Coursera の Machine Learning コース の日本語字幕で regularization の訳が正規化となっているためか、regularization を正規化と言っている人が散見されます。
(身近な人にもいましたし、"Coursera 正規化" 等でウェブ検索すると結構ヒットします)
しかし、regularization の訳は 正則化 が普通のはずです。
以前、大学の先生からの伝聞でその由来を聞きました。
Coursera の Machine Learning コース の Week 2 でも解説されているように、最小二乗誤差の線形回帰は解析解を求めることができ、その解は
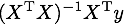
になります。
しかし、特徴量に対して学習データが少なすぎたりすると、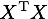 の部分が非正則になって、逆行列を求められなくなります。
の部分が非正則になって、逆行列を求められなくなります。
そこで、パラメータのL2ノルムの項 (正則化項) を入れることで、解析解は
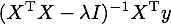
になります。
このように、正則化項を入れることによって解析解の の部分が 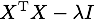
という正則行列 (regular matrix) になるので逆行列を求められるようになり、不良設定問題 (解が一意に定まらない) が解消されます。
このような背景から、regular matrix が正則行列と訳されていることと合わせて regularization は 正則化 というらしいです。
正規化は normalization の訳として使われています。
これはデータのスケーリングのことです。間違えないようにしましょう。