タダで留学できると話題のトビタテ留学JAPANという留学奨学金プログラムはご存知でしょうか?
ぼくは、そんなトビタテ留学JAPANの学生が留学体験記を投稿しているトビタテジャーナルというサイトの運営・開発をしています。サイトのデータベースから投稿されたテキストを分析してみると、留学生はどんな単語をよく使っているのかという質問に答えたり、分類ごとにクラスタリングしていくことができそうです。自分でブログやメディアなどを運営している人はそういうことが気になって分析してみたいと思ったことは1度や2度ではないのではないでしょうか?
ただでさえテキスト・データを加工したり、分析するのは手間がかかる作業ですが、特に日本語になると、英語などの言語と違い、単語と単語の間にスペースがないので、トークナイズ(単語ごとに分ける)するのがさらに難しいです。ただ、知ってる人も多いかと思いますが、オープンソースで、MeCabという、Google 日本語入力開発者の一人である工藤拓さんによって開発されたライブラリを使うと日本語をトークナイズするのが簡単にできます。さらに都合のいいことに、RでMeCabが使えるように、石田基広さんが作られたRMeCabというのがあるので、それを使うと簡単にRで、つまりはExploratoryの中でテキスト・データをトークナイズしていくことができます。
今日は、そのMeCabのインストール、さらにそれをExploratoryの中で使うためのセットアップ、そして軽く日本語データに対するテキスト分析の方を順を追って説明していきたいと思います。
Mecabと辞書をインストール
以下にMacでのインストールを説明しますが、Windowsの方は、こちらを参照してください。
環境
- MacOX 10.11.6(ElCapitan)
- Homebrewがインストールされていること。Homebrewを持ってない方は、こちらからHomebrewをダウンロードしてください。
MacでMecabを使うためには、Mecab本体と辞書の2つをインストールする必要があります。
brew install mecabで、Mecab本体をインストールします。
brew install mecab
次に、brew install mecab-ipadicで、Mecabで利用する辞書をインストールします。
brew install mecab-ipadic
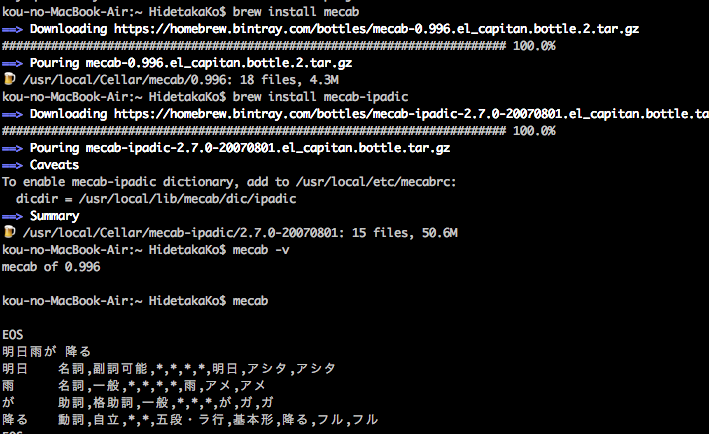
次のように表示されれば、インストールは成功しています。
RMeCabをインストールする
次に、RからMeCabが使えるようRMeCabをインストールしましょう。こちらもMacでの例を説明しますが、Windowsの方はこちらを参照してください。
ターミナルから次のコマンドを打ち込んで下さい。
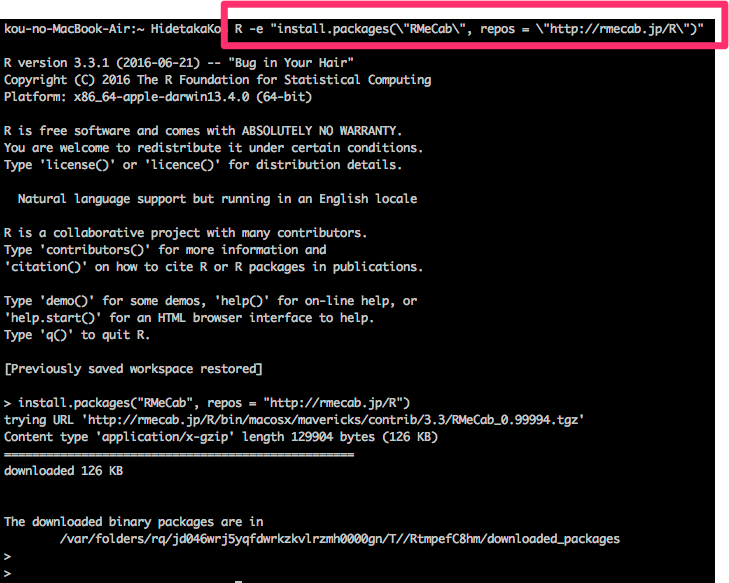
R -e "install.packages(\"RMeCab\", repos = \"http://rmecab.jp/R\")"
次のように表示されれば、インストールは成功しています。
RMeCabにある機能を、Exploratoryで使いやすくするように、関数を定義する
RMeCabのトークナイズの関数をExploratoryの仕組みの中で使いやすくするように、こちらに関数を定義しましたので、下記のコードをこちらからダウンロードしてください。
mecab_tokenize <- function(tbl, text_col, .drop=TRUE){
loadNamespace("RMeCab")
loadNamespace("tidyr")
text_cname <- as.character(substitute(text_col))
text <- tbl[[text_cname]]
tokenize <- function(text){
tokens <- unlist(RMeCab::RMeCabC(text))
data.frame(.token = tokens, .pos = names(tokens))
}
if(.drop){
tbl[[text_cname]] <- lapply(text, tokenize)
token_col <- text_cname
} else {
tbl$.token <- lapply(text, tokenize)
token_col <- ".token"
}
tidyr::unnest_(tbl, token_col)
}
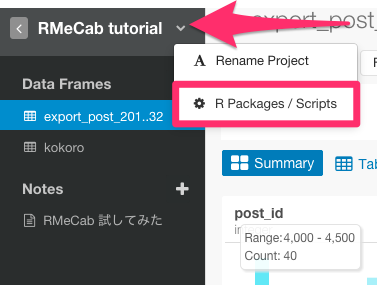
次に、矢印の部分を押して、R packages/Scriptsを選んで下さい。
矢印のAddボタンを選んで下さい。
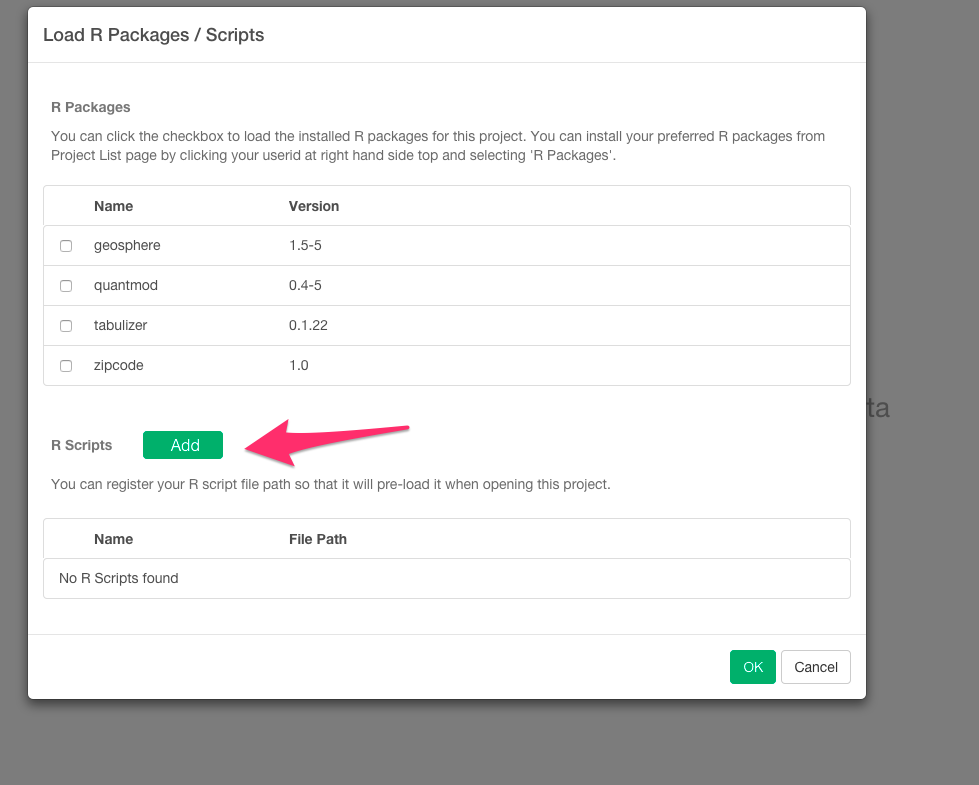
さっき関数を定義したファイルを選んで下さい。
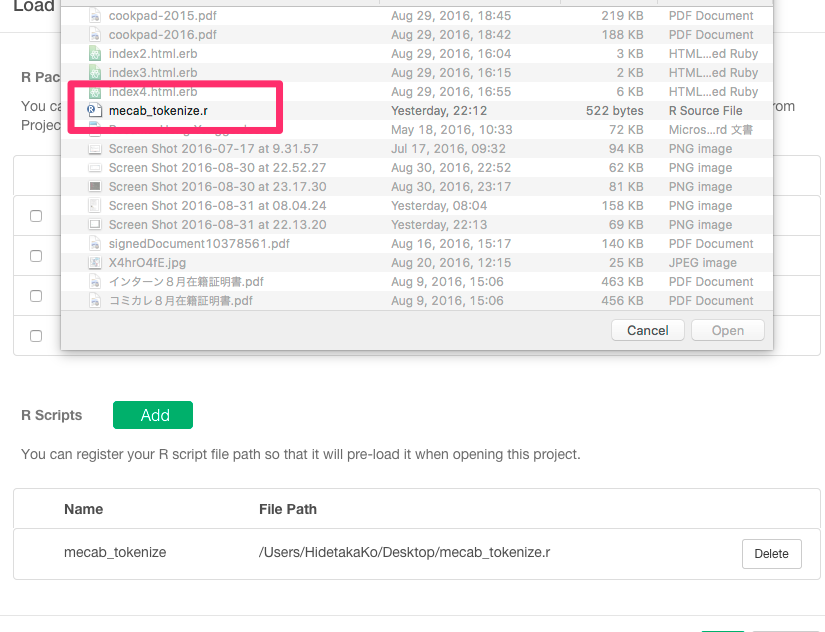
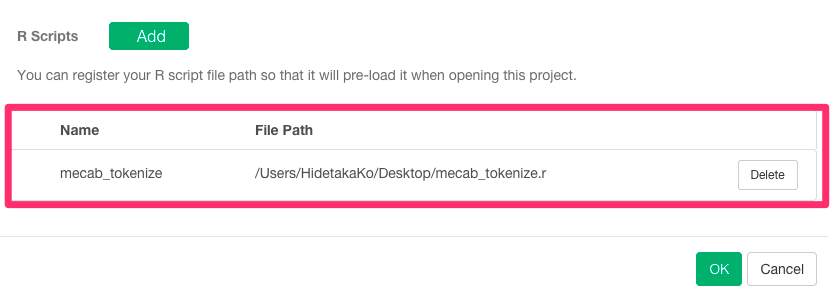
しっかり保存されていますね。
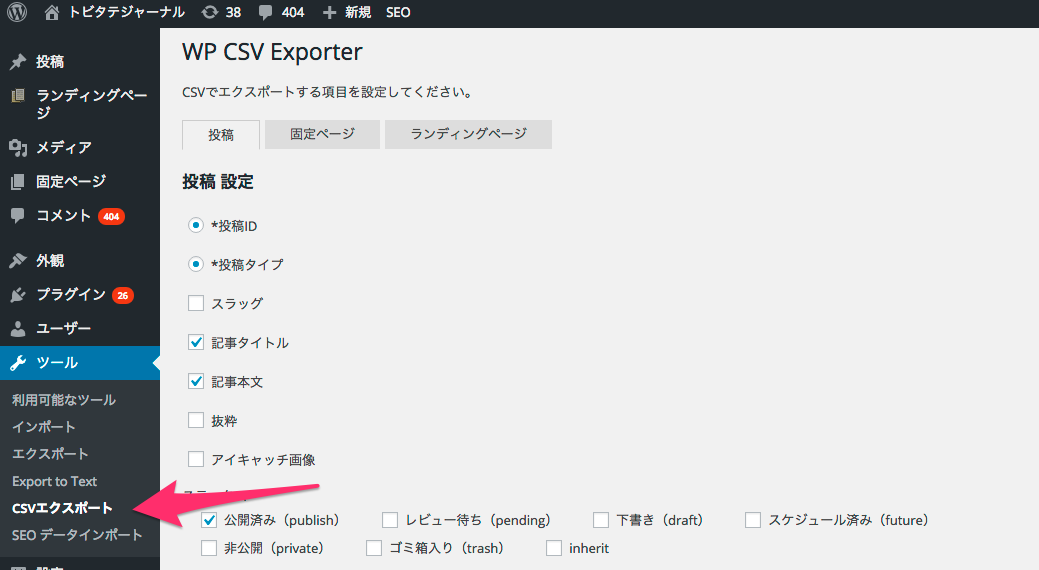
Wordpressの投稿データをCSVエクスポートする
管理者画面から、投稿データをCSVエクスポートします。
このCSVをExploratoryにインポートします。
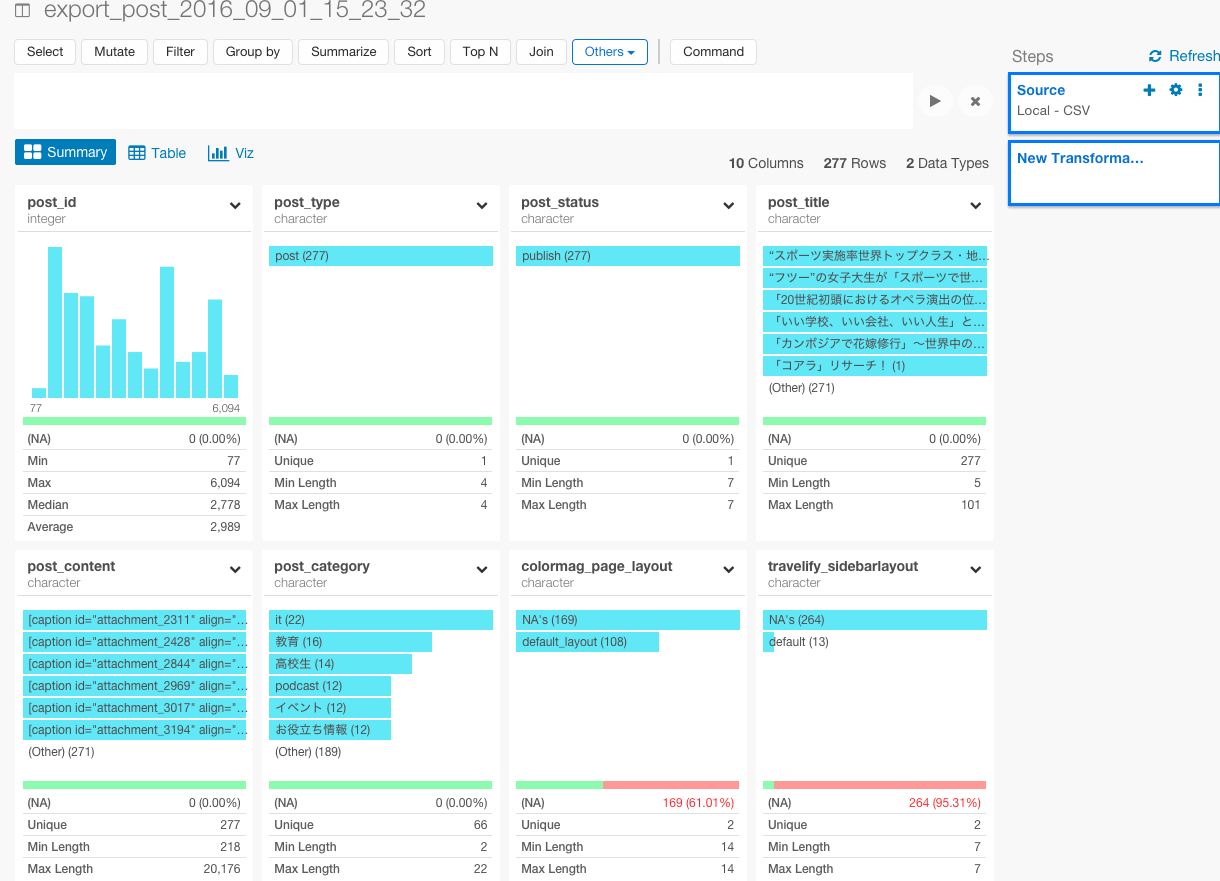
これで、テキスト分析をしていくための土台が整いました。
WordpressでCSVエクスポートができない方は、こちらからWP CSV Exporterというプラグインをダウンロードしてください。
テキスト分析をする
トークナイズする
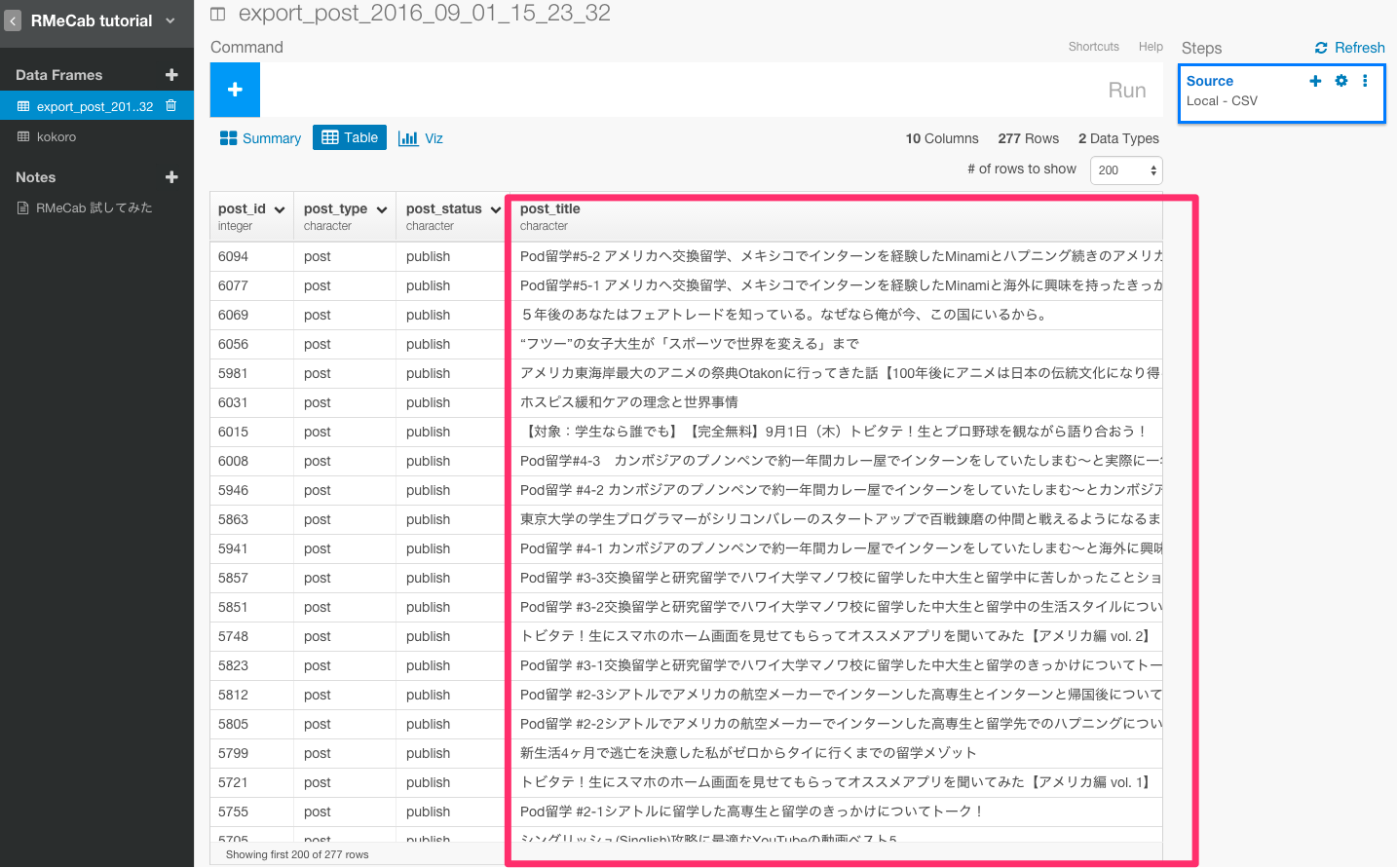
上記のタイトルの文章を先ほど定義した関数を使って、トークンナイズしましょう。
mecab_tokenize(text_col=post_title)
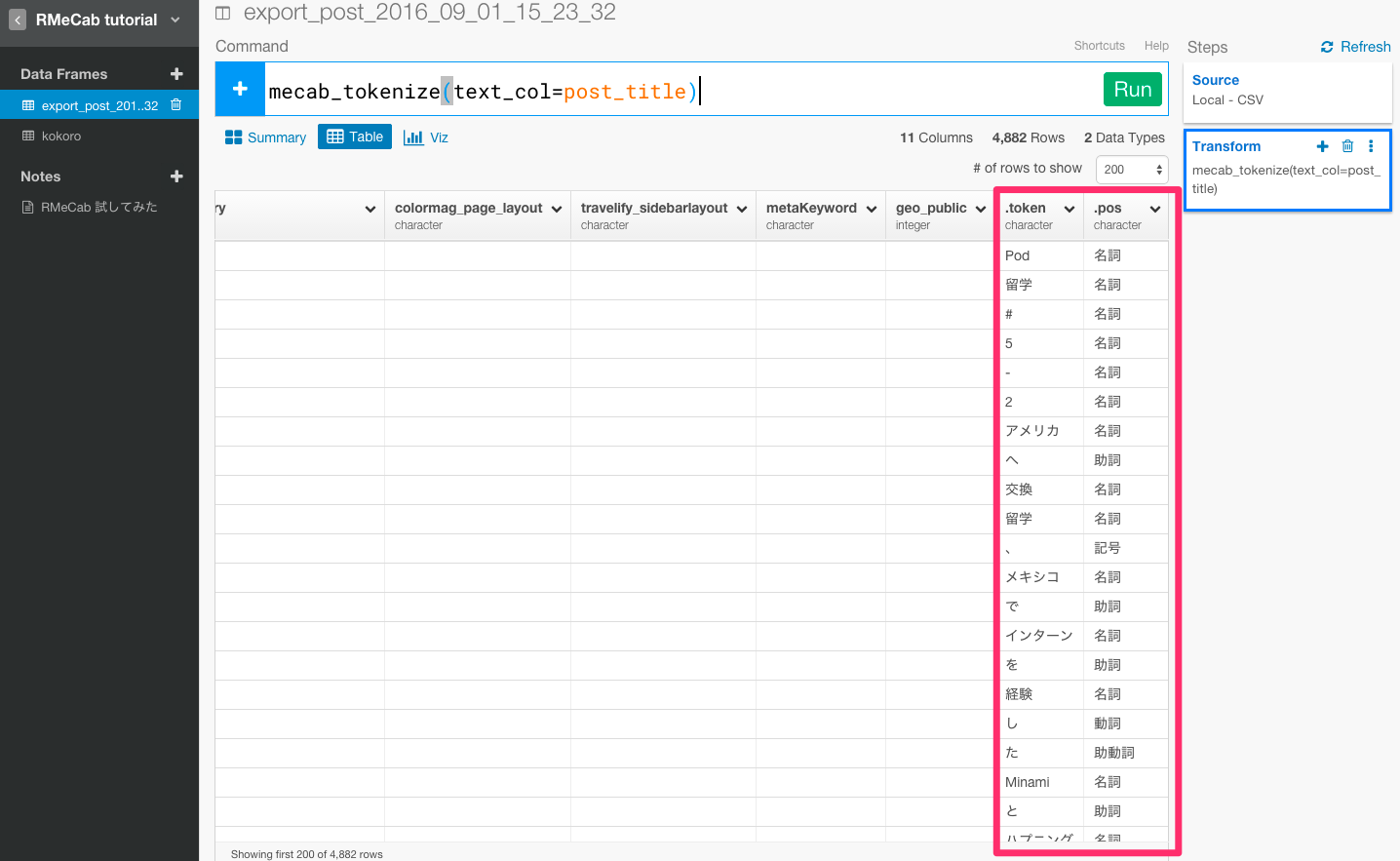
これで、先ほどまで文章だったpost_title列が単語毎に分かれましたね。
stopwordを取り除く
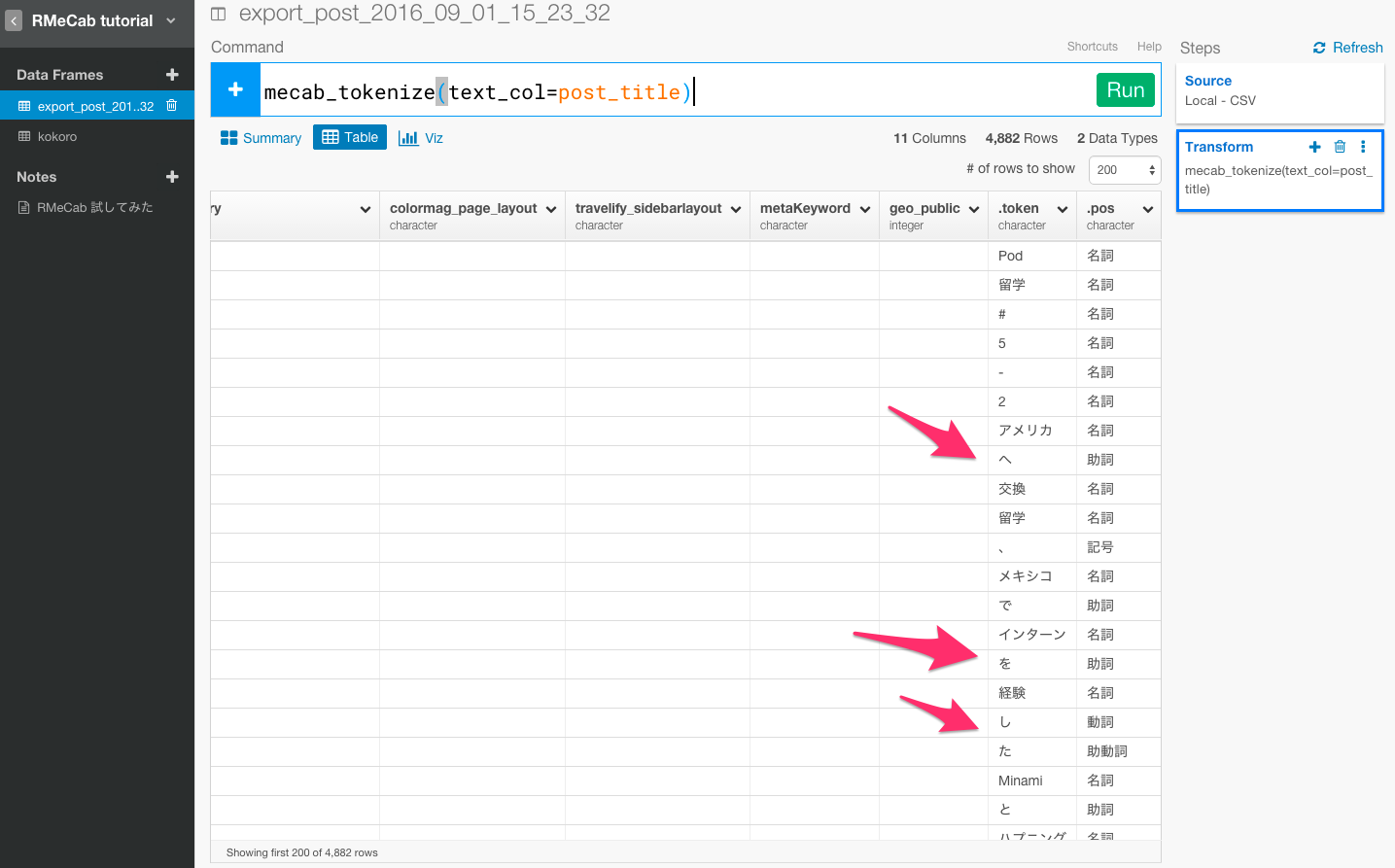
次に、今のままだと、矢印のように、日本語には、意味のない不要な単語が多く含まれています。これらの単語をstopwordsと呼んでいます。
意味のあるテキスト分析をするためには、これらの単語を取り除く必要があります。そのために、こちらに日本語の不要な単語リストがまとまったファイルがあります。ダウンロードして拡張子をcsvに変えてExploratoryにインポートしてください。その際は、「あそこ」がカラム名にならないように、First Row as HeaderをNoに変えてください。
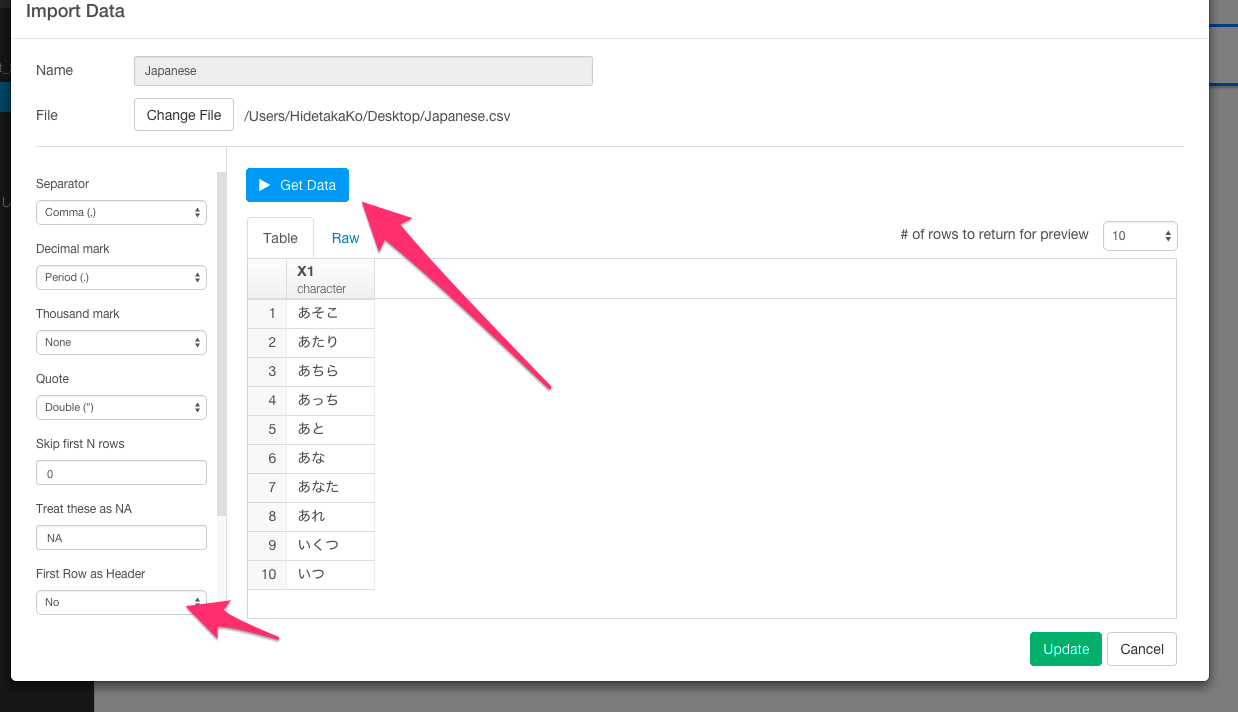
一度こちらのデータをJapaneseという名のデータ・フレームにしてインポートしましたら、次に、anti_joinという関数を使って、このJapaneseデータ・フレームに入っていないデータだけを残すというオペレーションを行います。
anti_join(Japanese, by=c( ".token" ="X1"))
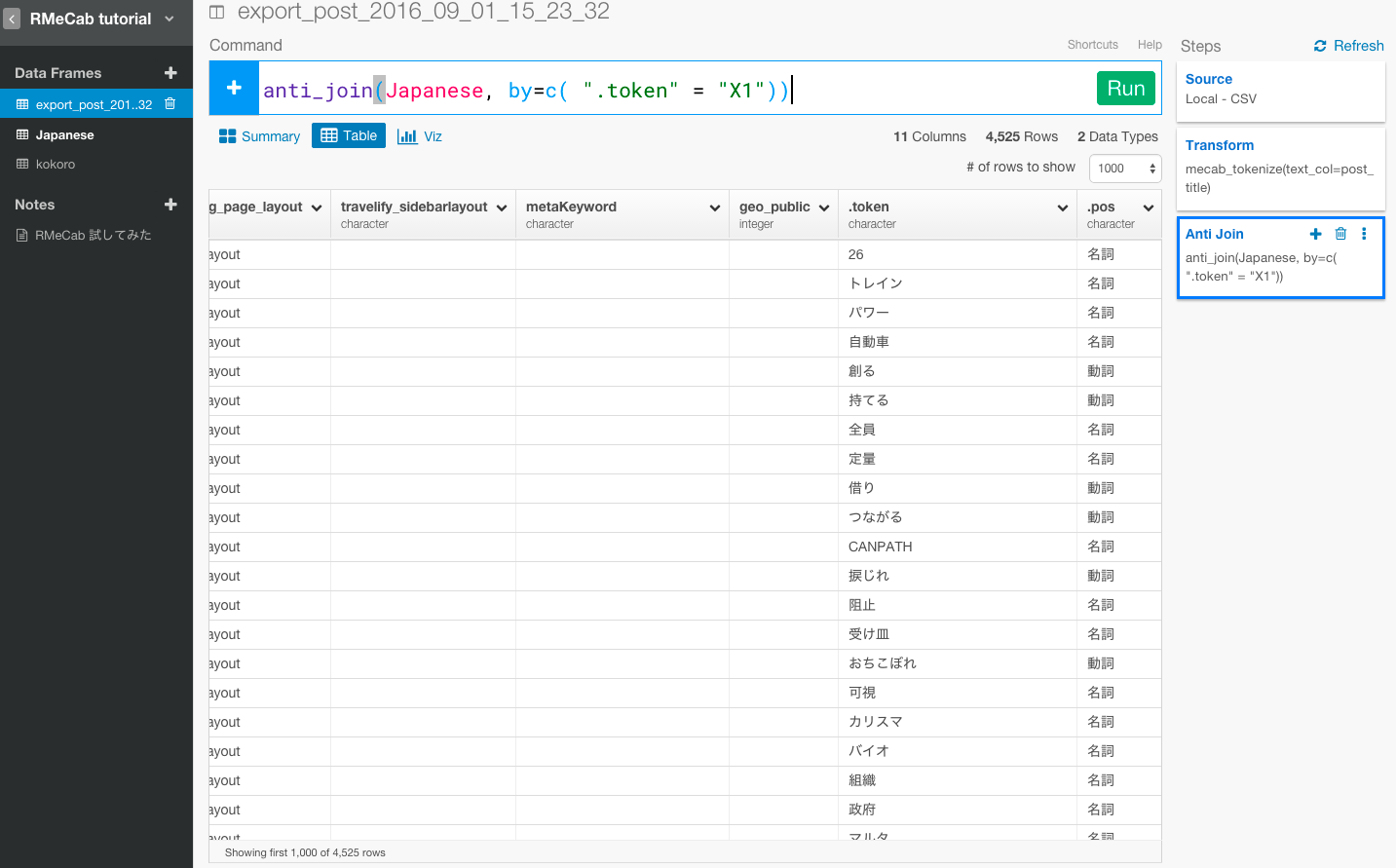
不要な単語が取り除かれたのが確認できました。
さらに不要なデータを取り除く
次に、データを見ていくと記号がいくつか入っていることに気が付きます。よく考えてみると、助詞や助動詞や副詞や接頭詞なども不要であることに気が付きます。なので、名詞と動詞だけに絞ってフィルタリングしていきましょう。
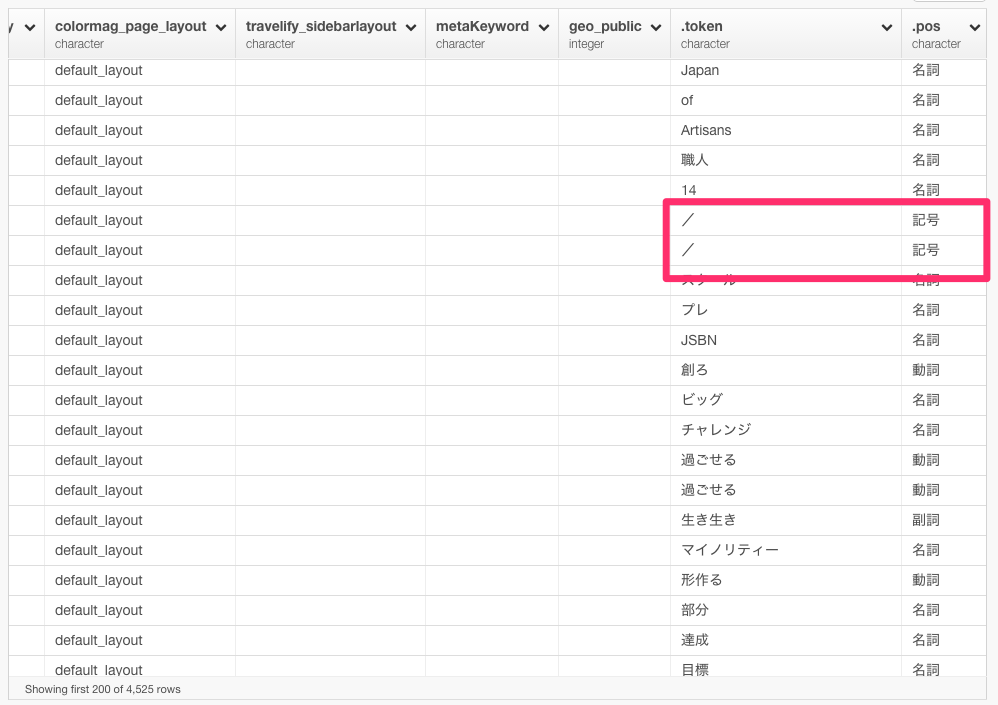
filter(.pos %in% c("動詞","名詞"))
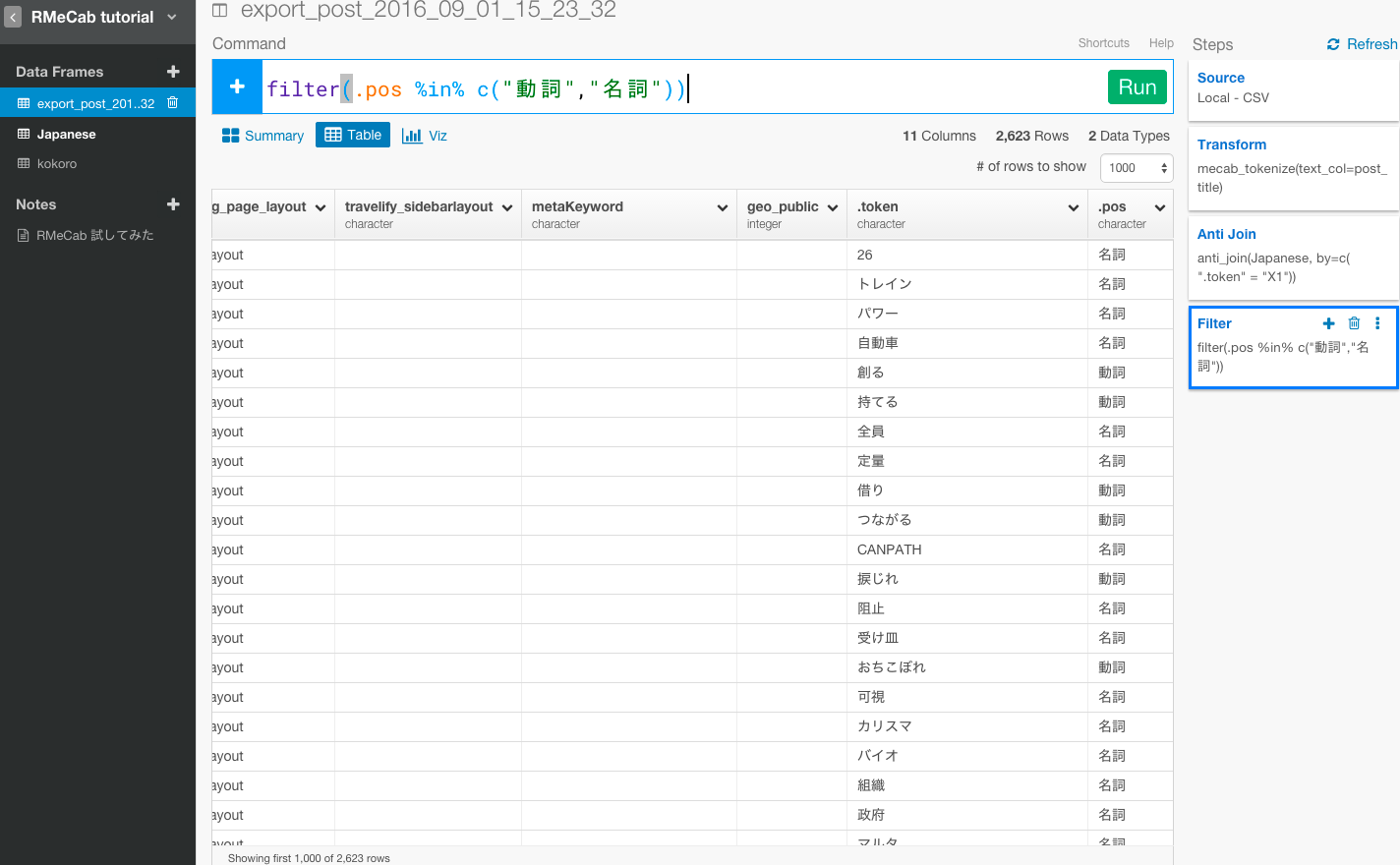
次に、字数が1文字以下のテキストデータも意味がないので取り除きましょう。
filter(str_length(.token)>1)
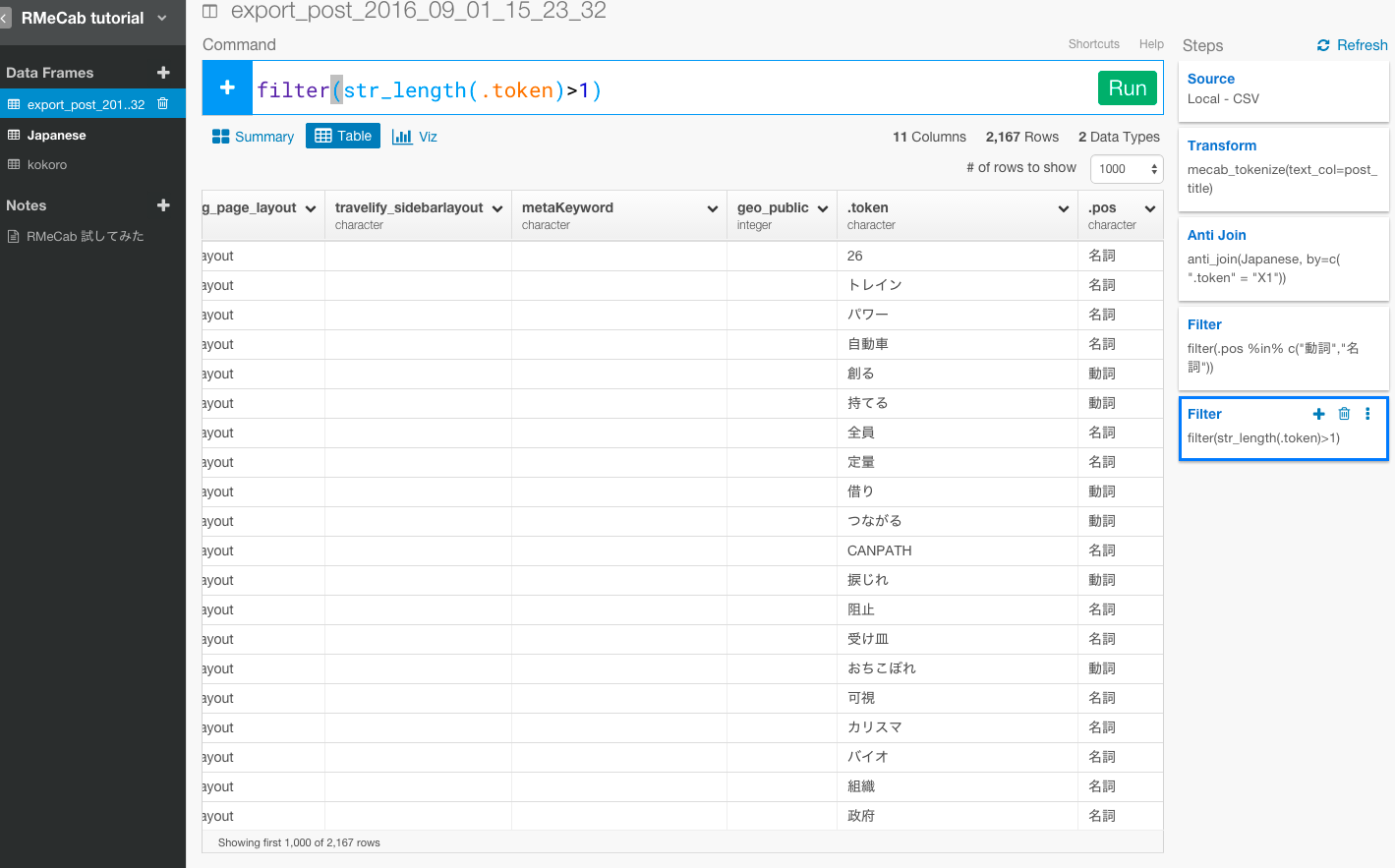
これで不要な単語はほとんど取り除くことができました。
トップ20を計算する
次に、最もよく頻出している意味のある単語トップ20を計算して出したいと思います。それぞれの単語の個数を数えるために、まず、.token列をグルーピングします。
group_by(.token)
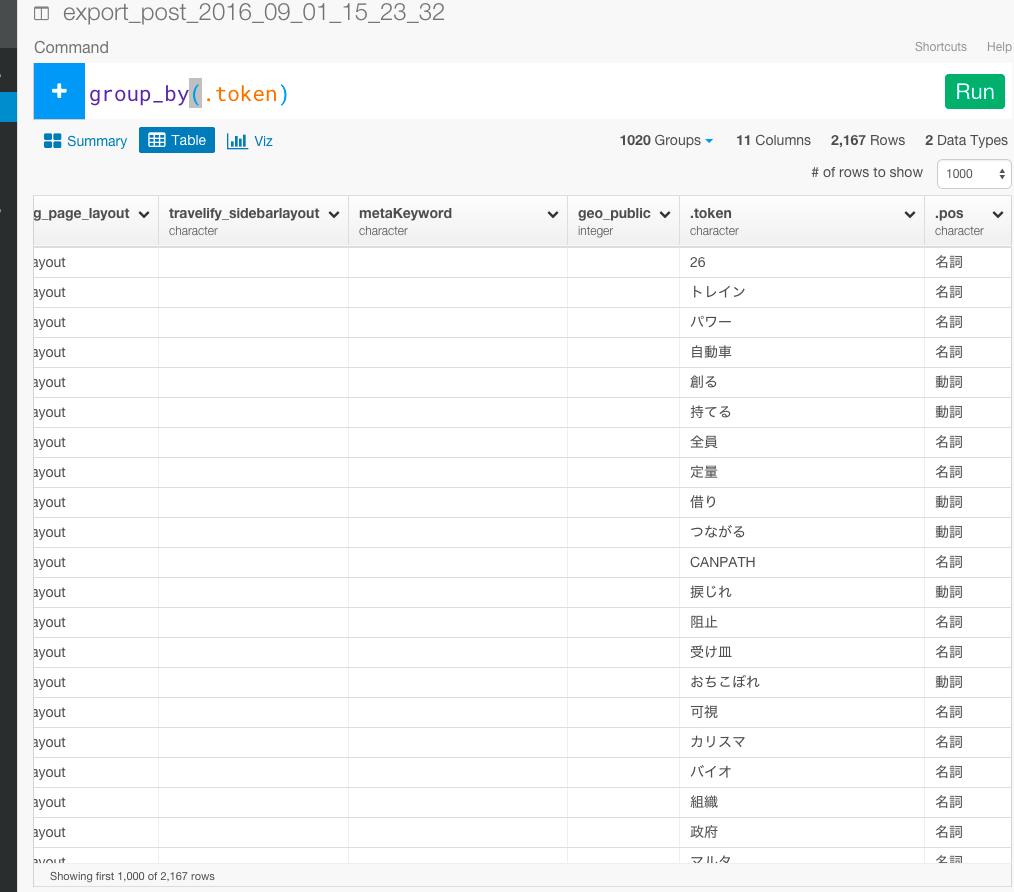
次に、.token列をsummarizeしてそれぞれの単語の個数を数えましょう。
summarize(.token_n = n())
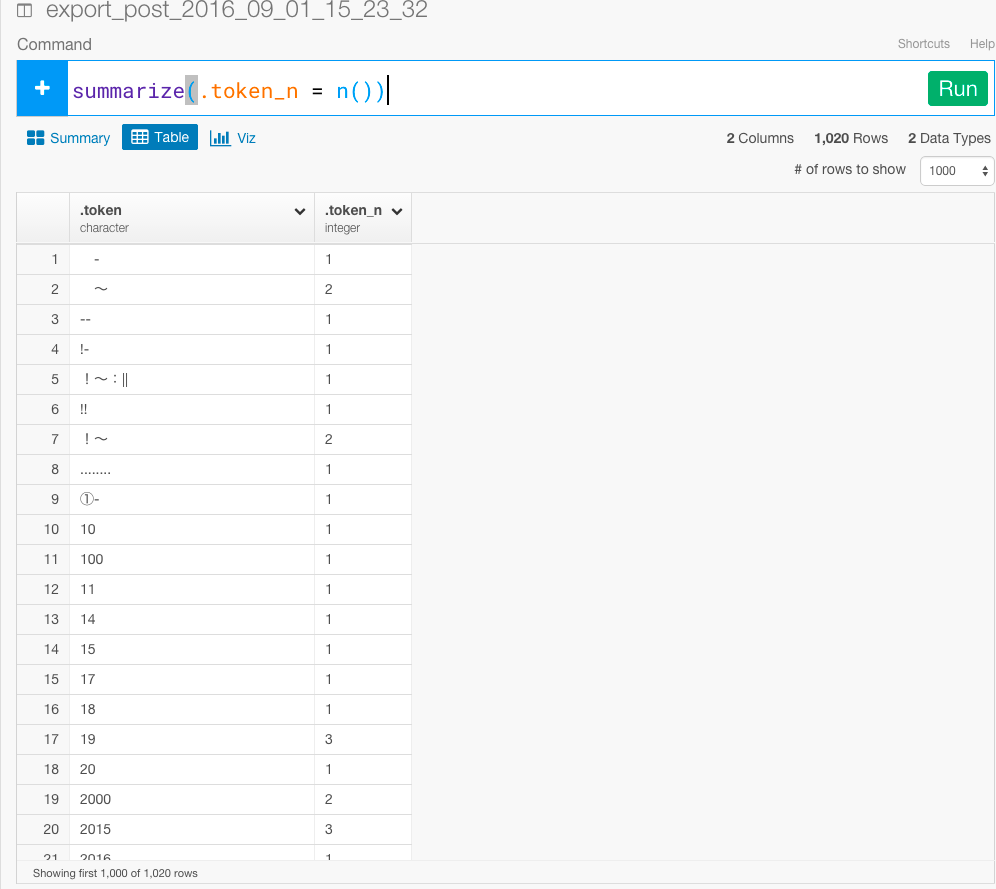
次に、top_n関数を使ってランキングを計算します。
.token_n列のヘッダーをクリックして、Top Nを選んで下さい。
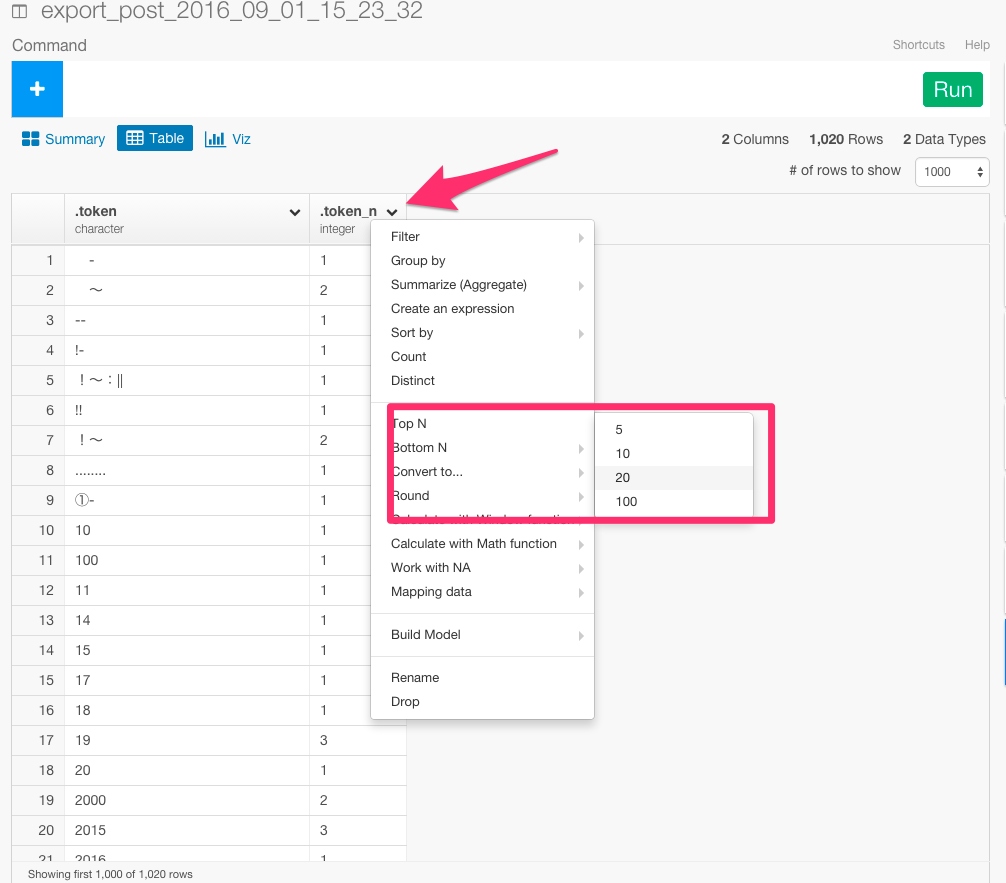
すると、コマンドが自動生成されます。Runボタンを押してください。
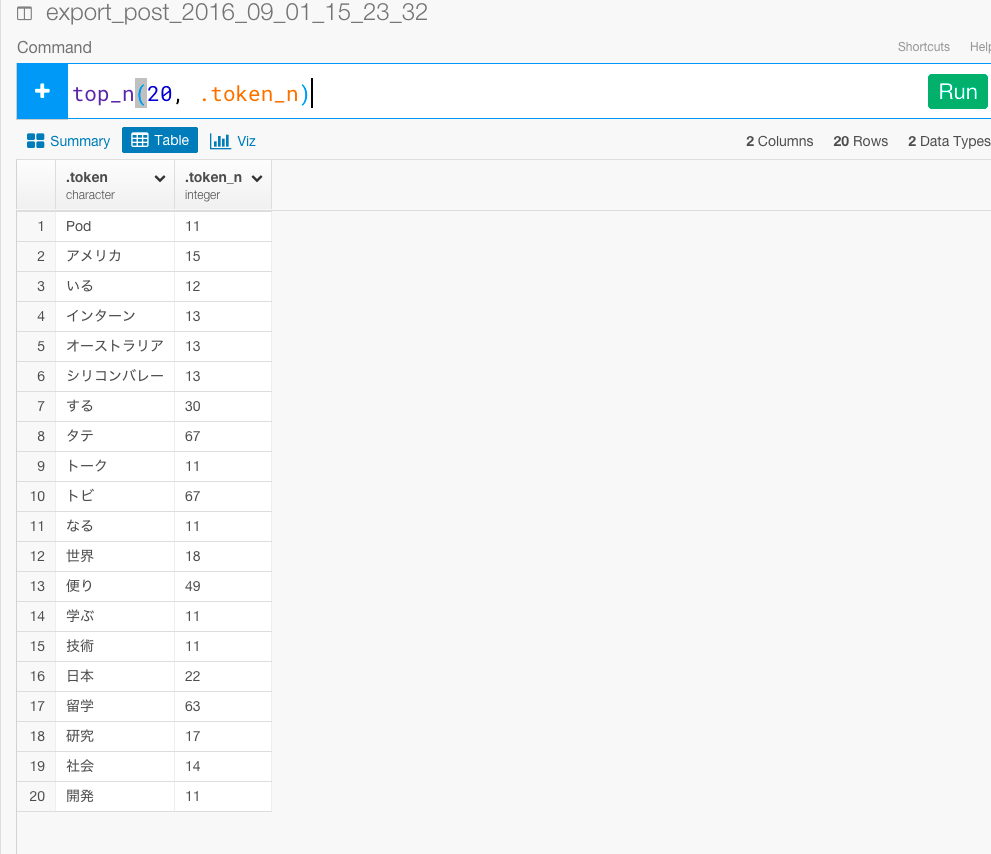
これで、最もよく頻出している意味のある単語トップ20を計算することができました。
ビジュアライズする
次に、データを直観的に理解するためにVizタブに行って、X軸に.tokenをY軸に.token_nをあてはめてビジュアライズしてみましょう。
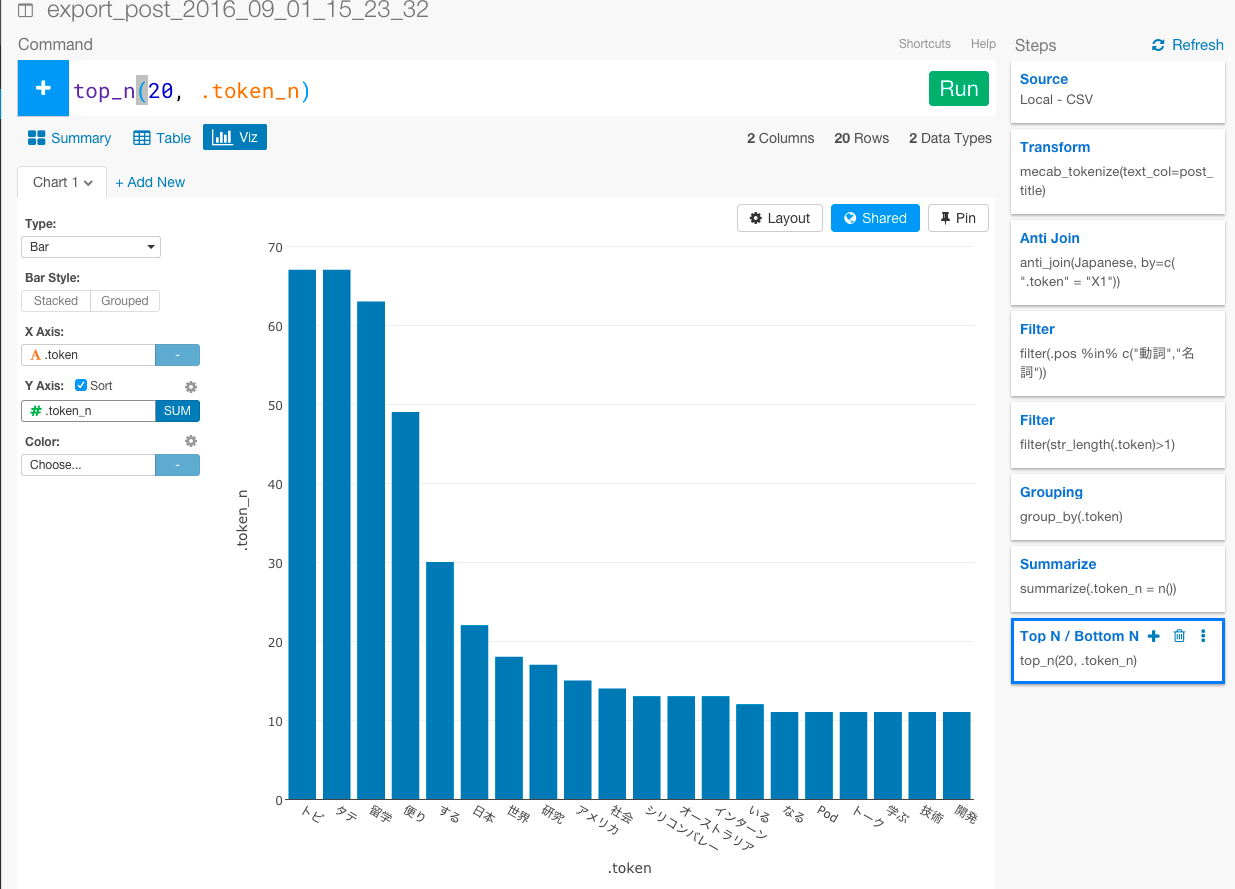
次回は、クラスタリングなどまでしてみたいと思います。
興味を持っていただいた方、実際に触ってみたい方へ
Exploratoryはこちらからβ版の登録ができます。こちらがinviteを完了すると、ダウンロードできるようになります。
ExploratoryのTwitterアカウントは、こちらです。
Exploratoryの日本ユーザー向けのFacebookグループを作ったのでよろしかったらどうぞ
分析してほしいデータがある方や、データ分析のご依頼はhidetaka.koh@gmail.comまでどうぞ