動作環境
GeForce GTX 1070 (8GB)
ASRock Z170M Pro4S [Intel Z170chipset]
Ubuntu 14.04 LTS desktop amd64
TensorFlow v0.11
cuDNN v5.1 for Linux
CUDA v8.0
Python 2.7.6
IPython 5.1.0 -- An enhanced Interactive Python.
v0.1 http://qiita.com/7of9/items/b364d897b95476a30754
sine curveを学習するコードをplaceholder使用に変更している。
input.csv生成
original (placeholder不使用)
linreg2.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import tensorflow as tf
import tensorflow.contrib.slim as slim
# ファイル名の Queue を作成
filename_queue = tf.train.string_input_producer(["input.csv"])
# CSV を parse
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
input1, output = tf.decode_csv(value, record_defaults=[[0.], [0.]])
inputs = tf.pack([input1])
output = tf.pack([output])
batch_size=4 # [4]
inputs_batch, output_batch = tf.train.shuffle_batch([inputs, output], batch_size, capacity=40, min_after_dequeue=batch_size)
## NN のグラフ生成
hiddens = slim.stack(inputs_batch, slim.fully_connected, [1,7,7,7],
activation_fn=tf.nn.sigmoid, scope="hidden")
prediction = slim.fully_connected(hiddens, 1, activation_fn=tf.nn.sigmoid, scope="output")
loss = tf.contrib.losses.mean_squared_error(prediction, output_batch)
# train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer(0.01))
train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer(0.001))
init_op = tf.initialize_all_variables()
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
sess.run(init_op)
for i in range(30000): #[10000]
_, t_loss = sess.run([train_op, loss])
if (i+1) % 100 == 0:
print("%d,%f" % (i+1, t_loss))
# print("%d,%f,#step, loss" % (i+1, t_loss))
finally:
coord.request_stop()
coord.join(threads)
v0.6 (placeholder使用)
.eval()を使わない方針とした。
http://qiita.com/7of9/items/40a7cfc741f4b11f50d2
linreg2_noEval.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
import tensorflow as tf
import tensorflow.contrib.slim as slim
# ファイル名の Queue を作成
filename_queue = tf.train.string_input_producer(["input.csv"])
# CSV を parse
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
input1, output = tf.decode_csv(value, record_defaults=[[0.], [0.]])
inputs = tf.pack([input1])
output = tf.pack([output])
batch_size=4 # [4]
inputs_batch, output_batch = tf.train.shuffle_batch([inputs, output], batch_size, capacity=40, min_after_dequeue=batch_size)
input_ph = tf.placeholder("float", [None,1])
output_ph = tf.placeholder("float",[None,1])
## NN のグラフ生成
hiddens = slim.stack(input_ph, slim.fully_connected, [1,7,7,7],
activation_fn=tf.nn.sigmoid, scope="hidden")
prediction = slim.fully_connected(hiddens, 1, activation_fn=tf.nn.sigmoid, scope="output")
loss = tf.contrib.losses.mean_squared_error(prediction, output_ph)
# train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer(0.01))
train_op = slim.learning.create_train_op(loss, tf.train.AdamOptimizer(0.001))
# def feed_dict(inputs, output):
# return {input_ph: inputs.eval(), output_ph: output.eval()}
init_op = tf.initialize_all_variables()
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
try:
sess.run(init_op)
for i in range(30000): #[10000]
# if 1 // no eval()
inpbt, outbt = sess.run([inputs_batch, output_batch])
_, t_loss = sess.run([train_op, loss], feed_dict={input_ph:inpbt, output_ph: outbt})
# else
# _, t_loss = sess.run([train_op, loss], feed_dict=feed_dict(inputs_batch, output_batch))
# endif
if (i+1) % 100 == 0:
print("%d,%f" % (i+1, t_loss))
# print("%d,%f,#step, loss" % (i+1, t_loss))
finally:
coord.request_stop()
coord.join(threads)
結果
python linreg2.py > log.learn_original
python linreg2_noEval.py > log.learn_noEval
matplotlibコード on Jupyter
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
data1 = np.loadtxt('log.learn_original', delimiter=',')
data2 = np.loadtxt('log.learn_noEval', delimiter=',')
input1 = data1[:,0]
output1 = data1[:,1]
input2 = data2[:,0]
output2 = data2[:,1]
fig = plt.figure()
ax1 = fig.add_subplot(2,1,1)
ax2 = fig.add_subplot(2,1,2)
# ax.plot(input1, output1, color='black', linestyle='dotted', label='rate=0.001')
ax1.plot(input1, output1, color='black', linestyle='solid', label='original')
ax2.plot(input2, output2, color='red', linestyle='solid', label='placeholder')
# ax.scatter(input1, output1)
ax1.set_title('loss')
ax1.set_xlabel('step')
ax1.set_ylabel('loss')
ax1.grid(True)
ax1.legend()
# ax2.set_title('loss')
ax2.set_xlabel('step')
ax2.set_ylabel('loss')
ax2.grid(True)
ax2.legend()
fig.show()
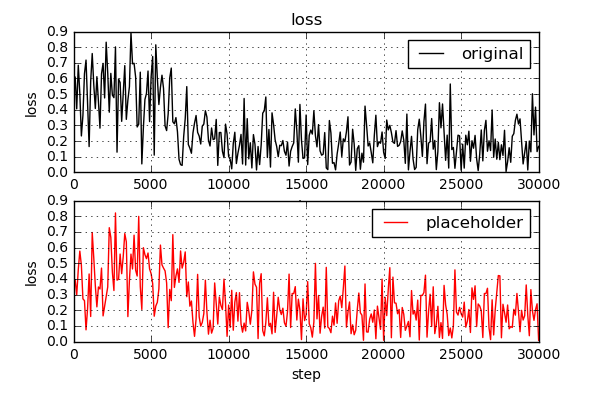
同じような結果がようやく得られた。
11/14から今日(11/20)まではまっていたので、結構苦労した。