最近Redshiftを業務で使う機会があったので、概要や使い方などをまとめてみようかと思います。
今回はRedshiftの立ち上げからはじめ、青空文庫さんが公開してくださっている、形態素解析データをRedshiftにいれて解析してみます。
解析といっても、一番多く幸せそうなワードを使っている文庫はどれかを調べるだけ。
一番多く幸せそうなワードを使っていた文庫を、「もっとも幸福な青空文庫」と判定します。
また、今回使用する、6.1GB、8770万行のデータをデフォルト設定でどのくらいでさばけるかなども試してみたいと思います。
今回やること
今回は以下の様なことをします。
・Redshiftとは何かをまとめ
・青空文庫のデータセットをダウンロードして、S3にアップ
・PostgreSQLが扱えるDBクライアントを用意する
・Redshiftを立ち上げる
・Redshiftにクライアントから接続する
・Redshiftにテーブルを作成して、データをロード
・SQLでデータ集計する
・Redshiftを削除する
Redshiftとは
まずはRedshiftとはなにかというところから。
Redshiftとは、「ビッグデータを扱うのに特化した、PostgreSQL互換の"DB"」です!
GBからTB、そしてペタバイト級のデータまで、SQLにて高速に検索、集計することができます。
"データウエアハウス"などととっつきにくい名称で呼ばれたりするせいでもの凄い難しいものという認識がある人もいると思いますが、まず使ってみる分には上記の認識で大丈夫かと。
(もちろん本格的に使う場合は、もっと特性を詳しく知っておく必要はあるでしょうが)
PostgreSQL互換なので、普通にPostgreSQLのドライバーを使ってSQLなどを実行できるので、とても扱い易いです。
ただ、ビッグデータ特化ということで、高速に検索できるといっても、あくまでビッグデータにしては、破格の速度。ということであり、0.1秒単位で結果を返すとか、そういうDBの用途には向いていません。
テラバイト級のデータでも、素早く集計、検索などが可能なかわりに、少量のデータのセレクトでも、そこそこ時間がかかる、というトレードオフをしています。
また、完全互換というわけではなく、いくつかのデータ型や構文が使えません。
インデックスなどもなく、代わりにソートキーなどというものが存在したりします。
フロントに使うよりは、バックエンドで集計するなどの用途に使われます。
うまく使えば、今までHadoopなどを使って何十分もかけて集計していたデータが、
SQLを使ってもっと簡単に、数十秒ほどで出来てしまうこともあります。
料金はなんと最安で一時間 $0.314!(dw2.large。160GBのSSD)
一時間30円ちょいでこの性能が使えるなんて、すごい技術革新ですねー。
値段表は下記にあります。
http://aws.amazon.com/jp/redshift/pricing/
青空文庫のデータセットをダウンロードして、S3にアップ
今回扱うデータは、青空文庫に入っている文章を、単語ごとに分解して
整理した、形態素解析データです。
詳しくはここを参照してください。
http://aozora-word.hahasoha.net/index.html
まずは
http://aozora-word.hahasoha.net/download.html
にアクセスして、
・解析対象データ一覧
aozora_word_list_utf8.csv.gz
・形態素解析全データ
utf8_all.csv.gz
をダウンロードしましょう。
その後、下記画面にてS3の適当なバケット内に上記ファイルをアップして下さい。
その際、リージョンは「Tokyo」にて行うようにしましょう。
https://console.aws.amazon.com/s3/home?region=ap-northeast-1
PostgreSQLが扱えるDBクライアントを用意する
既に普段使っているDBクライアントがある、という方が飛ばしてもOKです。
ない方は、なんでもいいんですが、今回は公式のチュートリアルでも使っているSQL WorkBenchを使いましょう。
下記にて、自身の環境にあ合ったものをダウンロードしてきて下さい。
http://www.sql-workbench.net/downloads.html
そのままだと、PostgreSQLのドライバーが用意されていないので、下記からドライバーのJarを
ダウンロードしてきて下さい。
http://jdbc.postgresql.org/download/postgresql-8.4-703.jdbc4.jar
”Driver”項目に”PostgreSQL”を選んで設定すると、ドライバーファイルが無いぞって
警告が出ると思いますので、その際に上記ドライバーを設定して下さい。
Redshiftのセキュリティを設定する
さあRedshift立ち上げ・・・。の前に、先に接続設定を作っておきます。
自身のローカルのIPに対し、接続を許可するためですね。
ここで多分、デフォルトVPCというのが用意されている人と、用意されていない人で設定方法が変わってくるかと思います。
デフォルトVPCがない人は、2013/03/11以前にAWSアカウントをとった人、デフォルトVPCがある人は、それ以降にアカウントをとった人・・・。だったはず。
私の環境だと、デフォルトVPCが無いので、下記でセキュリティ設定を作成できました。
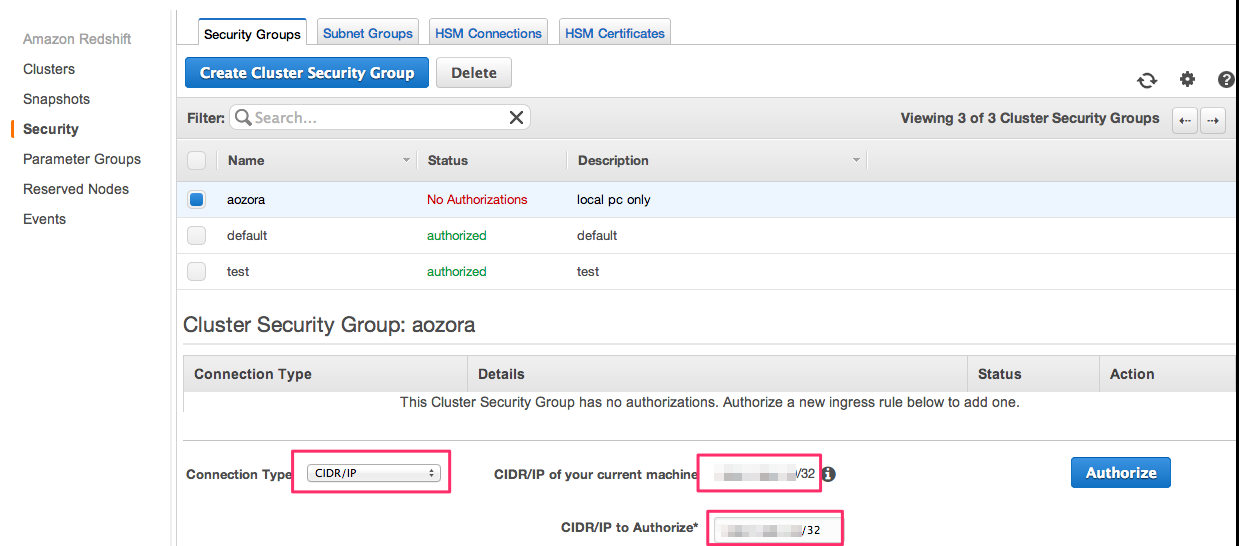
デフォルトVPCがない人の設定方法
下記画面にアクセス。
https://console.aws.amazon.com/redshift/home?region=ap-northeast-1#security:names=;cluster=
↓
「Create Cluster Security Group」押下。
↓
適当な名前つけて「Create」
↓
作成したSecurity Groupにチェックをつけると、下側に「Connection Type」の項目が出てくるので、「CIDR/IP」を選択。
↓
"CIDR/IP of your current machine"の項目に、自身のローカルPCのIPが出ていると思うので、それをコピー
↓
"CIDR/IP to Authorize”項目にペースト
↓
「Authorize」押下
デフォルトVPCがある場合の人の設定方法?
うろ覚えですが、こちらの画面で設定できたかと。
https://console.aws.amazon.com/vpc/v2/home?region=ap-northeast-1#securityGroups:
ここで、Redshiftに使用するセキュリティグループに対し、
「Edit」押下
↓
”Inbound Roles”タブで「Edit」押下
↓
Custom TCP Rule選んでPort Rangeに5439、IPに自身のIP(http://www.axisnetworks.biz/tools/gip/ とかで確認)を
入力して「Save」
で行けたかと。間違ってたらすみません。
Redshiftを立ち上げる
さあ、いよいよRedshiftを立ち上げましょう。
今回はTokyoリージョンにします。
下記画面にアクセスし、「Launch Cluster」を押下します。
https://console.aws.amazon.com/redshift/home?region=ap-northeast-1
ちなみに、Redshiftは無料枠とかなくて、立ち上げた瞬間から課金されるので、
一応注意しましょう。
今回は最小構成なので、一時間30円強で済むはずですが、念のため。
CLUSTER DETAIL画面
・Cluster Identifier
→ お好みで
・Database Name
→ お好みで
・Master User Name
→ お好みで
・Master User Password
→ お好みで(ただし、一文字は大文字や数字を含む事、のような制限あり)
他はデフォルトで「Continue]
NODE CONFIGURATION画面
・Node Type
→ dw2.large
・Cluster Type
→Single Node
他はデフォルトで「Continue]
Additional Configuretion画面
・Cluster Security Groups
→ 前項目で設定したセキュリティグループ
・Create CloudWatch Alarm
→ No
・※ Choose a VPC
ここで選択出来る状態になっている人と、出来ない状態になっている人がいる。
私は出来なかった。
他はデフォルトで「Continue]
Review画面
「Launch Cluster」
これで立ち上がったはずです!
Redshiftにクライアントから接続
立ち上げたRedshiftに接続していきましょう。
接続設定をメモる
の画面で、”Cluster Status”が"available"になったら、Cluster名をクリックして詳細画面へ。
"JDBC URL”項目をメモっておきます。
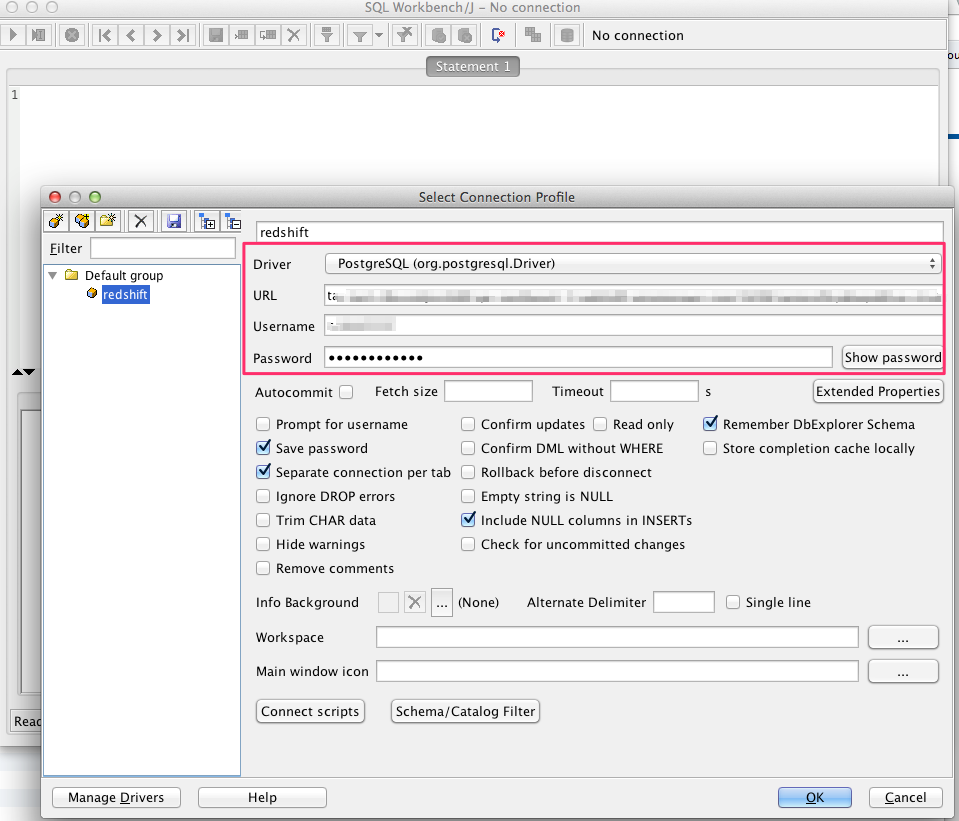
クライアントに接続設定を入力
上記で設定したSQL WorkbenchなどのDBクライアントを立ち上げ、接続してみます。
"Driver"項目に、PostgreSQL
"URL"項目にメモった”JDBC URL”
"Username"項目に、設定したユーザー名
"Password"項目に、設定したパスワード
を入力して「OK」を押下。
(ドライバーが無いと怒られたら、PostgreSQLのドライバーjarファイルを設定)
これで接続出来るはずです。
Redshiftにテーブルを作成して、データをロード
さあ、いよいよRedshiftを操作していきましょう!
ここまで長かった!
まずはテーブルを作成します。
create table aozora(
file text,
row int,
num int,
word text,
type text,
subtype1 text,
subtype2 text,
subtype3 text,
conjtype text,
congugation text,
basic text,
ruby text,
pronounce text
);
create table aozora_word_list(
work_id text,
work_name text,
work_name_yomi text,
hoge_1 text,
hoge_2 text,
hoge_3 text,
hoge_4 text,
hoge_5 varchar(5000),
hoge_6 text,
hoge_7 text,
hoge_8 text,
hoge_9 text,
hoge_10 text,
hoge_11 text,
author_id text,
author_sei text,
author_mei text,
hoge_12 text,
hoge_13 text,
hoge_14 text,
hoge_15 text,
hoge_16 text,
hoge_17 text,
hoge_18 text,
hoge_19 text,
hoge_20 text,
hoge_21 text,
hoge_22 text,
hoge_23 text,
hoge_25 text,
hoge_26 text,
hoge_27 text,
hoge_28 text,
hoge_29 text,
hoge_30 text,
hoge_31 text,
hoge_32 text,
hoge_33 text,
hoge_34 text,
hoge_35 text,
hoge_36 text,
hoge_37 text,
hoge_38 text,
hoge_39 text,
hoge_40 text,
hoge_41 text,
hoge_42 text,
hoge_43 text,
hoge_44 text,
hoge_45 text,
url text,
hoge_47 text,
hoge_48 text,
hoge_49 text,
hoge_50 text,
file text
);
commit;
aozora_word_listテーブルが適当なのはご愛嬌。
そしてCOPYコマンドにて、S3に配置したデータを投入。(7分くらい)
Gzip形式でもオプションをつければ投入してくれます。
ちなみにアクセスキーとシークレットキーが必要なので、ない人は下記を参考に作成しましょう。S3系を扱う権限はつけておいた方が良いと思います。
最近はもうIAMユーザーというのでしかアクセスキーとかを発行できなくなっているので、多少面倒かもしれません。
COPY aozora
FROM 's3://バケット名/utf8_all.csv.gz'
CREDENTIALS 'aws_access_key_id=アクセスキー;aws_secret_access_key=シークレットキー'
maxerror 5
delimiter ','
GZIP
CSV;
COPY aozora_word_list
FROM 's3://バケット名/aozora_word_list_utf8.csv.gz'
CREDENTIALS 'aws_access_key_id=アクセスキー;aws_secret_access_key=シークレットキー'
emptyasnull
blanksasnull
maxerror 5
delimiter ','
IGNOREHEADER 1
GZIP
CSV;
commit;
投入したデータを確認してみましょう。
select * from aozora_word_list where file = '14_14602.html';
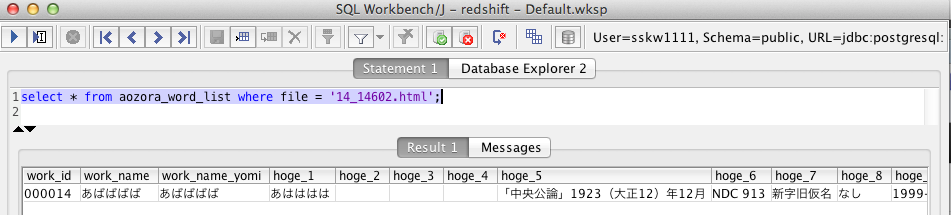
select * from aozora where file = '14_14602.html';
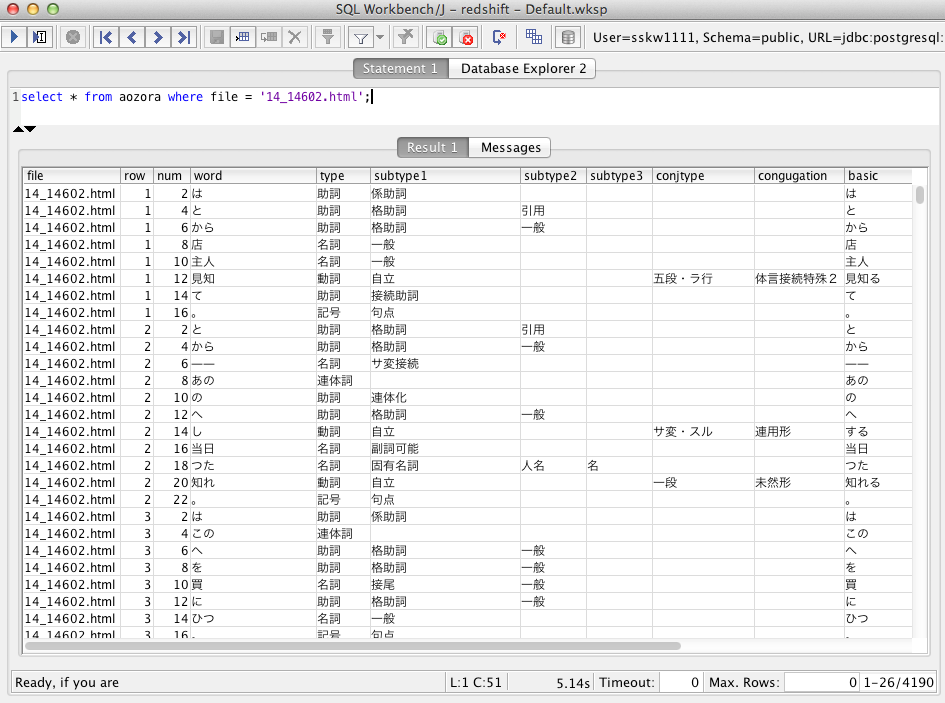
入ってますね?これでデータ投入は完了です!
SQLでデータ集計する
とうとう集計です!ここまできたら後は一瞬。
さあ、もっとも幸せな青空文庫を探してみましょう!
適当に幸福っぽい単語を条件にして集計してみます。
aozoraテーブルとaozora_word_listテーブルはfileカラムでjoin
しています。
select
awl.url, awl.work_name, count(*) cnt
from
aozora az
left join
aozora_word_list awl
on awl.file = az.file
where
az.word = '幸福' or az.word = '幸い' or az.word like '嬉%'
group by
awl.url, awl.work_name
order by
cnt desc
limit 30;
結果
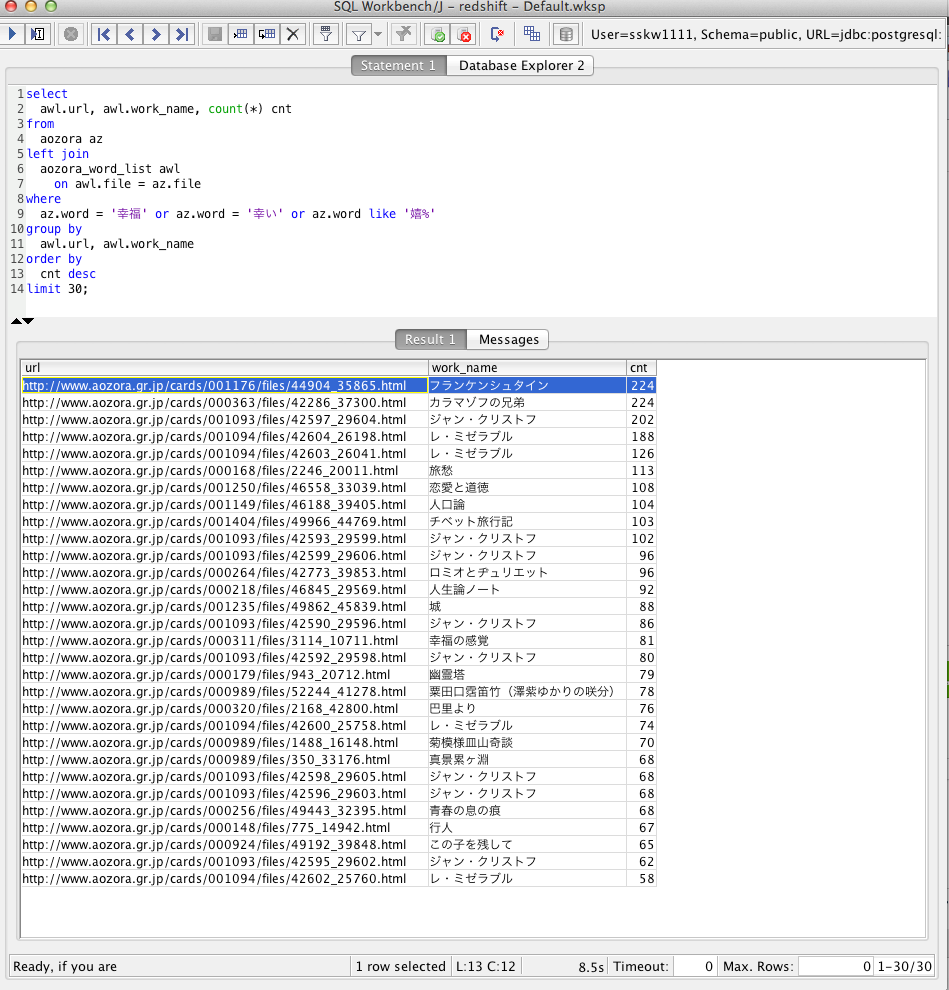
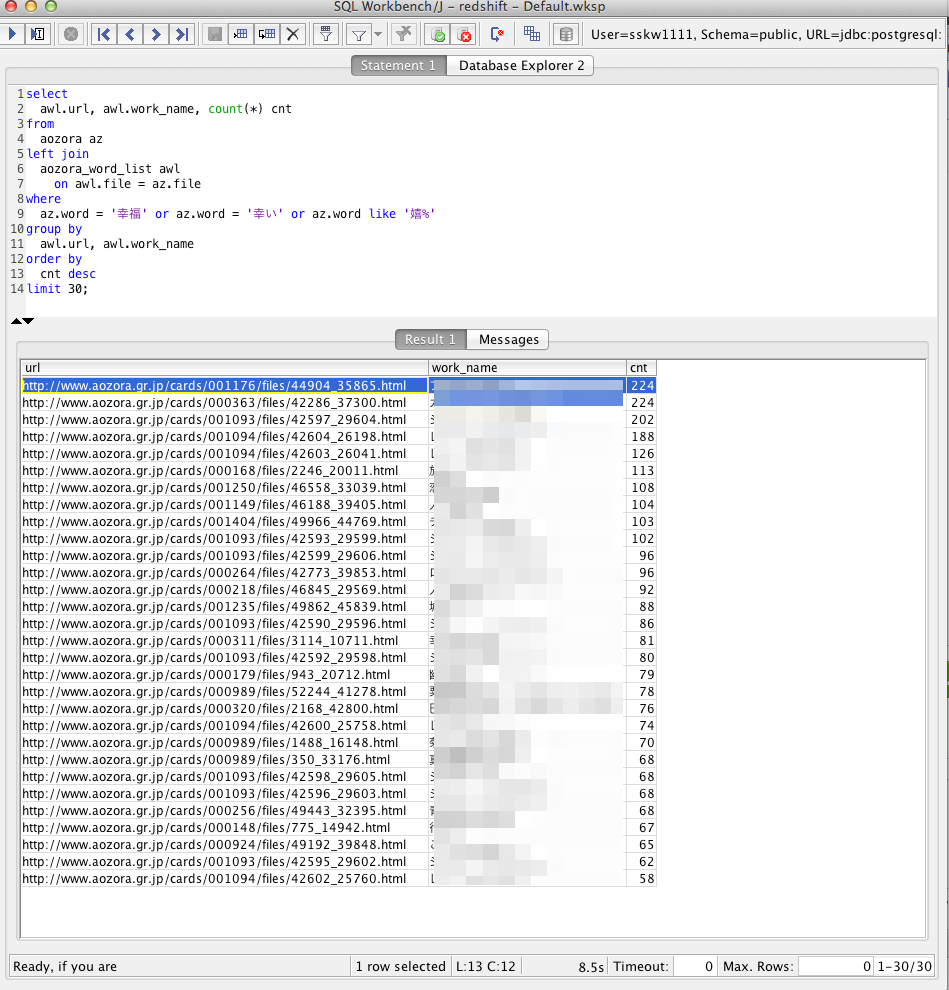
な、なんと、皆の予想を裏切って、もっとも幸福な青空文庫は、「フランケンシュタイン」と「カラマーゾフの兄弟」だと判明しました!!
http://www.aozora.gr.jp/cards/001176/files/44904_35865.html
http://www.aozora.gr.jp/cards/000363/files/42286_37300.html
幸せポイントは堂々の224ポイントです!
かかった時間は、たった8.5秒です!8700万行の集計でこれはなかなか凄いのではないでしょうか。完璧に幸福です!
さて、せっかくなので不幸せっぽいものも調べてみましょう。
select
awl.url, awl.work_name, count(*) cnt
from
aozora az
left join
aozora_word_list awl
on awl.file = az.file
where
az.word = '絶望' or az.word = '不幸' or az.word = '死' or az.word = '暗黒'
group by
awl.url, awl.work_name
order by
cnt desc
limit 30;
結果
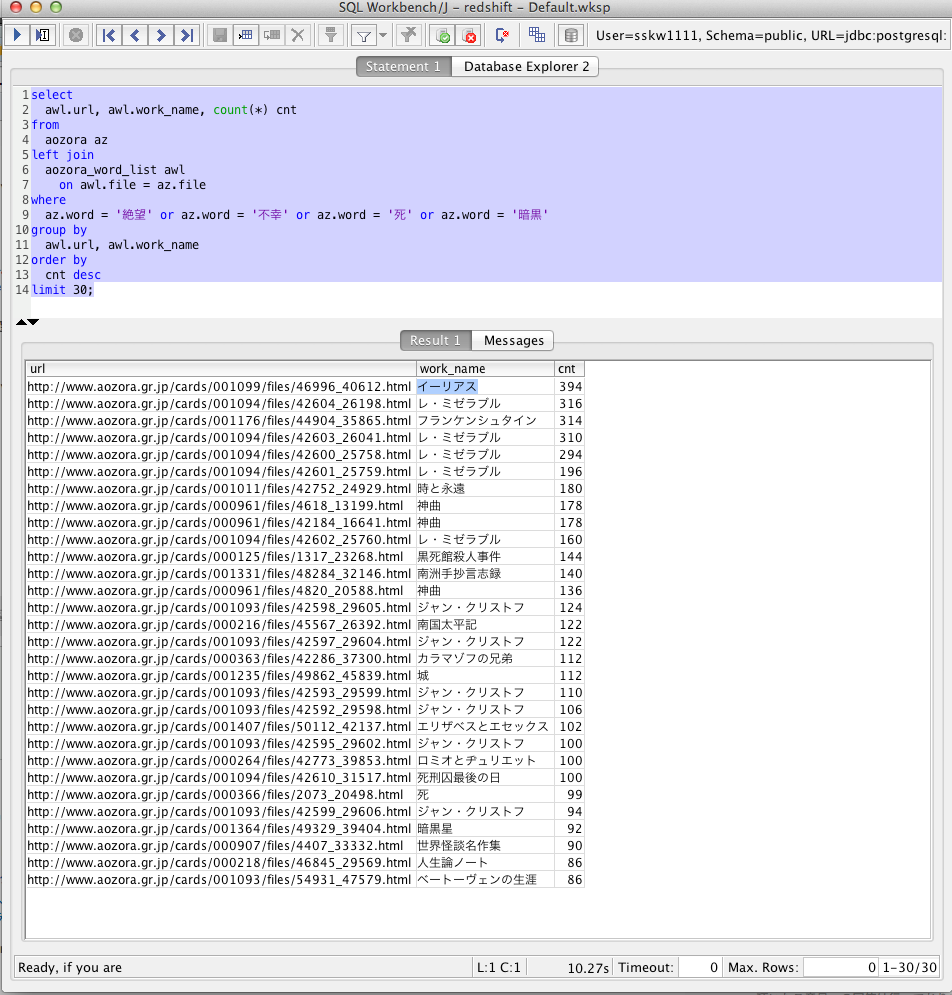
はい、そんなわけでもっとも不幸な文庫は「イーリアス」でした!
http://www.aozora.gr.jp/cards/001099/files/46996_40612.html
なんか3位にはもっとも幸せな文庫であるはずのフランケンシュタインが見えますね。
判定方法がてきt・・・げふんげふん。
Redshift削除
さて、判定が終わったのでRedshiftを停止します。
下記ページで稼働中のクラスター名をクリックして、詳細ページに飛びます。
https://console.aws.amazon.com/redshift/home?region=ap-northeast-1#
↓
"Cluster”セレクトボックスから、Deleteを選択
↓
現状の状態を保存しておきたければ、
"Create final snapshot"項目を"Yes"に、もう完全削除して良ければ"No"を
選択して"Delete"押下。
スナップショットをとっておけば、そのスナップショットを元に現在の状態を簡単に復元できます。
ただ保存料とかはかかるかも。
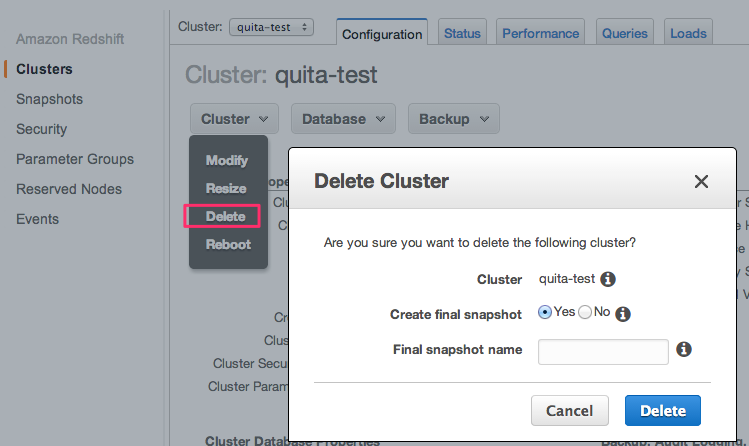
はい、これで終了です。
まとめ
8900万行ほどの大きいデータを、あっさり集計できるスーバーDBがこんなにあっさり作って消せる時代になりました。
スナップショットから簡単に復元する機能もありますし、インフラの負担も高くなさそうです。
最小構成でも160GBの容量を使えるので、結構使いどころは多いのでは無いかと思います。
しかも今回解析した8900万行でも、扱えるデータ量上限からすればほんとに微々たるものです。
良いサンプルデータがあれば、もっともっと大きなデータの解析も試してみたいですね。
最後にですが、クラスターの削除し忘れには気をつけましょう。
以上です。