入したRaspberry Pi Zeroを使いました。搭載しているCPU,GPUはRaspberry Pi 1と同じで、CPUのクロックだけ1Ghzに向上しています。
使用したソースコードは以下です。
以下が結果です。ここではpi-gemmに合わせて、Aの型を96x363、Bを363x3072にしてます。
| 実装 | スレッド数 | 実行時間 | 実測性能 |
|---|---|---|---|
| numpy(BLAS) | CPU 1スレッド | 3.05秒 | 0.070 Gflops |
| pi-gemm | QPU 12スレッド | 0.21秒 | 1.02 Gflops |
| 私の | QPU 1スレッド | 0.23秒 | 0.95 Gflops |
QPU 1つで大体pi-gemmに追いつくくらいまで速くすることが出来ました。ただ、QPU 1つの理論性能は2Gflopsなので、その50%程度しか性能が出なかったというのは残念です。いろいろ測ってみたところ、Uniforms Cacheが期待していたよりも遅く、1 QPUの状態で一回のloadに2命令ほども掛かっていました。するとk-loop bodyの長さがざっと2倍になるので、50%程度という事になります。QPUの数を増やすとキャッシュミスが増加するので、効率はさらに下がってしまいます。1回のloadが4バイトだけですし、SoCで距離も近いですからある程度期待していたんですが・・・。
L.k_loop
fadd(ra1, ra1, r0).fmul(r0, r4, uniform) # こいつらが大体7~8クロックほどのよう(2命令分)
fadd(rb1, rb1, r0).fmul(r0, r4, uniform)
...
fadd(rb31, rb31, r0, sig='load tmu0').mov(uniforms_address, r2)
iadd(r2, r2, r3).mov(tmu0_s, r1)
jzc(L.k_loop)
iadd(r1, r1, 4).fmul(r0, r4, uniform) # delay slot # こいつが30クロックほどのよう
fadd(ra0, ra0, r0).fmul(r0, r4, uniform) # delay slot
fadd(rb0, rb0, r0).fmul(r0, r4, uniform) # delay slot
これを改善するにはどうすれば良いだろうかと考えています。
TMUにはL1 Cacheがついていて、Uniforms Cacheより速いようですが、アドレス計算の為にALUを消費するので、次々と異なるベクトルを読むのには向いていません。TMUでベクトルを最初に2本読んで、1本に対してrotateとbroadcastを繰り返しながら直積を計算するという手もありそうです。これもrotateでALUを消費してしまいますが、キャッシュを叩く回数が減るのでQPUを増やした時の性能がましになるかもしれません。
QPU-VPM間は実はそんなに遅くなくて、QPUが1つの時はread/writeがどちらもstallせずに出来ました。ただし、VPMは全QPUが共有しているのでQPUを増やすと結局遅くなります。あと、VPMで行列AとかBを読むようにすると、DMAの回数がすごく増えてしまうという問題もあります。
とりあえず、各キャッシュの性能を測って内部構造を調べるのが先だろうと思います。以上は今後の課題にして先に進む事にします。
[追記] Uniforms Cacheは機構上ソフトウェアプリフェッチが出来ないと思っていましたが、L2キャッシュはTMUと共有ですから、TMUを使えばL2まではあらかじめUniformsを引っ張っておく事が出来そうです。
VideoCore IV 3D Architecture Reference Guideより引用
QPU間の並列化
VideoCoreは12個のQPUを搭載しています。今回は各QPUで1スレッドずつ、計12スレッドを走らせます。そこで、下図のように行列$A$を横にいくつかに分割し、$B$は縦にいくつかに分割しこれらの積を各QPUに担当させます。
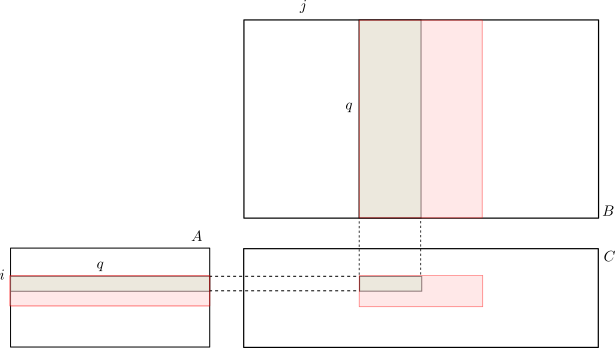
同期制御・排他制御
通常のマルチスレッドプログラムと同様に、共有リソースへのアクセスに関する排他制御が必要です。その為に、VideoCore IVにはmutexが1つと4bitのセマフォが16個用意されています。
これらをつかって同期制御を書いていくんですが、今回は同期が必要な部分をまるまるmutexで囲うという手抜きをしました。もちろん、性能には多少響いているはずですが・・・。
QPUが共有する資源には主に
- VPM
- DMAコントローラ(load用のVCD, store用のVDW)
- これらの設定や起動用のレジスタ
等がありますが、
VPMのreadセットアップは同時に2つまでしか発行できずqueueが満杯の時は無視される。(リファレンスガイドP56)
とか
DMAでのloadは前のやつが終わるまで発行できない。storeも同様。(同P56)
みたいな制約がいくつかあります。どちらも「前の~が終わるまでstall」のような親切はしてくれず、リクエストが無視されたりRaspi自体が停止してしまったりします。また、リファレンスガイドに書いていない制約もあるようです(特にextra stride setup registerに関して)。これに自前のアセンブラのバグが重なったりしたので、なかなかの苦行でした。
前者の「2つまでしか~」のようなリソースの数に限りがある状況を扱う為にセマフォを使います。
全スレッドの内の1つをマスタースレッドにしておいて、最初にそいつがセマフォを2だけ上げます。VPMを読みたいスレッドはこのセマフォを1つ下げ、使い終わったら1つ上げます。0以下に下げようとしたスレッドは待ち状態になりますので、これで同時に使用するのは2つまでという状況が実現できます。ロックも同様にセマフォで出来ます。
今回はまるまるmutexで囲ったのでこの部分ではセマフォを使わなかったんですが、スレッドの終了を同期させる所で使用しています。マスタースレッドは全スレッドの計算が終わるまで待ってから、ホストに割り込みを発行する必要があります。
仮にスレッドが12あるとした場合の同期の手順は以下のようになります。
- 各スレッドは自分の担当する計算が終わったら、セマフォを1上げる。
- マスタースレッドはセマフォを12回下げ終わった後、ホストに割り込みを発行し終了する。
とてもシンプルですね。以下が該当部分のコードです。
sema_up(COMPLETED) # Notify completion to the thread 0
...
mov(null, uniform, set_flags=True) # thread index
jzc(L.skip_fin)
nop(); nop(); nop()
# Only thread 0 enters here.
for i in range(n_threads):
sema_down(COMPLETED) # Wait completion of all threads.
interrupt()
L.skip_fin
exit(interrupt=False)
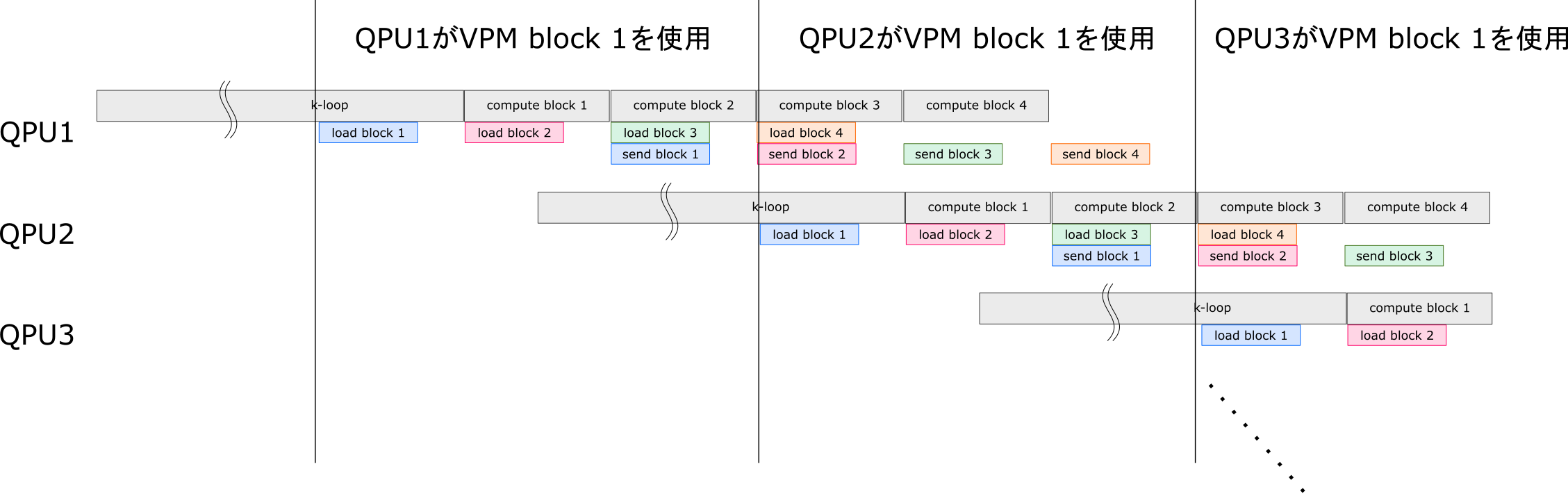
本当は下図のようにブロック4つの処理をパイプライン化しようと思っていました。そのうち時間が出来たらトライするかもしれません。
ベンチマーク
コードは以下です。
行列サイズは先ほどと同じく、Aが96x363、 Bが363x3072です。12スレッドの時はAを2分割、Bを6分割の時が最も高速でした。A用のキャッシュ(TMU)とB用のキャッシュ(Uniforms)が上手く釣り合うのがこのあたりなんだろうと想像しています。細かな研究はそのうちやります。
| 実装 | スレッド数 | Aの分割数 | Bの分割数 | 実行時間 | 実測性能 |
|---|---|---|---|---|---|
| numpy(BLAS) | CPU1スレッド | - | - | 3.05秒 | 0.070 Gflops |
| pi-gemm | QPU 12スレッド | - | - | 0.21秒 | 1.02 Gflops |
| 私の | QPU 1スレッド | 1 | 1 | 0.23秒 | 0.95 Gflops |
| 私の | QPU 12スレッド | 2 | 6 | 0.026秒 | 8.32 Gflops |
まとめ
- Raspberry PiのGPUで単精度の行列乗算を行ってみました。理論性能の約33%、8Gflopsくらいを出す事が出来ました。まだまだ努力の余地はあると思うので、頑張りたいと思います。
- numpy + BLASと比べると約120倍、pi-gemmと比べると約8倍速くなりました。
ちょうど私のlaptop(core i7-5600U 2.6GHz)でnumpy + BLASで(倍精度で)計算すると同じくらいの速度になります。つまり、Raspberry PiのGPUを頑張って使っても残念ながら普通のコンピュータで計算した方が速いです。Pi-Zeroは600円ですから、価格性能比だとお得かもしれないです。